
java原始碼分析之集合框架HashTable 11
HashTable :
- 此類實現一個雜湊表,該雜湊表將鍵對映到相應的值。任何非
null物件都可以用作鍵或值。 - 為了成功地在雜湊表中儲存和獲取物件,用作鍵的物件必須實現
hashCode方法和equals方法。 Hashtable的例項有兩個引數影響其效能:初始容量 和載入因子。容量 是雜湊表中桶 的數量,初始容量 就是雜湊表建立時的容量。注意,雜湊表的狀態為open:在發生“雜湊衝突”的情況下,單個桶會儲存多個條目,這些條目必須按順序搜尋。載入因子 是對雜湊表在其容量自動增加之前可以達到多滿的一個尺度。初始容量和載入因子這兩個引數只是對該實現的提示。關於何時以及是否呼叫 rehash 方法的具體細節則依賴於該實現。- 通常,預設載入因子(0.75)在時間和空間成本上尋求一種折衷。載入因子過高雖然減少了空間開銷,但同時也增加了查詢某個條目的時間(在大多數Hashtable 操作中,包括get 和put 操作,都反映了這一點)。
- 初始容量主要控制空間消耗與執行
rehash操作所需要的時間損耗之間的平衡。如果初始容量大於Hashtable 所包含的最大條目數除以載入因子,則永遠 不會發生rehash操作。但是,將初始容量設定太高可能會浪費空間。 - 如果很多條目要儲存在一個
Hashtable中,那麼與根據需要執行自動 rehashing 操作來增大表的容量的做法相比,使用足夠大的初始容量建立雜湊表或許可以更有效地插入條目。(如果儲存很多條目,相比HashTable自己再擴容,將初始容量設定大點更速度快)。 - HashTable是執行緒安全的(等會我們在原始碼中就能看出)
Hashtable 結構:(注意這裡table首字母xiaoxi)

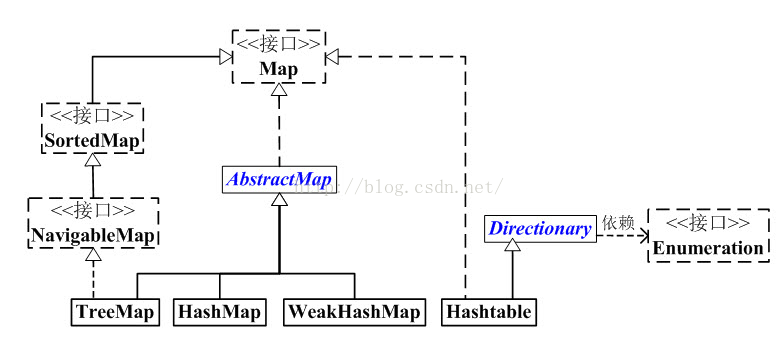
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable - Hashtable不僅繼承了Dictionary ,還實現了介面Serializable, Cloneable, Map<K,V> 。即HashTable序列化,可複製clone,是鍵值對儲存值。
Dictionary類是任何可將鍵對映到相應值的類(如Hashtable)的抽象父類。每個鍵和每個值都是一個物件。在任何一個 Dictionary 物件中,每個鍵至多與一個值相關聯。給定一個 Dictionary 和一個鍵,就可以查詢所關聯的元素。任何非null物件都可以用作鍵或值。通常,應該在此類的實現中使用equals方法,以決定兩個鍵是否相同。注:此類已過時。新的實現應該實現 Map 介面,而不是擴充套件此類.
Hashtable 方法:由原始碼可知HashTable是執行緒安全的。HashTable之所以是執行緒安全的,是因為方法上都加了synchronized關鍵字
synchronized void clear()
synchronized Object clone()
boolean contains(Object value)
synchronized boolean containsKey(Object key)
synchronized boolean containsValue(Object value)
synchronized Enumeration<V> elements()
synchronized Set<Entry<K, V>> entrySet()
synchronized boolean equals(Object object)
synchronized V get(Object key)
synchronized int hashCode()
synchronized boolean isEmpty()
synchronized Set<K> keySet()
synchronized Enumeration<K> keys()
synchronized V put(K key, V value)
synchronized void putAll(Map<? extends K, ? extends V> map)
synchronized V remove(Object key)
synchronized int size()
synchronized String toString()
synchronized Collection<V> values() Hashtable 資料結構
儲存結構:
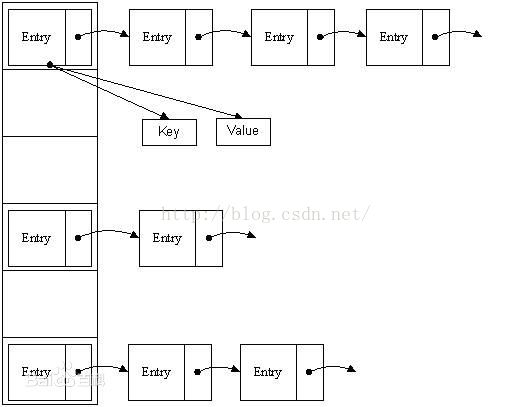
和HashMap一樣,HashTable內部也維護了一個數組,陣列中存放的是Entry<K,V>實體,陣列定義如下:
private transient Entry<K,V>[] table;Hashtable邏輯結構:
/**
* Entry實體類的定義
*/
private static class Entry<K,V> implements Map.Entry<K,V> {
int hash;//雜湊值
final K key;
V value;
Entry<K,V> next;//指向的下一個Entry,即連結串列的下一個節點
//構造方法
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
//這裡是單個Entry複製,深複製
protected Object clone() {
return new Entry<>(hash, key, value,
(next==null ? null : (Entry<K,V>) next.clone()));
}
// 重寫Map.Entry的全部方法5個
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
//判斷兩個Entry是否相等
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry)o;
//必須兩個Entry的key和value均相等才行
return key.equals(e.getKey()) && value.equals(e.getValue());
}
public int hashCode() {
return (Objects.hashCode(key) ^ Objects.hashCode(value));//異或
}
public String toString() {//重寫Object類的toString方法
return key.toString()+"="+value.toString();
}
}Hashtable屬性:
private transient Entry<K,V>[] table;
private transient int count;//記錄HashTable中有多少Entry實體
//閾值,用於判斷是否需要調整Hashtable的容量(threshold = 容量*載入因子)
private int threshold;
// 載入因子
private float loadFactor;
// Hashtable被改變的次數,用於fail-fast
private transient int modCount = 0;
// 序列版本號
private static final long serialVersionUID = 1421746759512286392L;
//最大的閾值,不能超過這個
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
//雜湊種子,使雜湊表分佈更均勻
transient int hashSeed;
//最大容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//set檢視中需要的屬性,具體看下面檢視方法原始碼
private transient volatile Set<K> keySet = null;
private transient volatile Set<Map.Entry<K,V>> entrySet = null;
private transient volatile Collection<V> values = null;
private static final int KEYS = 0;
private static final int VALUES = 1;
private static final int ENTRIES = 2;
構造方法:
public Hashtable(int initialCapacity, float loadFactor) {
//判斷是否是正常數值
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
//判斷是否是正常數值
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];//初始化陣列
//初始化闋值 = 容量 * 載入因子
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
initHashSeedAsNeeded(initialCapacity);//初始化雜湊種子
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);//預設載入因子為0.75
}
public Hashtable() {
this(11, 0.75f);//預設初始容量為11,載入因子為0.75
}
public Hashtable(Map<? extends K, ? extends V> t) {
//如果Map的2倍容量大於11,則使用新的容量
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}
存取方法:
put(K key, V value)
put(K key, V value)
將指定 key 對映到此雜湊表中的指定 value。
public synchronized V put(K key, V value) {
// 確保value不為空
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = hash(key);//計算hash值,此處會檢測key是否為空
int index = (hash & 0x7FFFFFFF) % tab.length;//計算出值在陣列table中的位置
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {//如果對應的key已經存在
V old = e.value;
e.value = value;//替換掉原來的value
return old;
}
}
modCount++;
//判斷是否需要擴容(再雜湊)
if (count >= threshold) {
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
//如果沒有對應的對應的key,新建一個Entry
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;//即size++
return null;
}
put方法中,首先檢測value是否為null,如果為null則會丟擲NullPointerException異常。然後往下走,跟HashMap的過程一樣,先計算雜湊值,再根據雜湊值計算在陣列中的索引位置,不過這裡計算索引位置的方法和HashMap不同,HashMap裡使用的是 hash & (length-1)的方法,其實本質上跟這裡用的(hash & 0x7FFFFFFF) % table.length一樣的效果,但是HashMap中的方法效率要高,至於它們兩為啥本質一樣的,可以參見我的上一部落格:HashMap,那裡分析的很詳細。
然後便開始往陣列中存資料了,如果當前的key已經在裡面了,那麼直接替換原來舊的value,如果不存在,先判斷陣列中的Entry數量有沒有達到門限值,達到了就要呼叫rehash方法進行擴容,然後重新計算當前key在新的陣列中的索引值,然後在該位置新增進去即可。如下hash() 和rehash()方法:
//jisuan計算hash值zhi
private int hash(Object k) {
return hashSeed ^ k.hashCode();
}
//再雜湊,擴容
protected void rehash() {
int oldCapacity = table.length;
Entry<K,V>[] oldMap = table;
//擴容為 = 原長度*2+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<K,V>[] newMap = new Entry[newCapacity];
modCount++;
//重置闋值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
//重置hash種子
boolean rehash = initHashSeedAsNeeded(newCapacity);
table = newMap;
//將舊錶的值放到新的表(陣列)中
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
if (rehash) {
e.hash = hash(e.key);
}
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}到這裡put方法就分析完了,還有個putAll方法,是將整個Map加到當前HashTable中,內部也是遍歷每個Entry,然後呼叫上面的put方法:
putAll(Map<? extends K,? extends V> t)
將指定對映的所有對映關係複製到此雜湊表中,這些對映關係將替換此雜湊表擁有的、針對當前指定對映中所有鍵的所有對映關係。
public synchronized void putAll(Map<? extends K, ? extends V> t) {
for (Map.Entry<? extends K, ? extends V> e : t.entrySet())
put(e.getKey(), e.getValue());
}get(Object key)
get(Object key)
返回指定鍵所對映到的值,如果此對映不包含此鍵的對映,則返回 null. 更確切地講,如果此對映包含滿足 (key.equals(k)) 的從鍵 k 到值 v 的對映,則此方法返回 v;否則,返回null。
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);//計算hash值
int index = (hash & 0x7FFFFFFF) % tab.length;//根據hash值計算所在索引
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}其他方法:
//初始化hash種子
final boolean initHashSeedAsNeeded(int capacity) {
boolean currentAltHashing = hashSeed != 0;
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
//返回此雜湊表中的鍵的數量。
public synchronized int size() {
return count;
}
//測試此雜湊表是否沒有鍵對映到值。
public synchronized boolean isEmpty() {
return count == 0;
}
//返回此雜湊表中的鍵的列舉。
public synchronized Enumeration<K> keys() {
return this.<K>getEnumeration(KEYS);
}
private <T> Enumeration<T> getEnumeration(int type) {
if (count == 0) {//返回一個空的列舉型別
return Collections.emptyEnumeration();
} else {
return new Enumerator<>(type, false);
}
}
//返回此雜湊表中的值的列舉。
public synchronized Enumeration<V> elements() {
return this.<V>getEnumeration(VALUES);
}
//測試此對映表中是否存在與指定值關聯的鍵。
public synchronized boolean contains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
//如果此 Hashtable 將一個或多個鍵對映到此值,則返回 true。
public boolean containsValue(Object value) {
return contains(value);
}
//測試指定物件是否為此雜湊表中的鍵。
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
//從雜湊表中移除該鍵及其相應的值。
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {//如果該值不是表頭
prev.next = e.next;
} else {//如果該值是表頭,表頭並不代表index=0
tab[index] = e.next;//換表頭
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
//將此雜湊表清空,使其不包含任何鍵。
public synchronized void clear() {
Entry tab[] = table;
modCount++;
//按照table陣列順序分別將值至空
for (int index = tab.length; --index >= 0; )
tab[index] = null;
count = 0;
}
//建立此雜湊表的淺表副本。
public synchronized Object clone() {
try {
Hashtable<K,V> t = (Hashtable<K,V>) super.clone();
t.table = new Entry[table.length];
for (int i = table.length ; i-- > 0 ; ) {
t.table[i] = (table[i] != null)
? (Entry<K,V>) table[i].clone() : null;
}
t.keySet = null;
t.entrySet = null;
t.values = null;
t.modCount = 0;
return t;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}
//返回此 Hashtable 物件的字串表示形式,其形式為 ASCII 字元 ", " (逗號加空格)分隔開的、括在括號中的一組條目。
public synchronized String toString() {
int max = size() - 1;
if (max == -1)
return "{}";
StringBuilder sb = new StringBuilder();
//返回此對映中包含的鍵的 Set 檢視的iterator迭代器。
Iterator<Map.Entry<K,V>> it = entrySet().iterator();
//將HashTable的key和value用StringBuilder拼接起來
sb.append('{');
for (int i = 0; ; i++) {
Map.Entry<K,V> e = it.next();
K key = e.getKey();
V value = e.getValue();
sb.append(key == this ? "(this Map)" : key.toString());
sb.append('=');
sb.append(value == this ? "(this Map)" : value.toString());
if (i == max)
return sb.append('}').toString();
sb.append(", ");
}
}
private <T> Iterator<T> getIterator(int type) {
if (count == 0) {//得到迭代器
return Collections.emptyIterator();
} else {//得到列舉
return new Enumerator<>(type, true);
}
}
/*-------------檢視------------------*/
private transient volatile Set<K> keySet = null;
private transient volatile Set<Map.Entry<K,V>> entrySet = null;
private transient volatile Collection<V> values = null;
private static final int KEYS = 0;
private static final int VALUES = 1;
private static final int ENTRIES = 2;
/*++++++++++++++++鍵的 Set 檢視+++++++++++++++++++*/
public Set<K> keySet() {
if (keySet == null)//指定 set 支援的同步(執行緒安全的)set。
keySet = Collections.synchronizedSet(new KeySet(), this);
return keySet;
}
private class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return getIterator(KEYS);//得到鍵的列舉或者空迭代器
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return Hashtable.this.remove(o) != null;
}
public void clear() {
Hashtable.this.clear();
}
}
/*++++++++++++++++對映關係Entry的 set 檢視+++++++++++++++++++*/
public Set<Map.Entry<K,V>> entrySet() {
if (entrySet==null)//指定 set 支援的同步(執行緒安全的)set。
entrySet = Collections.synchronizedSet(new EntrySet(), this);
return entrySet;
}
private class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return getIterator(ENTRIES);//得到對映關係Entry的列舉或者空迭代器
}
public boolean add(Map.Entry<K,V> o) {
return super.add(o);
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry entry = (Map.Entry)o;
Object key = entry.getKey();
Entry[] tab = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index]; e != null; e = e.next)
if (e.hash==hash && e.equals(entry))
return true;
return false;
}
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
K key = entry.getKey();
Entry[] tab = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e.hash==hash && e.equals(entry)) {
modCount++;
if (prev != null)//如果該值不是表頭
prev.next = e.next;
else//如果該值是表頭(表頭並不代表index=0)
tab[index] = e.next;
count--;
e.value = null;
return true;
}
}
return false;
}
public int size() {
return count;
}
public void clear() {
Hashtable.this.clear();
}
}
/*++++++++++++++++value值的 set 檢視+++++++++++++++++++*/
public Collection<V> values() {
if (values==null)//指定 collection 支援的同步(執行緒安全的)collection
values = Collections.synchronizedCollection(new ValueCollection(),
this);
return values;
}
private class ValueCollection extends AbstractCollection<V> {
public Iterator<V> iterator() {
return getIterator(VALUES);//得到value值的列舉或者空迭代器
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
Hashtable.this.clear();
}
}
/*------------ 比較與hash------------------*/
//按照 Map 介面的定義,比較指定 Object 與此 Map 是否相等。
public synchronized boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map<K,V> t = (Map<K,V>) o;
if (t.size() != size())
return false;
try {
Iterator<Map.Entry<K,V>> i = entrySet().iterator();
while (i.hasNext()) {
Map.Entry<K,V> e = i.next();
K key = e.getKey();
V value = e.getValue();
if (value == null) {
if (!(t.get(key)==null && t.containsKey(key)))
return false;
} else {
if (!value.equals(t.get(key)))
return false;
}
}
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
return true;
}
//按照 Map 介面的定義,返回此 Map 的雜湊碼值。
public synchronized int hashCode() {
int h = 0;
//若HashTable的實際大小為0或者載入因子<0,則返回0
if (count == 0 || loadFactor < 0)
return h; // Returns zero
loadFactor = -loadFactor; // 使hashCode在程式中可計算(此處不懂為什麼這樣做)
Entry[] tab = table;
//返回“HashTable中的每個Entry的key和value的異或值的總和”
for (Entry<K,V> entry : tab)
while (entry != null) {
h += entry.hashCode();
entry = entry.next;
}
loadFactor = -loadFactor; // 使hashCode在程式中計算完成
return h;
}
// java.io.Serializable的寫入函式
// 將Hashtable的“總的容量,實際容量,所有的Entry”都寫入到輸出流中
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
Entry<K, V> entryStack = null;
synchronized (this) {
// Write out the length, threshold, loadfactor
s.defaultWriteObject();
// Write out length, count of elements
s.writeInt(table.length);
s.writeInt(count);
// Stack copies of the entries in the table
for (int index = 0; index < table.length; index++) {
Entry<K,V> entry = table[index];
while (entry != null) {
entryStack =
new Entry<>(0, entry.key, entry.value, entryStack);
entry = entry.next;
}
}
}
// Write out the key/value objects from the stacked entries
while (entryStack != null) {
s.writeObject(entryStack.key);
s.writeObject(entryStack.value);
entryStack = entryStack.next;
}
}
// java.io.Serializable的讀取函式:根據寫入方式讀出
// 將Hashtable的“總的容量,實際容量,所有的Entry”依次讀出
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the length, threshold, and loadfactor
s.defaultReadObject();
// Read the original length of the array and number of elements
int origlength = s.readInt();
int elements = s.readInt();
// Compute new size with a bit of room 5% to grow but
// no larger than the original size. Make the length
// odd if it's large enough, this helps distribute the entries.
// Guard against the length ending up zero, that's not valid.
int length = (int)(elements * loadFactor) + (elements / 20) + 3;
if (length > elements && (length & 1) == 0)
length--;
if (origlength > 0 && length > origlength)
length = origlength;
Entry<K,V>[] newTable = new Entry[length];
threshold = (int) Math.min(length * loadFactor, MAX_ARRAY_SIZE + 1);
count = 0;
initHashSeedAsNeeded(length);
// Read the number of elements and then all the key/value objects
for (; elements > 0; elements--) {
K key = (K)s.readObject();
V value = (V)s.readObject();
// synch could be eliminated for performance
reconstitutionPut(newTable, key, value);
}
this.table = newTable;
}
private void reconstitutionPut(Entry<K,V>[] tab, K key, V value)
throws StreamCorruptedException
{
if (value == null) {
throw new java.io.StreamCorruptedException();
}
// Makes sure the key is not already in the hashtable.
// This should not happen in deserialized version.
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
throw new java.io.StreamCorruptedException();
}
}
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
//列舉型迭代器(主要是keys() ,elements()兩個函式呼叫)
//非執行緒安全的(除了該類的remove())
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
Entry[] table = Hashtable.this.table;
int index = table.length;
Entry<K,V> entry = null;
Entry<K,V> lastReturned = null;
int type;
boolean iterator;
protected int expectedModCount = modCount;
/*----------實現Enumeration介面的方法----------*/
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
public boolean hasMoreElements() {
Entry<K,V> e = entry;
int i = index;
Entry[] t = table;
/* 在本地實現迭代器,速度更快 */
//此處迴圈遍歷是按照陣列table索引從後向前遍歷,找不為null的值
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
}
public T nextElement() {
Entry<K,V> et = entry;
int i = index;
Entry[] t = table;
/* 在本地實現迭代器,速度更快 */
//此處迴圈遍歷是按照陣列table索引從後向前遍歷,找不為null的值
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
Entry<K,V> e = lastReturned = entry;
entry = e.next;
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
/*----------實現Iterator介面的方法----------*/
public boolean hasNext() {
return hasMoreElements();
}
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
}
public void remove() {
if (!iterator)
throw new UnsupportedOperationException();
if (lastReturned == null)
throw new IllegalStateException("Hashtable Enumerator");
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
synchronized(Hashtable.this) {//執行緒安全的
Entry[] tab = Hashtable.this.table;
int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e == lastReturned) {
modCount++;
expectedModCount++;
if (prev == null)//如果當前entry是表頭
tab[index] = e.next;
else//如果當前entry不是表頭
prev.next = e.next;
count--;
lastReturned = null;
return;
}
}
throw new ConcurrentModificationException();
}
}
}
Hashtable 的迭代
hashtable遍歷有兩種方式:
1、返回以雜湊表的列舉方式;
①keys()返回此雜湊表中的鍵的列舉。
②elements()返回此雜湊表中的值的列舉。
2、返回以雜湊表的Set方式;
①keySet()返回此對映中包含的鍵的
Set檢視。
②values()返回此對映中包含的鍵的
Collection檢視。
③entrySet()返回此對映中包含的鍵的
Set檢視。
詳細看程式碼:
package wn.comeOn.java.test;
import java.util.Enumeration;
import java.util.Hashtable;
import java.util.Iterator;
public class Test{
public static void main(String[] args) {
//初始化Hashtable
Hashtable<Integer , Integer> tab = init();
//迭代以雜湊表的列舉方式;
System.out.println("-------------列舉方式:-------------");
keysHashtable(tab);
elementsHashtable(tab);
//迭代以雜湊表的Set方式;
System.out.println("-------------Set方式:-------------");
keySetHashtable(tab);
valuesHashtable(tab);
entrySetHashtable(tab);
}
//初始化
private static Hashtable<Integer, Integer> init() {
Hashtable<Integer, Integer> table = new Hashtable<>();
for(int i=0; i<1000000; i++){
table.put(i, i);
}
return table;
}
//列舉:keys()遍歷key
private static void keysHashtable(Hashtable<Integer, Integer> tab) {
long start = System.currentTimeMillis();
Enumeration<Integer> iterator = tab.keys();
while(iterator.hasMoreElements()){
iterator.nextElement();
}
long end = System.currentTimeMillis();
System.out.println("列舉:keys()遍歷key:" + (end-start));
}
//列舉:elements()遍歷value
private static void elementsHashtable(Hashtable<Integer, Integer> tab) {
long start = System.currentTimeMillis();
Enumeration<Integer> iterator = tab.elements();
while(iterator.hasMoreElements()){
iterator.nextElement();
}
long end = System.currentTimeMillis();
System.out.println("列舉:elements()遍歷value:" + (end-start));
}
//Set:keySet()遍歷key
private static void keySetHashtable(Hashtable<Integer, Integer> tab) {
long start = System.currentTimeMillis();
Iterator iterator = tab.keySet().iterator();
while(iterator.hasNext()){
iterator.next();
}
long end = System.currentTimeMillis();
System.out.println("Set:keySet()遍歷key:" + (end-start));
}
//Collection:values()遍歷value
private static void valuesHashtable(Hashtable<Integer, Integer> tab) {
long start = System.currentTimeMillis();
Iterator iterator = tab.values().iterator();
while(iterator.hasNext()){
iterator.next();
}
long end = System.currentTimeMillis();
System.out.println("Collection:values()遍歷value:" + (end-start));
}
//Set:entrySet()遍歷entry
private static void entrySetHashtable(Hashtable<Integer, Integer> tab) {
long start = System.currentTimeMillis();
Iterator iterator = tab.entrySet().iterator();
while(iterator.hasNext()){
iterator.next();
}
long end = System.currentTimeMillis();
System.out.println("Set:entrySet()遍歷entry:" + (end-start));
}
}
-------------列舉方式:-------------
列舉:keys()遍歷key:23
列舉:elements()遍歷value:13
-------------Set方式:-------------
Set:keySet()遍歷key:15
Collection:values()遍歷value:14
Set:entrySet()遍歷entry:15
由程式碼可知,總體是這樣:
列舉的keys() 慢於 Set的keySet();
列舉的elements() 與 Collection的values() 遍歷快慢取決於資料量
這是幾組資料測試,程式碼還是上面的程式碼,只是更改了資料總量:
