
大資料初學者福利:Hive基本使用教程
蜂房資料型別
蜂房基礎資料型別
蜂巢是用的Java開發的,蜂巢的裡基本資料型別和Java的的基本資料型別也是一一對應的,除了字串型別有符號的整數型別:TINYINT,SMALLINT,INT和BIGINT分別等價於Java的位元組的,短型,整型和長原子型別,它們分別為1位元組,2位元組,4位元組和8位元組有符號整數.Hive的浮點資料型別FLOAT和DOUBLE,對應於的java的基本型別浮動和雙型別。而蜂房的布林型別相當於Java的的基本資料型別布林值。
蜂巢複雜資料型別
包括陣列,MAP,結構,聯合。這些複雜型別是由基礎型別組成的。
ARRAY:。ARRAY型別是由一系列同樣資料型別元素組成的,這些元素能夠通過下標來訪問比方有一個ARRAY型別的變數水果它是由[ '蘋果', '橙', '芒果']組成,那麼能夠通過水果[1]來訪問橙色。
MAP:。MAP包括鍵 - >值鍵值對能夠通過鍵來訪問元素比方使用者列表是一個對映型別(使用者名稱當中是key.password是值),那麼我們能夠通過使用者列表[使用者名稱]來得到這個使用者相應的密碼..
STRUCT:STRUCT能夠包括不同資料型別的元素這些元素能夠通過點的方式來得到,比方使用者是一個STRUCT型別,那麼能夠通過user.address得到這個使用者的地址。
蜂巢表型別
內部表
內部表也稱之為MANAGED_TABLE;預設儲存在/使用者/蜂巢/倉庫下,也可以通過位置指定;刪除表時,會刪除表資料以及元資料;
如果不存在則建立表...
外部表
外部表稱之為EXTERNAL_TABLE在建立表時可以自己指定目錄位置(LOCATION);刪除表時,只會刪除元資料不會刪除表資料;
如果不存在,建立EXTERNAL表...
載入資料
(1)HDFS上匯入資料到Hive表:
將路徑'/home/wyp/add.txt'中的資料載入到表wyp中;
(2)從本地路徑匯入資料到Hive表
將資料本地路徑'wyp.txt'載入到表wyp中;
(3)從別的表查詢載入到蜂巢表
靜態分割槽
插入表測試分割槽(age = '25')從wyp中選擇id,name,tel;
動態分割槽
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
insert overwrite table test PARTITION(age)從wyp中選擇id,name,tel,age;
插入表和插入覆蓋表的區別:後者會覆蓋相應資料目錄下的資料將。
建立相似表
create table table_name like other_table_name location“xxxxx”
查詢資料輸出到本地目錄
INSERT OVERWRITE DIRECTORY'/ tmp / hdfs_out'SELECT a。* FROM邀請WHERE a.ds ='“;
select by from emp deptno by empno asc;
cluster by =由和相分配。
Hive UDF程式設計
UDF實現
程式設計步驟:
1,繼承org.apache.hadoop.hive.ql.UDF
2,需要實現評估函式; 評價函式支援過載;
注意事項:
1,UDF必須要有返回型別,可以返回null,但是返回型別不能為void;
2,UDF中常用Text / LongWritable等型別,不推薦使用java型別;
官網演示:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
使用UDF非常簡單,只需要繼承org.apache.hadoop.hive.ql.exec.UDF,並定義public Object evaluate(Object args){}方法即可。
比如,下面的UDF函式實現了對一個字串型別的字串取HashMD5:
包com.lxw1234.hive.udf;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.util.MD5Hash;
import org.apache.hadoop.hive.ql.exec.UDF;
公共類HashMd5擴充套件UDF {
public String evaluate(String cookie){
return MD5Hash.getMD5AsHex(Bytes.toBytes(cookie));
}
}
將上面的HashMd5類打成JAR包,udf.jar
使用時候,在蜂巢命令列執行:
hive> add jar file:///tmp/udf.jar ;
hive>將臨時函式str_md5建立為'com.lxw1234.hive.udf.HashMd5';
hive>從dual中選擇str_md5('lxw1234.com');
轉變
蜂房中的變換:使用指令碼完成的Map / Reduce。
hive>新增檔案'python檔案路徑'
hive>新增檔案'python檔案路徑'
hive>選擇
TRANSFORM(p.joint_attr_values,p.collect_product_id,p.released_id)
使用'python split_product_attrs.py'
作為(custom_attr,custom_attr_value ,collect_product_id,released_product_id)
來自
(這裡應該是另外一個select語句,用於Transform的輸入,最好是一一對應的,否則會出錯)
下面是蟒的指令碼,用於將三列轉換為四列,這裡就比較簡單了,主要用於測試,程式碼隨便寫了一下
#!/ usr / bin / python
## _ * _ coding:utf-8 _ * _
import sys
import datetime
#“規格:RN1-10 / 50;規格:RN1-10 / 50;規格:RN1-10 / 50 “
#[”規格:RN1-10 / 51;規格:RN1-10 / 52;規格:RN1-10 / 53“,”11“,”22“]
#[”規格“,”RN1-10 / 51“ ,
'11 ','22'] #[“規格”,“RN1-10 / 52”,'11','22']
#[“規格”,“RN1-10 / 53”,'11',' 22']
for sys.stdin中的行:
values = line.split('\ t')
values = [i中的i的i.strip()]
tmp = values [0]
key_values = tmp.split(“;”)
對於key_values中的kv:
k = kv.split(“:”)[0]
v = kv.split(“:”)[1]
print'\ t'。join([k,v,values [1],values [2]])
蜂巢企業優化方案
蜂巢儲存格式
1,TEXTFILE預設格式,建表時不指定預設為這個格式,匯入資料時會直接把資料檔案拷貝到hdfs上不進行處理。只有TEXTFILE表能直接載入資料,本地載資料,和外部外部表直接載入運路徑資料,都只能用TEXTFILE表。更深一步,蜂房預設支援的壓縮檔案(hadoop的預設支援的壓縮格式),也只能用TEXTFILE表直接讀取。其他格式不行。可以通過TEXTFILE表載入後插入到其他表中。
2. orc格式。作為ORC儲存;
3.parquet格式。儲存為PARQUET;
幾種格式的差別http://www.cnblogs.com/juncaoit/p/6067646.html
蜂巢壓縮優化
壓縮配置:
map / reduce輸出壓縮(一般採用序列化檔案儲存)
設定hive.exec.compress.output = true;
set mapred.output.compression.codec = org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compression.type = BLOCK;
任務中間壓縮
set hive.exec.compress.intermediate = true;
set hive.intermediate.compression.codec = org.apache.hadoop.io.compress.SnappyCodec;(常用)
set hive.intermediate.compression.type = BLOCK;
中間壓縮
中間壓縮就是處理作業對映任務和減少任務之間的資料,對於中間壓縮,最好選擇一個節省CPU耗時的壓縮方式
<property>
<name> hive.exec.compress.intermediate </ name>
<value> true </ value>
</ property>
hadoop壓縮有一個預設的壓縮格式,當然可以通過修改mapred.map.output.compression.codec屬性,使用新的壓縮格式,這個變數可以在mapred-site.xml中設定或者在hive-site.xml檔案。 SnappyCodec是一個較好的壓縮格式,CPU消耗較低。
<property>
<name> mapred.map.output.compression.codec </ name>
<value> org.apache.hadoop.io.compress.SnappyCodec </ value>
</ property>
hive壓縮文件https://yq.aliyun.com/articles/60859
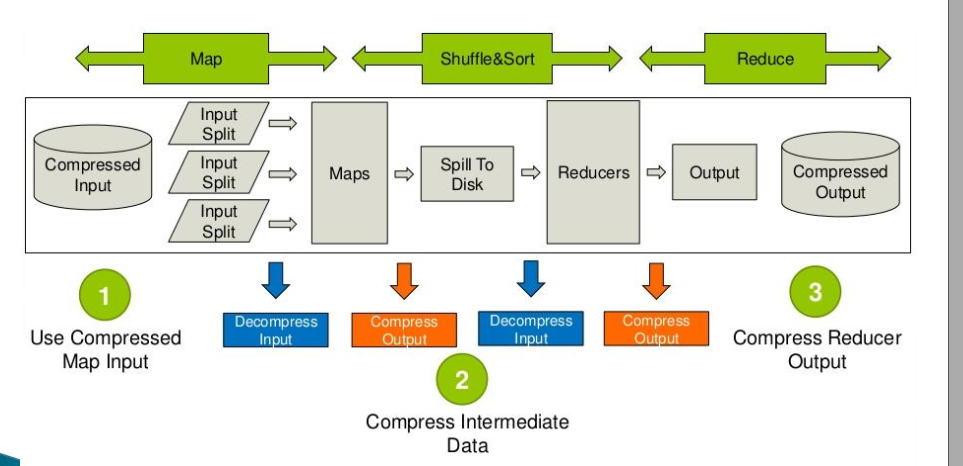
MapReduce的中使用壓縮

Hive中使用壓縮

Hive資料傾斜解決方案
小表join大表大表join大表方案
普通/隨機/減少加入
普通mapreduce join,相同鍵分配到同一個reducer。
地圖加入
MAPJION會把小表全部讀入記憶體中,在地圖階段直接拿另外一個表的資料和記憶體中表資料做匹配,適用於小表加入大表。
原來的SQL可以通過使用提示的方式指定加入時使用mapjoin
選擇/ * + mapjoin(t1)* / t1.a,t1.b從表t1加入table2 t2 on(t1.a = t2.a和f.ftime = 20110802)
Map加入Java實現
http://www.cnblogs.com/ivanny/p/mapreduce_join.html
SMB加入(排序合併桶加入)
分割槽,桶,排序合併桶加入https://my.oschina.net/leejun2005/blog/178631
使用SMB加入需要如下配置
set hive.auto.convert.sortmerge.join = true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
結語
為了幫助大家讓學習變得輕鬆、高效,給大家免費分享一大批資料,幫助大家在成為大資料工程師,乃至架構師的路上披荊斬棘。在這裡給大家推薦一個大資料學習交流圈:
658558542
歡迎大家進群交流討論,學習交流,共同進步。
當真正開始學習的時候難免不知道從哪入手,導致效率低下影響繼續學習的信心。
但最重要的是不知道哪些技術需要重點掌握,學習時頻繁踩坑,最終浪費大量時間,所以有有效資源還是很有必要的。
最後祝福所有遇到瓶疾且不知道怎麼辦的大資料程式設計師們,祝福大家在往後的工作與面試中一切順利。