
Spark DataFrame 與Pandas DataFrame差異
為何使用pyspark dataframe
使用pandas進行資料處理,dataframe常作為主力軍出現。基於單機操作的pandas dataframe是一種表格形資料結構,擁有豐富、靈活、操作簡單的api,在資料量不大的情況下有較好的效果。
對於大資料量的運算,分散式計算能突破pandas的瓶頸,而Spark則是分散式計算的典型代表。 Spark中有三類資料api,RDD、DataFrame和Datasets(支援多種主流語言操作),在spark2.0中出現Datasets的概念,其中DataFrame也稱Datasets[row],python中只有DataFrame的概念。
DataFrame是基於RDD的一種資料型別,具有比RDD節省空間和更高運算效率的優點,對於使用python操作spark且熟悉pandas基本操作的工作者是一個好訊息。
pandas dataframe資料結構特性
DataFrame是一種表格型資料結構,按照列結構儲存,它含有一組有序的列,每列可以是不同的值,但每一列只能有一種資料型別。DataFrame既有行索引,也有列索引,它可以看作是由Series組成的字典,不過這些Series公用一個索引(可以參考下圖的資料結構軸線圖)。
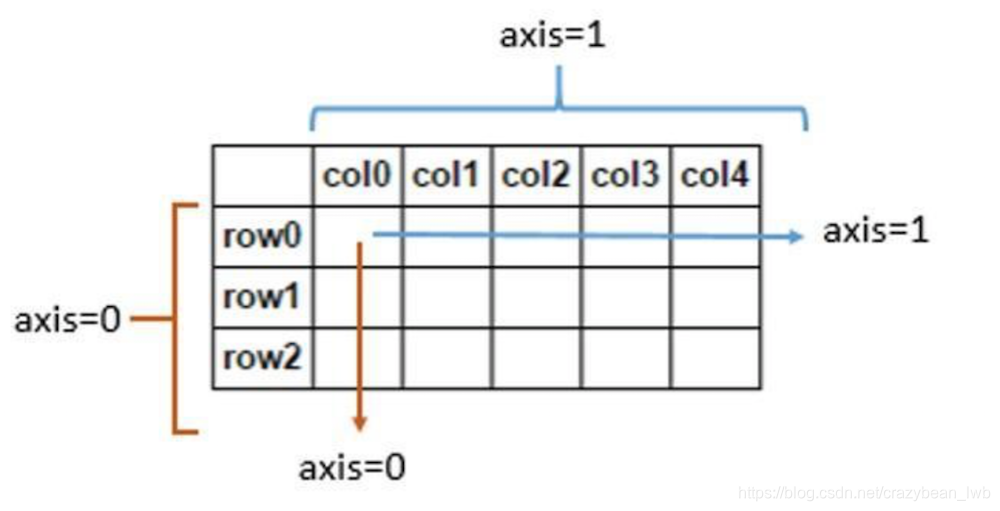
依賴python這一簡潔明瞭的語言,dataframe操作比較簡潔,此外dataframe還擁有比較豐富的操作api介面,能比較容易實現中小型資料集的操作。
spark dataframe結構與儲存特性
在Spark中, DataFrame是基於RDD實現的,一個以命名列方式組織的分散式資料集。實際儲存與RDD一致,基於行儲存,但是Spark框架本身不瞭解RDD資料的內部結構,而DataFrame卻提供了詳細的結構資訊(Schema),Spark DataFrame將資料以單獨表結構,分散在分散式叢集的各臺機器上,所以spark dataframe是天然的分散式表結構,具體差異可以參考下圖。

DataFrame基於RDD的抽象,由於DataFrame具有定義好的結構, Spark可以在作業執行時應用許多效能增強的方法。park對於DataFrame在執行時間和記憶體使用上相對於RDD有極大的優化。Catalyst優化引擎使執行時間減少75%, Project Tungsten Off-heap 記憶體管理使記憶體使用量減少75 +%,無垃圾回收器。使用DataFrame比普通Python RDD實現的快4倍,也達到Scala RDD實現的兩倍。經過Catalyst優化後的程式碼比解釋型程式碼明顯快很多。下圖給出了DataFrame執行速度和空間上的優勢。


spark toPandas詳解
Spark DataFrame與Pandas DataFrame結構形式是如此相似,肯定會有使用者思考是否有API能實現二者之間的互相轉換。pandas to saprk自不用說,而spark to pandas可以通過toPandas這一api實現。toPandas等效對rdd先做collect然後 to dataframe,是將分散式檔案收集導本地的操作,轉換後的檔案能與pandas一樣實現所有操作。使用spark的本意是對海量資料的操作,而轉換導本地的pandas操作失去了與其本意相差甚遠,所以不建議使用該api。