
Java原始碼分析之HashMap(JDK1.8)
阿新 • • 發佈:2019-01-23
一、HashMap概述
HashMap是常用的Java集合之一,是基於雜湊表的Map介面的實現。與HashTable主要區別為不支援同步和允許null作為key和value。由於HashMap不是執行緒安全的,如果想要執行緒安全,可以使用ConcurrentHashMap代替。
二、HashMap資料結構
HashMap的底層是雜湊陣列,陣列元素為Entry。HashMap通過key的hashCode來計算hash值,當hashCode相同時,通過“拉鍊法”解決衝突,如下圖所示。
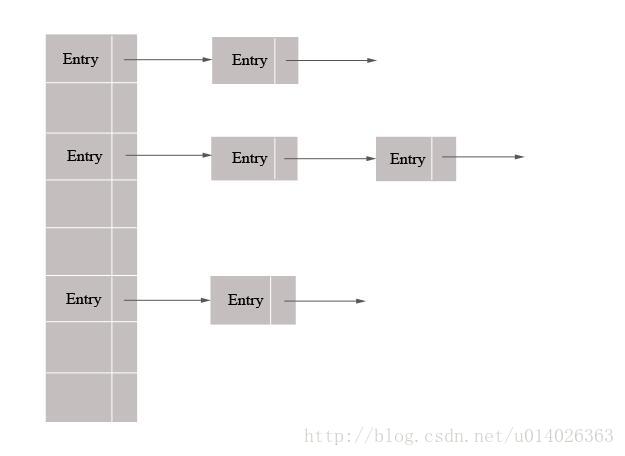
相比於之前的版本,jdk1.8在解決雜湊衝突時有了較大的變化,當連結串列長度大於閾值(預設為8)時,將連結串列轉化為紅黑樹,以減少搜尋時間。原本Map.Entry介面的實現類Entry改名為了Node。轉化為紅黑樹時改用另一種實現TreeNode。
Node類
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 雜湊值
final K key;
V value;
Node<K,V> next; // 指向下一個節點
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this TreeNode類
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
}HashMap就是這樣一個Entry(包括Node和TreeNode)陣列,Node物件中包含鍵、值和hash值,next指向下一個Entry,用來處理雜湊衝突。TreeNode物件包含指向父節點、子節點和前一個節點(移除物件時使用)的指標,以及表示紅黑節點的boolean標識。
三、HashMap原始碼分析
1. 主要屬性
transient Node<K,V>[] table; // 雜湊陣列
transient Set<Map.Entry<K,V>> entrySet; // entry快取Set
transient int size; // 元素個數
transient int modCount; // 修改次數
int threshold; // 閾值,等於載入因子*容量,當實際大小超過閾值則進行擴容
final float loadFactor; // 載入因子,預設值為0.752. 構造方法
以下是HashMap的幾個構造方法。
/**
* 根據初始化容量和載入因子構建一個空的HashMap.
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* 使用初始化容量和預設載入因子(0.75).
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* 使用預設初始化大小(16)和預設載入因子(0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* 用已有的Map構造一個新的HashMap.
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}3. 資料存取
- putAll方法
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
/**
* Implements Map.putAll and Map constructor
*
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict); // put核心方法
}
}
}- put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // table為空或length為0
n = (tab = resize()).length; // 初始化
if ((p = tab[i = (n - 1) & hash]) == null) // 如果hash所在位置為null,直接put
tab[i] = newNode(hash, key, value, null);
else { // tab[i]有元素,遍歷節點後新增
Node<K,V> e; K k;
// 如果hash、key都相等,直接覆蓋
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) // 紅黑樹新增節點
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // 連結串列
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { // 找到連結串列最後一個節點,插入新節點
p.next = newNode(hash, key, value, null);
// 連結串列節點大於閾值8,呼叫treeifyBin方法,當tab.length大於64將連結串列改為紅黑樹
// 如果tab.length < 64或tab為null,則呼叫resize方法重構連結串列.
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// hash、key都相等,此時節點即要更新節點
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 當前節點e = p.next不為null,表示連結串列中原本存在相同的key,則返回oldValue
if (e != null) { // existing mapping for key
V oldValue = e.value;
// onlyIfAbsent值為false,引數主要決定存在相同key時是否執行替換
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) // 檢查是否超過閾值
resize();
afterNodeInsertion(evict);
return null; // 原HashMap中不存在相同的key,插入鍵值對後返回null
}- get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode) // 紅黑樹
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 連結串列
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
// 遍歷紅黑樹搜尋節點
/**
* Calls find for root node.
*/
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
/**
* Finds the node starting at root p with the given hash and key.
* The kc argument caches comparableClassFor(key) upon first use
* comparing keys.
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h) // 當前節點hash大
p = pl; // 查左子樹
else if (ph < h) // 當前節點hash小
p = pr; // 查右子樹
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p; // hash、key都相等,即找到,返回當前節點
else if (pl == null) // hash相等,key不等,左子樹為null,查右子樹
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}- remove方法
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 直接命中
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode) // 在紅黑樹中查詢
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else { // 在連結串列中查詢
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 命中後刪除
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) // 在紅黑樹中刪除節點
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p) // 連結串列首節點刪除
tab[index] = node.next;
else // 多節點連結串列刪除
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}- clear方法
/**
* Removes all of the mappings from this map.
* The map will be empty after this call returns.
*/
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null; // 把雜湊陣列中所有位置都賦為null
}
}四、總結
本文從原始碼入手,簡單地分析了HashMap底層的結構和實現。在原始碼分析部分主要分析了常用的幾個方法,還有一些方法比如調整雜湊表大小的resize、將連結串列轉化為紅黑樹的treeify以及逆操作untreeify等,在此不再詳細分析。紅黑樹部分的程式碼只理解了大概,實現細節上還有待進一步閱讀分析。