
最大似然估計(Maximum likelihood estimation)(通過例子理解)
似然與概率
https://blog.csdn.net/u014182497/article/details/82252456
在統計學中,似然函數(likelihood function,通常簡寫為likelihood,似然)是一個非常重要的內容,在非正式場合似然和概率(Probability)幾乎是一對同義詞,但是在統計學中似然和概率卻是兩個不同的概念。概率是在特定環境下某件事情發生的可能性,也就是結果沒有產生之前依據環境所對應的參數來預測某件事情發生的可能性,比如拋硬幣,拋之前我們不知道最後是哪一面朝上,但是根據硬幣的性質我們可以推測任何一面朝上的可能性均為50%,這個概率只有在拋硬幣之前才是有意義的,拋完硬幣後的結果便是確定的;而似然剛好相反,是在確定的結果下去推測產生這個結果的可能環境(參數),還是拋硬幣的例子,假設我們隨機拋擲一枚硬幣1,000次,結果500次人頭朝上,500次數字朝上(實際情況一般不會這麽理想,這裏只是舉個例子),我們很容易判斷這是一枚標準的硬幣,兩面朝上的概率均為50%,這個過程就是我們根據結果來判斷這個事情本身的性質(參數),也就是似然。
結果和參數相互對應的時候,似然和概率在數值上是相等的,如果用 θ 表示環境對應的參數,x 表示結果,那麽概率可以表示為:
P(x|θ)
P(x|θ)
是條件概率的表示方法,θ是前置條件,理解為在θ 的前提下,事件 x 發生的概率,相對應的似然可以表示為:
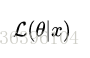
理解為已知結果為 x ,參數為θ (似然函數裏θ 是變量,這裏## 標題 ##說的參數是相對與概率而言的)對應的概率,即:
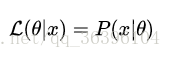
需要說明的是兩者在數值上相等,但是意義並不相同,
舉個例子
以伯努利分布(Bernoulli distribution,又叫做兩點分布或0-1分布)為例:
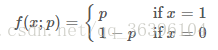
也可以寫成以下形式:
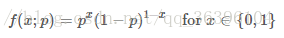
這裏註意區分 f(x;p)f(x;p) 與前面的條件概率的區別,引號後的 pp 僅表示 ff 依賴於 pp 的值,pp 並不是 ff 的前置條件,而只是這個概率分布的一個參數而已,也可以省略引號後的內容:
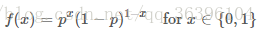
對於任意的參數 pp 我們都可以畫出伯努利分布的概率圖,當 p=0.5p=0.5 時:
f(x)=0.5
- 1
- 2
我們可以得到下面的概率密度圖:
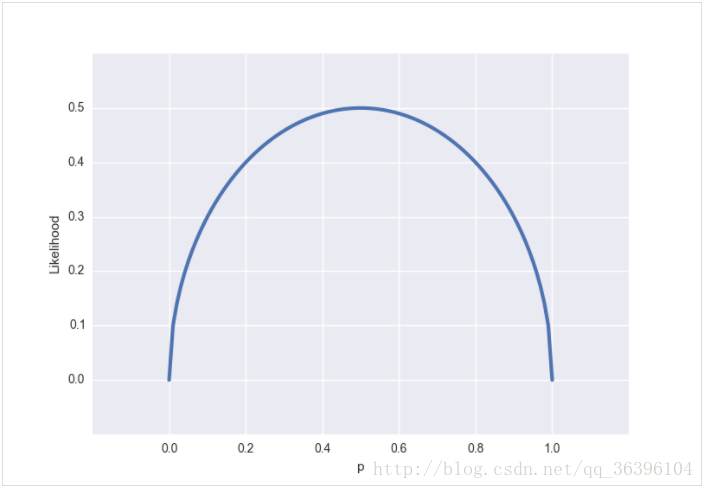
從似然的角度出發,假設我們觀測到的結果是 x=0.5x=0.5(即某一面朝上的概率是50%,這個結果可能是通過幾千次幾萬次的試驗得到的,總之我們現在知道這個結論),可以得到以下的似然函數:
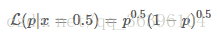
對應的圖是這樣的:
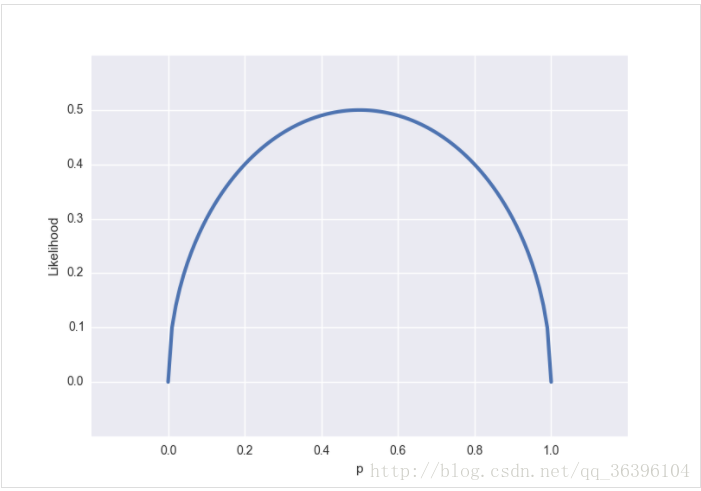
與概率分布圖不同的是,似然函數是一個(0, 1)內連續的函數,所以得到的圖也是連續的,我們很容易看出似然函數的極值(也是最大值)在 p=0.5p=0.5 處得到,通常不需要做圖來觀察極值,令似然函數的偏導數為零即可求得極值條件。
ps. 似然函數裏的 pp 描述的是硬幣的性質而非事件發生的概率(比如 p=0.5p=0.5 描述的是一枚兩面均勻的硬幣)。為了避免混淆,可以用其他字母來表示這個性質,如果我們用 ππ 來表示,那麽似然函數就可以寫成:

似然函數的最大值
似然函數的最大值意味著什麽?讓我們回到概率和似然的定義,概率描述的是在一定條件下某個事件發生的可能性,概率越大說明這件事情越可能會發生;而似然描述的是結果已知的情況下,該事件在不同條件下發生的可能性,似然函數的值越大說明該事件在對應的條件下發生的可能性越大。
現在再來看看之前提到的拋硬幣的例子:
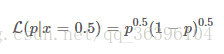
上面的 pp (硬幣的性質)就是我們說的事件發生的條件,LL 描述的是性質不同的硬幣,任意一面向上概率為50% 的可能性有多大,是不是有點繞?讓我們來定義 A:
A=事件的結果=任意一面向上概率為50%
那麽 LL 描述的是性質不同的硬幣,A 事件的可能性有多大,這麽一說是不是清楚多了?
在很多實際問題中,比如機器學習領域,我們更關註的是似然函數的最大值,我們需要根據已知事件來找出產生這種結果最有可能的條件,目的當然是根據這個最有可能的條件去推測未知事件的概率。在這個拋硬幣的事件中,pp 可以取 [0, 1] 內的所有值,這是由硬幣的性質所決定的,顯而易見的是 p=0.5p=0.5 這種硬幣最有可能產生我們觀測到的結果。
對數化的似然函數
實際問題往往要比拋一次硬幣復雜得多,會涉及到多個獨立事件,在似然函數的表達式中通常都會出現連乘:
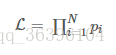
對多項乘積的求導往往非常復雜,但是對於多項求和的求導卻要簡單的多,對數函數不改變原函數的單調性和極值位置,而且根據對數函數的性質可以將乘積轉換為加減式,這可以大大簡化求導的過程:
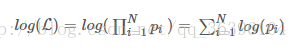
在機器學習的公式推導中,經常能看到類似的轉化。
看到這應該不會再那麽迷糊了吧~最後再來個例子:
舉個別人博客中的例子,假如有一個罐子,裏面有黑白兩種顏色的球,數目多少不知,兩種顏色的比例也不知。我 們想知道罐中白球和黑球的比例,但我們不能把罐中的球全部拿出來數。現在我們可以每次任意從已經搖勻的罐中拿一個球出來,記錄球的顏色,然後把拿出來的球 再放回罐中。這個過程可以重復,我們可以用記錄的球的顏色來估計罐中黑白球的比例。假如在前面的一百次重復記錄中,有七十次是白球,請問罐中白球所占的比例最有可能是多少?很多人馬上就有答案了:70%。而其後的理論支撐是什麽呢?
我們假設罐中白球的比例是p,那麽黑球的比例就是1-p。因為每抽一個球出來,在記錄顏色之後,我們把抽出的球放回了罐中並搖勻,所以每次抽出來的球的顏 色服從同一獨立分布。這裏我們把一次抽出來球的顏色稱為一次抽樣。題目中在一百次抽樣中,七十次是白球的概率是P(Data | M),這裏Data是所有的數據,M是所給出的模型,表示每次抽出來的球是白色的概率為p。如果第一抽樣的結果記為x1,第二抽樣的結果記為x2... 那麽Data = (x1,x2,…,x100)。這樣,
- 1
- 2
P(Data | M)
= P(x1,x2,…,x100|M)
= P(x1|M)P(x2|M)…P(x100|M)
= p^70(1-p)^30.
那麽p在取什麽值的時候,P(Data |M)的值最大呢?將p^70(1-p)^30對p求導,並其等於零。
70p^69(1-p)^30-p^70*30(1-p)^29=0。
解方程可以得到p=0.7。
在邊界點p=0,1,P(Data|M)=0。所以當p=0.7時,P(Data|M)的值最大。這和我們常識中按抽樣中的比例來計算的結果是一樣的。
假如我們有一組連續變量的采樣值(x1,x2,…,xn),我們知道這組數據服從正態分布,標準差已知。請問這個正態分布的期望值為多少時,產生這個已有數據的概率最大?
P(Data | M) = ?
根據公式

由上可知最大似然估計的一般求解過程:
(1) 寫出似然函數;
(2) 對似然函數取對數,並整理;
(3) 求導數 ;
(4) 解似然方程
最大似然估計(Maximum likelihood estimation)(通過例子理解)