
基於深度學習的影象去噪暨SRMD論文閱讀筆記
最近一直在做基於卷積神經網路的影象去噪~感覺資料比較凌亂,本博文就是整理好經典的論文材料~
同時本博文也結合了閱讀論文《Learning a Single Convolutional Super-Resolution Network for Multiple Degradations》時的心得體會
目錄
Dimensionality Stretching(維度拉伸)
Background
DnCNN
使用了Batch Normalization和Residual Learning加速訓練過程和提升去噪效能。網路的結構圖如下:

FFDNet
側重與去除更加複雜的高斯噪聲。主要是不同的噪聲水平。之前的基於卷積神經網路的去噪演算法,大多數都是針對於某一種特定噪聲的,為了解決不同噪聲水平的問題,FFDNet的作者利用noise level map作為輸入,使得網路可以適用於不同噪聲水平的圖片

CBDNet
網路由噪聲估計子網路和去噪子網路兩部分組成。同時進行end to end的訓練。並採用基於訊號獨立的噪聲以及相機內部處理的噪聲合成的圖片和真是的噪聲圖片(所謂“真實”的噪聲圖片是來自於別人的資料集RENOIR、DND、NC12等,)聯合訓練。提高去噪網路的泛化能力,也增強去噪的效果

SRMD
近年來,深度卷積神經網路(CNN)方法在單幅影象超解析度(SISR)領域取得了非常大的進展。然而現有基於CNN的SISR方法主要假設低解析度(LR)影象由高解析度(HR)影象經過雙三次(bicubic)降取樣得到,因此當真實影象的退化過程不遵循該假設時,其超分辨結果會非常差。此外,現有的方法不能擴充套件到用單一模型解決多種不同的影象退化型別。
SISR方法主要分為三類:基於插值的方法、基於模型的方法以及基於判別學習的方法。
基於插值的方法(例如:最近鄰插值、雙三次插值)雖然速度快,但是其效果比較差。
基於模型的方法通過引入影象先驗,例如:非區域性相似性先驗、去噪先驗等,然後求解目標函式得到視覺質量較好的HR影象,然而速度較慢。雖然結合基於CNN的去噪先驗可以在某種程度上提升速度,但仍然受限於一些弊端,例如:無法進行端對端的訓練,包含一些比較難調的引數等。
基於判別學習的方法尤其是基於CNN的方法因其速度快、可以端對端的學習因而效果好等在近幾年受到了廣泛關注,並且逐漸成為解決SISR的主流方法(如之前博文《 學習筆記之——基於深度學習的影象超解析度重構》介紹的系列方法)。
然而這些方法都存在一個共同缺點,也就是它們只考慮雙三次(bicubic)降取樣退化模型並且不能靈活地將其模型擴充套件到同時(非盲)處理其它退化型別。由於真實影象的退化過程多種多樣,因而此類方法的有效實際應用場景非常有限。
一些SISR工作已經指出影象退化過程中的模糊核的準確性對SISR起著至關重要的作用,然而並沒有基於CNN的相關工作將模糊核等因素考慮在內。為此引出本文主要解決的問題:是否可以設計一個非盲超解析度(non-blind SISR)模型用以解決不同的影象退化型別?
因此,SRMD的作者通過提出類似於FFDNet的思想,將degradation model中的兩個關鍵因素(模糊核和噪聲水平)跟LR一起作為網路的輸入。以此提高網路的泛化能力。注意這裡所說的泛化能力,是指網路用於真實的圖片上,這真實的圖片上具有不同的且不均與的退化型別。而由於模糊核和噪聲水平需要跟LR匹配才可以作為網路的輸入,為此作者提出了一種維度拉伸的策略,使得其拉伸到跟LR大小一致
LR影象y對應的HR影象x可以通過求解下述問題近似:
![]()
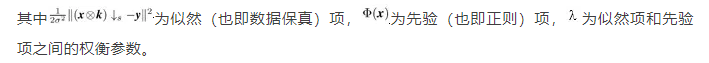
簡單來說,上述公式包含兩點:
-
估計得到的HR影象不僅要符合SISR的退化過程,並且還要滿足清晰影象所具有的先驗特徵;
-
對於非盲超解析度問題,x的求解與LR影象y、模糊核k、噪聲水平
以及權衡引數
有關。
為此,作者得到以下結論:
-
由於資料保真項(似然項)
 對應著SISR的退化過程,因此退化過程的準確建模對SISR的結果起著至關重要的作用。然而現有的基於CNN的方法其目標是求解下面的問題:
對應著SISR的退化過程,因此退化過程的準確建模對SISR的結果起著至關重要的作用。然而現有的基於CNN的方法其目標是求解下面的問題: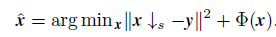 。由於沒有將模糊核和噪聲等因素考慮在內,因此其實用性非常有限。
。由於沒有將模糊核和噪聲等因素考慮在內,因此其實用性非常有限。 -
為了設計更加有效的基於CNN的SISR模型,應該將更多的影象退化型別考慮在內,一個簡單的思路就是將模糊核k和噪聲水平
![]()
- 由於MAP估計中大部分的引數都對應著影象先驗部分,而影象先驗是與影象退化過程不相關的,因此單一的CNN模型具有處理不同退化型別的建模能力,需要把退化過程也輸入到網路中,讓網路學習。
通過上述分析可以得出非盲SISR應該將退化模型中的模糊核和噪聲水平也作為網路的輸入。然而LR影象、模糊核和噪聲水平三者的維度是不同的,因此不能直接作為CNN的輸入。
Theory
圖片的噪聲模型
為了讓模型能應用於現實的噪聲影象的去噪。Realistic LR Degradation模型的設定非常重要。將訊號獨立噪聲以及相機內部處理噪聲都考慮在內,提出了一個更加真實的噪聲模型,並讓去噪表現有了大幅提高。實際上,就是通過一個更加接近真實的退化引數模型來成pair的去訓練一個非盲的網路,使得這個非盲的網路可以適用於blind denoise。
而不僅僅是通過更加接近真實的degradation model,還需要把degradation parameter也一併輸入網路裡面,提高網路的Generalization ability
真實影象的噪聲分佈遠遠不同於高斯噪聲,它們更加複雜,並且訊號是獨立的。因此,可以給定模型如下:
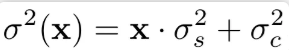
這裡![]() ,由訊號獨立的噪聲部分(signal-dependent noise)
,由訊號獨立的噪聲部分(signal-dependent noise)![]() 和靜態噪聲部分(stationary noise)
和靜態噪聲部分(stationary noise)![]() 組成.
組成.![]() 的方差為
的方差為![]() 的高斯白噪聲,針對每個畫素。而
的高斯白噪聲,針對每個畫素。而![]() 的噪聲方差和影象強度相關,也就是
的噪聲方差和影象強度相關,也就是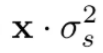 注意,此處的x不是clean image應該是L,即clean image的irradiance。
注意,此處的x不是clean image應該是L,即clean image的irradiance。
至於相機內部的處理過程,CBDNet的作者提出了下面這個訊號獨立和通道獨立的噪聲模型:
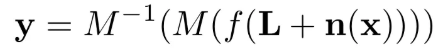

退化引數模型
degradation moel可以表述如下

當然,也可以換種形式,表述如下

如果加上JPEG,那麼將是

Dimensionality Stretching(維度拉伸)
假設LR影象大小為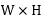
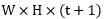

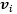

至此。其實概念是十分清晰的。但是唯一不懂的是如何實現拉伸的過程。。。。幸虧作者有給出程式碼,接下來找一下程式碼裡面有沒有對這個過程的描述
維度拉伸的實現細節
如果是spatially uniform的blur和noise,那這個stretch就是一個repeat的操作,即每一個空間位置的t+1個元素都是相同的。
如果是spatially variant,則需要一個函式,表示每個pixel的噪聲~
補充關於FFDNet中的noise level map,將原始碼改寫如下:
% noise level map
[~,~,noiseSigma] = peaks(size(label,1));%peaks,其實就是一個spatially variant的函式
noiseSigma = 0 + (50 - 0).*(noiseSigma - min(noiseSigma(:)))./(max(noiseSigma(:)) - min(noiseSigma(:)));%把noiseSigma限制在[0, 50]之間,是一個線性的歸一化操作
noiseSigma = flipud(noiseSigma);%做翻轉的操作
sigmas = imresize(noiseSigma,1/2,'bicubic')/255;原始碼連結(論文閱讀筆記——《FFDNet Toward a Fast and Flexible Solution for CNN based Image Denoising》)
noise level map的結果



SRMD網路結構
可以將退化圖和LR影象合併在一起作為CNN的輸入。為了證明此策略的有效性,選取了快速有效的ESPCN超分辨網路結構框架。值得注意的是為了加速訓練過程的收斂速度,同時考慮到LR影象中包含高斯噪聲,因此網路中加入了Batch Normalization層。網路結構如下圖所示。

在訓練階段,SRMD採用了各向同性和各向異性的高斯模糊核、噪聲水平在[0, 75]之間的高斯白噪聲以及 bicubic降取樣運算元。需要指出的是SRMD可以擴充套件到其它降取樣運算元,甚至其它退化模型。
Reference
https://github.com/cszn/SRMD(SRMD論文的程式碼)
http://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_SRMD.pdf(SRMD論文)
https://github.com/2wins/SRMD-pytorch(SRMD的pytorch實現版本)