
見識一下尾遞迴的強大!尾遞迴怎麼會比迭代還快!這不科學
1.效能測試
尾遞迴求Fibonaci數列,三種方法分別是:
(1)普通遞迴
(2)尾遞迴
(3)動態規劃
第一種重複計算很多,其他兩種都能避免重複計算
程式碼:
#include <iostream> #include <sys/time.h> //#include <boost/xpressive/xpressive.hpp> using namespace std; //using namespace boost; //using namespace boost::xpressive; int const N=30; int const TIMES=1000; //普通遞迴 int fib_r(int n) { if(n<=1)return 1; return fib_r(n-1)+fib_r(n-2); } //尾遞迴 int fib_rw(int a, int b, int n) { if(n<=1)return b; return fib_rw(b, a+b, n-1); } //動態規劃 int fib_dp(int n) { int re; int *p=new int[n+1]; int i; p[0]=p[1]=1; for(i=2;i<=n;i++) p[i]=p[i-1] + p[i-2]; re=p[n]; delete []p; return re; } ////// main int main() { struct timeval begin,end; int re; //////////////////////// gettimeofday(&begin,0); //尾遞迴 { int i=TIMES; while(--i) { re=fib_rw(1,1,N); } } gettimeofday(&end,0); if(begin.tv_usec>end.tv_usec) { end.tv_sec--; end.tv_usec+=1000000; } cout<<"尾遞迴 "<<re<<" time: "<<end.tv_sec - begin.tv_sec<<" s "<<end.tv_usec - begin.tv_usec<<" us"<<endl; //////////////////////// gettimeofday(&begin,0); //遞迴 { int i=TIMES; while(--i) { re=fib_r(N); } } gettimeofday(&end,0); if(begin.tv_usec>end.tv_usec) { end.tv_sec--; end.tv_usec+=1000000; } cout<<"遞迴 "<<re<<" time: "<<end.tv_sec - begin.tv_sec<<" s "<<end.tv_usec - begin.tv_usec<<" us"<<endl; //////////////////////// gettimeofday(&begin,0); //動規 { int i=TIMES; while(--i) { re=fib_dp(N); } } gettimeofday(&end,0); if(begin.tv_usec>end.tv_usec) { end.tv_sec--; end.tv_usec+=1000000; } cout<<"動規 "<<re<<" time: "<<end.tv_sec - begin.tv_sec<<" s "<<end.tv_usec - begin.tv_usec<<" us"<<endl; return 0; }
執行一下,計算第30個元素:
[email protected]:~$ g++ a.cpp -o a
[email protected]:~$ ./a
尾遞迴 1346269 time: 0 s 271 us
遞迴 1346269 time: 23 s 961794 us
動規 1346269 time: 0 s 424 us
尾遞迴和動規的曲線:
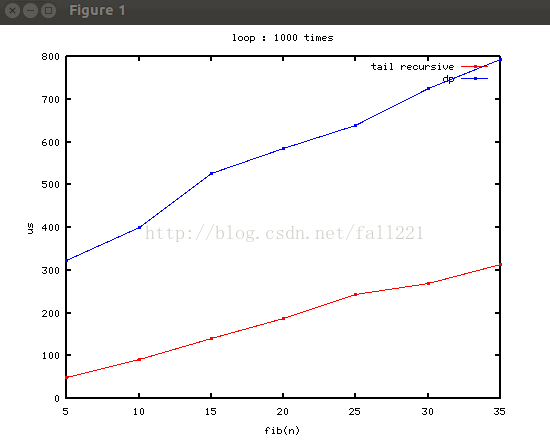
可見,這兩個是線性增長~下面的是尾遞迴的。
普通遞迴的曲線:
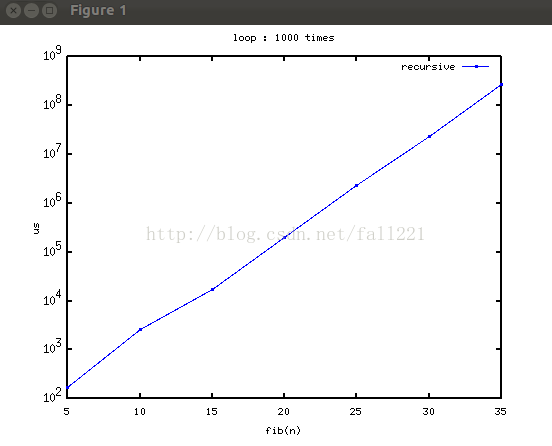
看到是直的,有沒有覺得很高興?可惜。。縱座標是對數座標!標準的指數式增長。。。過了20以後簡直要等半天啊。
那麼,動規為什麼比尾遞迴慢?把new/delete換成靜態陣列:
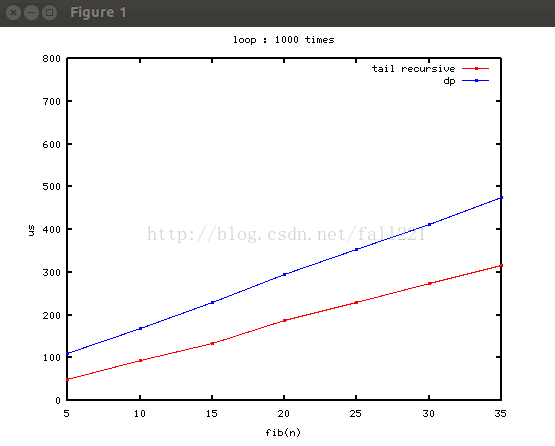
將陣列宣告為全域性:
#include <iostream> #include <sys/time.h> #include <stdlib.h> //#include <boost/xpressive/xpressive.hpp> using namespace std; //using namespace boost; //using namespace boost::xpressive; int const N=20; int const TIMES=1000; int p[50]={1,1,}; //普通遞迴 int fib_r(int n) { if(n<=1)return 1; return fib_r(n-1)+fib_r(n-2); } //尾遞迴 int fib_rw(int a, int b, int n) { if(n<=1)return b; return fib_rw(b, a+b, n-1); } //動態規劃 int fib_dp(int n) { p[0]=p[1]=1; int i; for(i=2;i<=n;i++) p[i]=p[i-1] + p[i-2]; return p[n]; } ////// main int main(int argc, char*argv[]) { int N=20; if(argc>=2) N=atoi(argv[1]); struct timeval begin,end; int re; //////////////////////// gettimeofday(&begin,0); //尾遞迴 { int i=TIMES; while(--i) { re=fib_rw(1,1,N); } } gettimeofday(&end,0); if(begin.tv_usec>end.tv_usec) { end.tv_sec--; end.tv_usec+=1000000; } cout<<"尾遞迴 "<<re<<" time: "<<end.tv_sec - begin.tv_sec<<" s "<<end.tv_usec - begin.tv_usec<<" us"<<endl; /* //////////////////////// gettimeofday(&begin,0); //遞迴 { int i=TIMES; while(--i) { re=fib_r(N); } } gettimeofday(&end,0); if(begin.tv_usec>end.tv_usec) { end.tv_sec--; end.tv_usec+=1000000; } cout<<"遞迴 "<<re<<" time: "<<end.tv_sec - begin.tv_sec<<" s "<<end.tv_usec - begin.tv_usec<<" us"<<endl; */ //////////////////////// gettimeofday(&begin,0); //動規 { int i=TIMES; while(--i) { re=fib_dp(N); } } gettimeofday(&end,0); if(begin.tv_usec>end.tv_usec) { end.tv_sec--; end.tv_usec+=1000000; } cout<<"動規 "<<re<<" time: "<<end.tv_sec - begin.tv_sec<<" s "<<end.tv_usec - begin.tv_usec<<" us"<<endl; return 0; }
編譯執行:
[email protected]:~$ g++ a.cpp -o a
[email protected]:~$ ./a 30
尾遞迴 1346269 time: 0 s 285 us
動規 1346269 time: 0 s 232 us
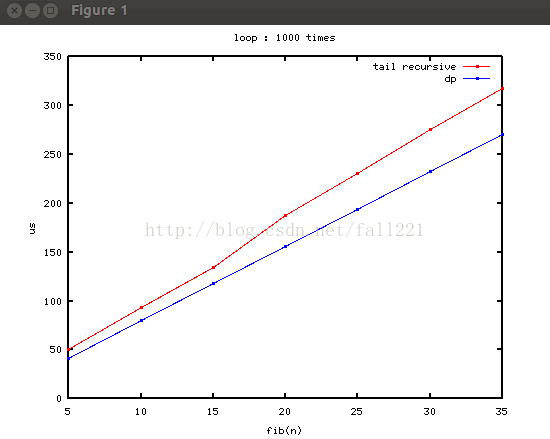
線性性那是槓槓的!這回正常了,動規的迭代比尾遞迴稍快一點點,但是不多。看來,區域性變數的定義也是需要時間的。。。
PS:當然,所謂的動規。。其實是不必要的,完全可以寫為:
int fib_dp(int n)
{
int a=1;
int b=1;
int i;
for(i=2;i<=n;i++)
{
b=a+b;
a=b-a;
}
return b;
}
對於沒有引進中間變數這件事。。我表示乾的很漂亮!。。。當然,本來迴圈中需要執行一次計算,現在變成兩次,時間會上漲那麼一點點。。。不過這樣空間複雜度就下來了。
2.彙編分析
接下來,要做的事情是。。。分析彙編!
1.先是尾遞迴的:
(gdb) disas fib_rw
Dump of assembler code for function fib_rw(int, int, int):
0x0804871e <+0>: push ebp
0x0804871f <+1>: mov ebp,esp
0x08048721 <+3>: sub esp,0x18
0x08048724 <+6>: cmp DWORD PTR [ebp+0x10],0x1 n和1比較
0x08048728 <+10>: jg 0x804872f <fib_rw(int, int, int)+17> 大於1的話,就jmp到下下下行--->
0x0804872a <+12>: mov eax,DWORD PTR [ebp+0xc] 返回b:eax=b
0x0804872d <+15>: jmp 0x8048750 <fib_rw(int, int, int)+50> 跳到leave那裡
0x0804872f <+17>: mov eax,DWORD PTR [ebp+0x10] --> jmp到這裡。n賦值給eax
0x08048732 <+20>: lea edx,[eax-0x1] edx=eax-1
0x08048735 <+23>: mov eax,DWORD PTR [ebp+0xc] eax=b
0x08048738 <+26>: mov ecx,DWORD PTR [ebp+0x8] ecx=a
0x0804873b <+29>: add eax,ecx eax=eax+ecx
0x0804873d <+31>: mov DWORD PTR [esp+0x8],edx esp+8 <-- edx n-1
0x08048741 <+35>: mov DWORD PTR [esp+0x4],eax esp+4 <--a+b
0x08048745 <+39>: mov eax,DWORD PTR [ebp+0xc] eax <-- b
0x08048748 <+42>: mov DWORD PTR [esp],eax
0x0804874b <+45>: call 0x804871e <fib_rw(int, int, int)> 遞迴呼叫
0x08048750 <+50>: leave
0x08048751 <+51>: ret
End of assembler dump.
int fib_rw(int a, int b, int n)
{
if(n<=1)return b;
return fib_rw(b, a+b, n-1);
}
由於引數是 int fib_rw(int a, int b, int n),所以呼叫的時候:
n入棧 ebp+10
b入棧 ebp+c
a入棧 ebp+8
call的時候,eip入棧 ebp+4
push ebp的時候,ebp入棧,<-----隨後,ebp指向這裡。所以,[ebp+0x10]指向的是n。從彙編程式碼來看,每一次呼叫,棧幀都會sub 0x18,就是二十幾個位元組。
2.是迭代的
(gdb) disas fib_dp
Dump of assembler code for function fib_dp(int):
0x08048752 <+0>: push ebp
0x08048753 <+1>: mov ebp,esp
0x08048755 <+3>: sub esp,0x10
0x08048758 <+6>: mov DWORD PTR [ebp-0xc],0x1 a
0x0804875f <+13>: mov DWORD PTR [ebp-0x8],0x1 b
0x08048766 <+20>: mov DWORD PTR [ebp-0x4],0x2 i
0x0804876d <+27>: jmp 0x8048788 <fib_dp(int)+54> -->jmp to
0x0804876f <+29>: mov eax,DWORD PTR [ebp-0xc] eax=a -->here
0x08048772 <+32>: add DWORD PTR [ebp-0x8],eax b+=eax b+=a
0x08048775 <+35>: mov eax,DWORD PTR [ebp-0xc] eax=a
0x08048778 <+38>: mov edx,DWORD PTR [ebp-0x8] edx=b
0x0804877b <+41>: mov ecx,edx exc=edx
0x0804877d <+43>: sub ecx,eax ecx - = eax
0x0804877f <+45>: mov eax,ecx eax=ecx
0x08048781 <+47>: mov DWORD PTR [ebp-0xc],eax a=eax
0x08048784 <+50>: add DWORD PTR [ebp-0x4],0x1 i++
0x08048788 <+54>: mov eax,DWORD PTR [ebp-0x4] -->here
0x0804878b <+57>: cmp eax,DWORD PTR [ebp+0x8] ebp+8是輸入的n
0x0804878e <+60>: setle al setle是小於等於的比較
0x08048791 <+63>: test al,al
0x08048793 <+65>: jne 0x804876f <fib_dp(int)+29> -->jmp
0x08048795 <+67>: mov eax,DWORD PTR [ebp-0x8]
---Type <return> to continue, or q <return> to quit---
0x08048798 <+70>: leave
0x08048799 <+71>: ret
End of assembler dump.
sub esp,0x10:只用了這麼點空間。記憶體是:
ebp
i=2 ebp-0x4
b=1 ebp-0x8
a=1 ebp-0xc
反正,棧幀是沒有發生生長。尾遞迴比起來,還是具有O(n)的空間複雜度的。迭代則可以避免(如果不用陣列的話)