
貝葉斯估計(概率密度函式的估計的引數方法)
接上一篇文章:最大似估計
貝葉斯估計: 引數估計 
最大似然估計: 引數估計 

貝葉斯學習是把貝葉斯估計的原理應用於直接從資料對概率密度進行估計
開始我們今天的表演
一、貝葉斯估計
可以將概率密度函式引數估計問題看成是貝葉斯決策問題

貝葉斯決策問題有兩類:(1)輸入為離散變數:(用於分類)最優條件可以是最小錯誤率或者是最小風險
(2)輸入為連續變數


在使用損失函式為最小平方誤差損失函式的情況下,貝葉斯估計的步驟是:
(1)根據對問題的認識或者猜測確定

(2)樣本獨立同分布,且已知樣本密度形式
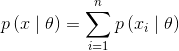
(3)利用貝葉斯公式求
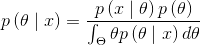
(4)求貝葉斯的估計量 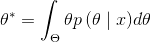
注:
我們本來的目的並不是要估計概率密度引數,而是估計樣本的概率密度函式

一般情況下,似然函式會在其極大值 

二、正態分佈的貝葉斯
為什麼選擇正態分佈?因為
注:對於給定的概率密度函式
公式。。。(好吧,我又懶了)
注:若遇到求積分不容易的情況,請查閱吉布斯取樣。
題外話:概率密度估計的非引數方法
最大似然方法和貝葉斯方法都屬於引數化的估計方法,要求待估計的概率密度函式形式已知,只是利用樣本來估計函式中的某些引數。但是,在很多情況下,我們對樣本的分佈並沒有充分的瞭解,無法事先給出密度函式的形式,而且有些樣本分佈的情況也很難用簡單的函式來描述。在這種情況下,就需要非引數估計,即不對概率度函式的形式作任何假設,而是直接用樣本估計出整個函式。當然,這種估計只能用數值方法取得,無法得到完美的封閉函式形式。從另外的角度來看,概率密度函式的引數估計實際是在指定的一類函式中選擇一個函式作為對未知函式的估計,而非引數估計則可以看作是從所有可能的函式中進行的一種選擇。
1、直方圖方法
2、k近鄰估計法
3、parzen窗法