
文字壓縮演算法的對比和選擇
本文主要粗略介紹資料壓縮主要演算法類別,以及最新針對Web文字資源的zStd和Brotli演算法的設計要點。為Web業務應用如何使用它們替換傳統gzip提供些參考。最後是一個文字有失真壓縮的嘗試。
在資料壓縮領域裡,文字壓縮的歷史最久,從Morse到Huffman和算術編碼(Arithmetic coding),再到基於字典和上下文的壓縮演算法。各種演算法不斷改進,從通用演算法,到現在更具針對性的演算法,結合應用場景的垂直化的趨勢越來越明顯。所以在選擇或者評價壓縮演算法,一定要結合實際應用場景加以考慮,包括字符集、內容的大小、壓縮及解壓的效能、以及各端支援情況。
資料壓縮演算法
一套完整的壓縮演算法,實際以下幾個部分:
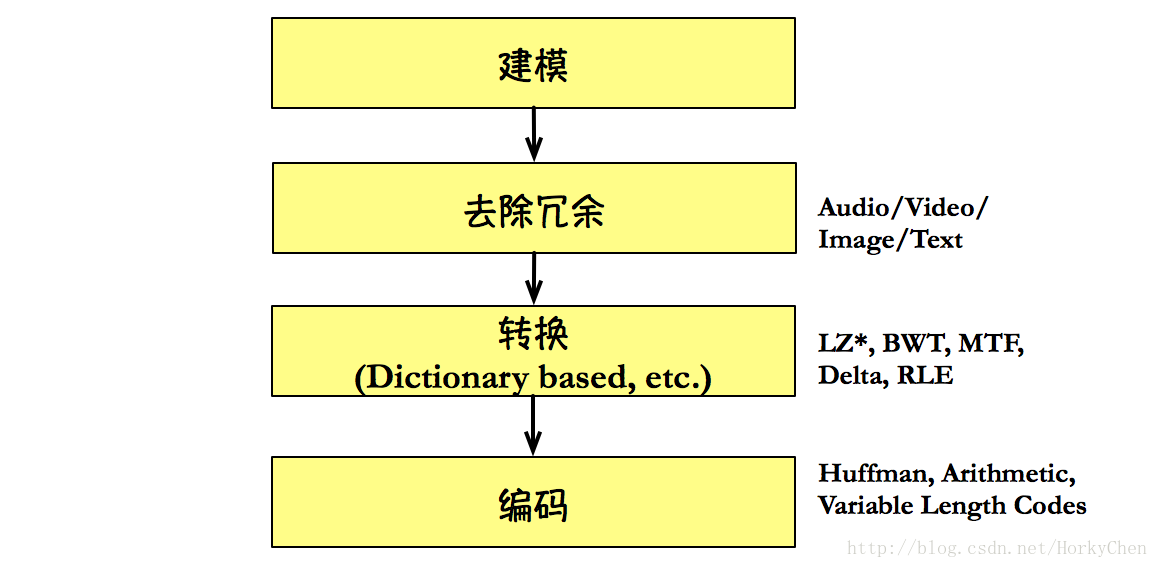
其中除編碼外的三專案的都是找到一個適於編碼的表示方法,而編碼則是以簡化的方法進行輸出。最典型的建模方法是基於字元的概率統計,而基於上下文的建模方法(Context Modeling)則是從文字內容出發,它們追求的目標都是讓字元的出現概率越不平均越好。轉換方法是最具代表性的是基於詞典的轉換,比如龐大的LZ族系。Huffman和算術編碼則是常見的編碼方法。
因為語言本身的特性,基於上下文的建模方法(Context Modeling,如PPM*系列演算法)可以得到更好的壓縮比,但卻由於它的效能問題卻很普及。當前比較流行的壓縮演算法中其突破的核心只有兩個:
* ANS (FSE是它的一個實現): Facebook zStd, Apple的lzfse等
* Context Modeling + LZ77 (編碼是Huffman): Brotli
下圖為六種演算法的壓縮比測試的結果,分別針對一本英文小說,一本中文小說,和一份較小(4KB+)的中文混合的JSON資料。
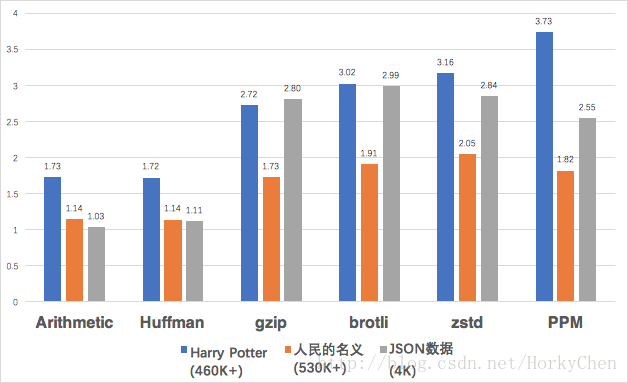
*其中PPM是Context Modeling的代表。
可以看到演算法對字符集(中文與英文)和大小都是敏感的,表現各不相同。
演算法思想的簡單概括
Huffman編碼受到了Morse編碼的影響,背後的思想就是將最高概率出現的字母以最短的編碼表示。比如英文中字母e出現概率為12%,字母z的出現概率還不到1%。
演算法編碼以及區間編碼,它們是利用字元概率分佈,將字元組合轉變為概率的層次劃分,最終轉換一個固定的數字(算術編碼和區間編碼最大差別就在於一個使用小數,另一個使用整數)。可以對應下圖考慮下AAAA,以及AAB的編碼輸出 (在0-1的軸上找到一個數字來表示。)。
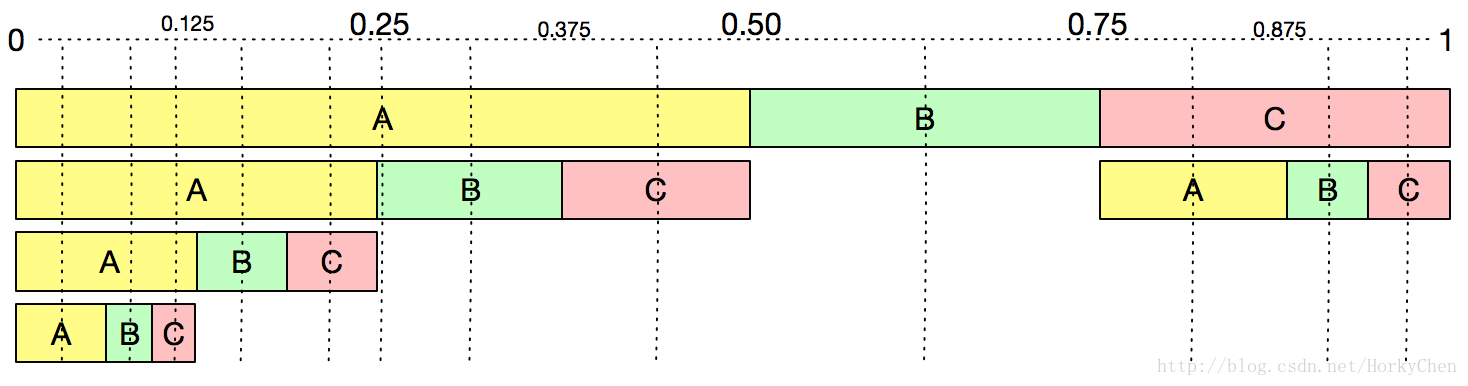
上面這兩類演算法一直霸佔著演算法編碼領域,各種擁有大量的變形。從實用效果上,算術編碼的壓縮比一般要好於Huffman。但Huffman的效能要優於算術編碼,兩者都有自適應的演算法,不必依賴全文進行概率統計,但畢竟算術編碼還是需要更大的計算量。
ANS是前兩類編碼演算法戰爭的終結者。它在2014年被提出來,隨後很快就得到了大量應用。本質上屬於算術編碼,但它成功地找到了一個用近似概率表示的表格,將原來的概率計算轉換為查表。所以它是一個達到Huffman編碼效率的算術編碼方法。是ANS最為著名的實現。
之前提過建模方法,要追求字元出現概率的不平均。比如動態馬爾可夫壓縮(DMC, dynamic Markov coding)。仍以英為例,全文來看,字母e出現概率最高,但是在首字母這種狀態下,字母t的出現概率可以接近17%。就是字母在是否首字母的兩種狀態下是有兩種概率分佈的:
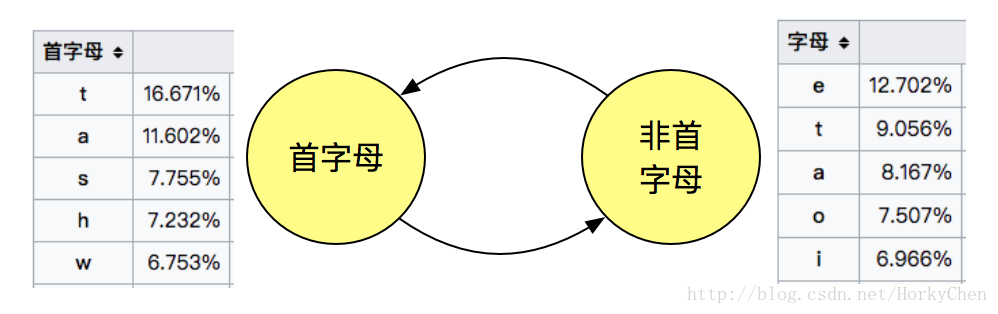
*非首母下,各字母的出現概率有可能還有變化。
基於上下文的建模,可以想象下成語填空或者詩詞填空,其中有一個條件概率的問題。在下圖中,如果單個字元看,我們只能從整體漢字的概率分佈來考慮人後面的字。如果從詞的角度發出,後面確實可能會出現幾個概率較大的單字,這是一階上下文。再進一步,如果之前出現過單字華,這是二階上下文(2nd order),後面文字出現的概率又會發生變化。如果再往前取一個單字又是中,那麼不單是後面單字民的概率極高,而且再往後有三個字的出現概率也是奇高的。在隨後編碼時,我們就可以為它找出一個最短的表示。
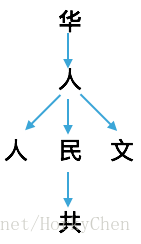
實際應用不可能讓演算法先要理解文字,絕大部分情況也不可能為此先建一個語料庫,即使有語料庫,其處理效能仍然會是很大的問題。其實我們也不需要得到極為精確的相關性,只要快速掌握到一定的模式就足夠了。好像學生根本不需要做大規模的訓練,就能很快注意到老師的口頭禪或者常用語,進而學得有模有樣。所以可行的演算法只需要基於一部分內容的上下文進行預測,這就是PPM(部分匹配預測,prediction by partial match)以及各種演進版本。
轉換(Transform)裡詞典方法很好理解,就不介紹了,已經是應用最為廣泛技術。而文字壓縮基本目標是無失真壓縮,所以去冗餘這項我們最後再談。
內容字符集與大小的影響
我們思考一個問題:為什麼各種演算法對內容字符集和大小的效果不同?
字符集的差異很好理解,由前面提到的資訊熵決定。有很多人在連續很多年都討論過這個問題,也有非常精確的漢字資訊熵的評價。單純從當前編碼的角度來看,就是作為中文基礎單元的單字數遠比英文中基本字母多得多。大的字符集很自然就使得字元間的概率差異較小,所以此時Huffman和算術編碼這類依賴於概率統計的演算法對於中文壓縮都遠不及對英文壓縮的效果。
回頭再看下上面演算法對比結果。當純英文時,算術編碼壓縮比優於Huffman。遇到大字符集的中文時,基本和Huffman一樣了。這兩個演算法在這個測試場景沒有拉來明顯差距,可以動手換個二進資料再對比一下。
如果遇到中英文混合,且內容較小的JSON資料時,算術編碼就歇菜了。
內容大小的影響是來自於演算法本身的學習成本。從統計的角度看,內容大小代表了樣本的多寡,會直接影響統計結果。以基於概率統計的演算法為例,如果極少字元,有利於編碼。但同時沒有足夠的資料量,字元間沒法形成概率分佈的差異,又不利於編碼。兩者共同決定最終了壓縮比。
在測試資料裡基於上下文建模的PPM表現明顯優於Huffman和算術編碼。說明雖然僅僅在區域性理解字元出現的相關性,就已經能夠很好地優化效果了。即使是小資料,也遠高於前面兩類的效果。
到這裡,請思考一個問題:
- 什麼方法能降低壓縮演算法的學習成本?
那麼我們需要先定義:
- 字符集是什麼?它的規模多大?字元的概率分佈如何?
- 內容會多大?
*效率和費用的問題,我們不討論了。
這個時候轉換就能發揮最大的功效了,特別預設字典類的演算法。
下面是一更為具體的問題,也可以練習一下:
如果我們要設計一個極短文字(如100字以內)的壓縮演算法,什麼會是最為效的演算法?
Brotli與zStd的對比和選擇
在Web應用場景下,壓縮演算法要追求的是更小且更快(對於流式資料,還有吞吐量的要求,另有演算法應對),演算法主要在壓縮比和效能之間尋求平衡。目前頁面上的各種文字資源主要還是使用gzip壓縮,自zStd和Brotli推出後,我們該如何選擇呢?
如果你只想瞭解一下兩者的選擇,可以跳過下面關於兩者對比的一節。
Brotli與zStd的對比
Brotli演算法可以理解為LZ* + Context Modeling + Huffman編碼。這是一個極為完整的無失真壓縮演算法,三個部分全涉及到了。它的compression level分為11級,一般測試而言它的level 5可以達到gzip 9的效果。主要特色包括:
- 詞典的Sliding Window擴充到16MB
- 針對6國常用詞及HTML&JS常用關鍵詞的靜態(預置)詞典
- 基於二階上下文建模 (2nd order context modeling)
注意context modeling的效能很弱,如果對壓縮效能要求不高(如本地PC壓縮),可以把level調到6以上測試下。目前Chromium-based的瀏覽都預設支援Brotli。
zStd是基於FSE(ANS的一個實現),針對MB級別以上的資料,最為有效。 但是對於小資料,它特別提供一個詞典方法(回顧下前面關於小資料壓縮的問題)。 這個方法需要針對目標資料做訓練,就能生成這個詞典。使用的方法如下:
1) 詞典訓練
zstd --train FullPathToTrainingSet/* -o dictionaryName
2) 壓縮
zstd -D dictionaryName FILE
3) 解壓
zstd -D dictionaryName --decompress FILE.zst這種方法的一個侷限就是應用的範圍,需要既要有相對穩定的內容,又要有客戶端的支援。
Brotli和zStd的選擇
如果兩個可以同時選擇時:
較大的文字資料,選擇zStd。較小的資料,選擇Brotli或者zStd的詞典模式。
大和小的邊界需要根據內容測試來定義。500KB左右,zStd的表現一般會超過Brotli。
不要使用預設值對比。
Brotli預設的compression level是它的最大值,即11。而zstd預設是3, gzip預設為6。
以下是使用UC頭條的33條資料,大小在3~26KB,包括HTML和JSON資料,在Mac Pro上做的對比測試。
針對性能,直接使用工具對每個檔案呼叫一次,最後加總時間的方法進行測試,並不是工具批次處理功能,所以存在一定的優化空間,特別是Brotli這種需要載入預置詞典的演算法。
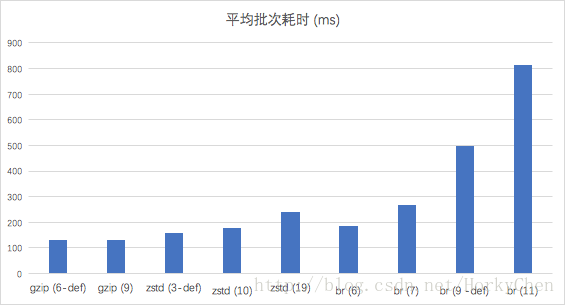
從完成全部檔案壓縮所用時間上看,zstd/brotli對比gzip的耗時都有一定的增加。zstd-10和brotli-6基本接近:
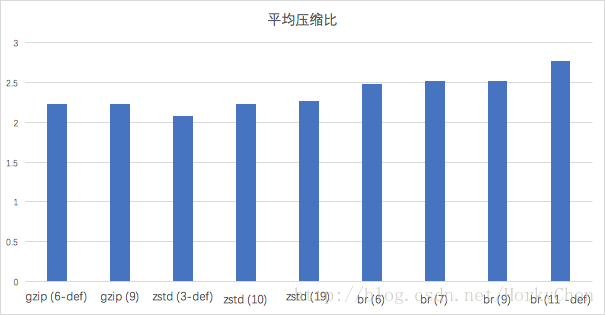
但從壓縮比上看,brotli-6的效果就要優於zstd-10了:
演算法選擇需要考慮的因素
所以本文寫到這裡,可以得出結論只有一個,選擇一個文字壓縮演算法最有效的方式是實驗,而且不要輕人別人的測試結果,如果不知道為什麼?麻煩回到最上方,重新讀一遍。只能通過實驗,才能得出一個更為有效的演算法以及引數的選擇。
- 壓縮比 確定出目標內容,並按涉及的字符集和大小,按組合和梯度做好測試。
- 壓縮效能 & 解壓效能 執行壓縮和解壓的裝置各是什麼?效能帶來的延遲影響有多大?
- 各端支援的情況 特別是客戶端、瀏覽器上的支援情況。
- 內容動態性 即目標內容變化頻率。比如實時壓縮,且吞吐量較大,你就要評估下LZ4演算法。其它情況要用好快取和CDN。
- 專利費用 比如算術編碼是用專利費用的,而區間編碼則是免費的。
文字的有失真壓縮?
開篇也提到了針對場景的壓縮演算法研究是目前的趨勢,特別是找到更有效的建模方法。傳統意義上理解資料壓縮,包括文字壓縮都應當是無損的。但其實也有一種場景是需要有失真壓縮的。
比如早期電報,惜字如金。在現在的場景下,內容的概要處理就是有失真壓縮的一個典型需求。內容的大爆發之後就有內容的進一步管理和挖掘的問題。內容的概要處理一是方便展示,二是方便檢索和歸類。
藉助現在NLP領域的成果,我們可以很輕鬆地對句子結構和成分進行分析。可以在句子中定位出介詞短語(PP),量詞短語(QP),動詞短語(VP),又或者名詞短語(NP)等。基於這個結果,可以定位出句子的主要成分,然後把修飾成分作為冗餘去掉(去冗餘)。
以句子從樂視危機、易到事件,再到資金凍結、機構撤資,最近半年,樂視就像一部跌宕起伏的電視劇,作為樂視的創始人,賈躍亭一次又一次被推上風口浪尖。為例:
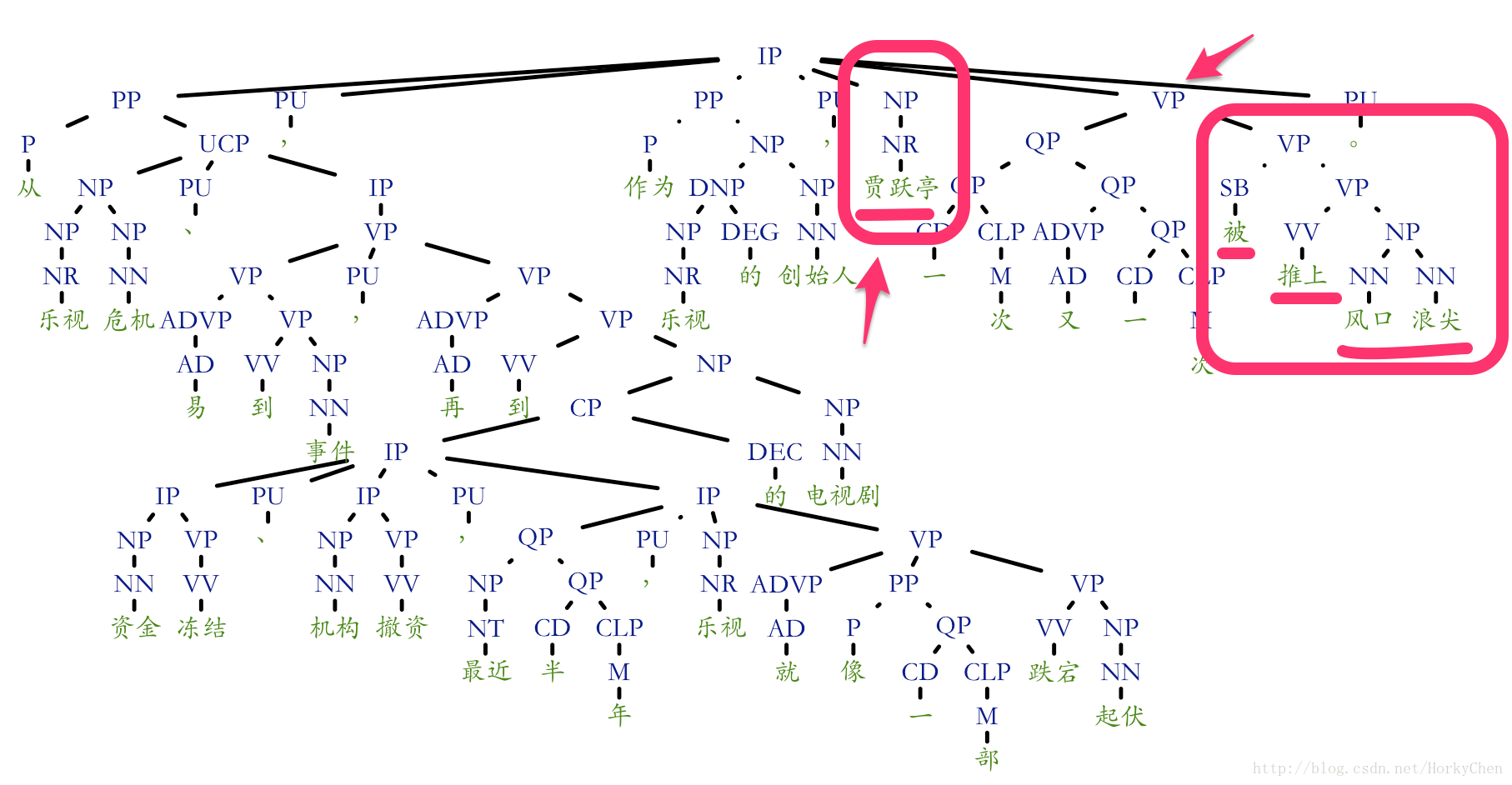
我們去掉修飾短語,使用圖中標出的名詞及動詞短語,就很容易得到核心成份:
賈躍亭被推上風口浪尖。
示例使用R及Standford CoreNLP包在Mac OS下完成,原始碼在GitHub上。
雖然目前這種處理的效能還是達到產品化要求,但相關的應用已經近在眼前。
因為非壓縮領域的專業人員,本文只是一段時間學習的總結。一定有錯誤和理解不透的地方,歡迎指正!