
YARN提交任務作業(以wordcount樣例程式為例)
阿新 • • 發佈:2019-01-11
前提
已經搭建好Hadoop環境。
向YARN提交wordcount任務
1、首先在HDFS建立輸入檔案目錄,並將待處理的wordcount檔案傳入相應的輸入檔案目錄。
# 建立輸入檔案目錄
hadoop fs -mkdir -p /tmp/jbw/wordcount_input_dir
# 將待處理的檔案上傳至對應目錄
hadoop fs -put /mnt/disk1/linken_speech.txt /tmp/jbw/wordcount_input_dir
hadoop fs -ls /tmp/jbw/wordcount_input_dir

2、執行Hadoop的woedcount樣例程式(向YARN提交作業)
引數中指定jar執行檔案、輸入資料目錄(需要先建立好,並將待處理文字上傳至其中)、輸出目錄(無需建立,由樣例程式自己生成)。
hadoop jar hadoop/bin/hadoop-mapreduce-examples.jar wordcount /tmp/jbw/wordcount_input_dir /tmp/jbw/wordcount_output_dir執行過程如下圖,可以看到wordcount執行過程會分map和reduce兩個階段。
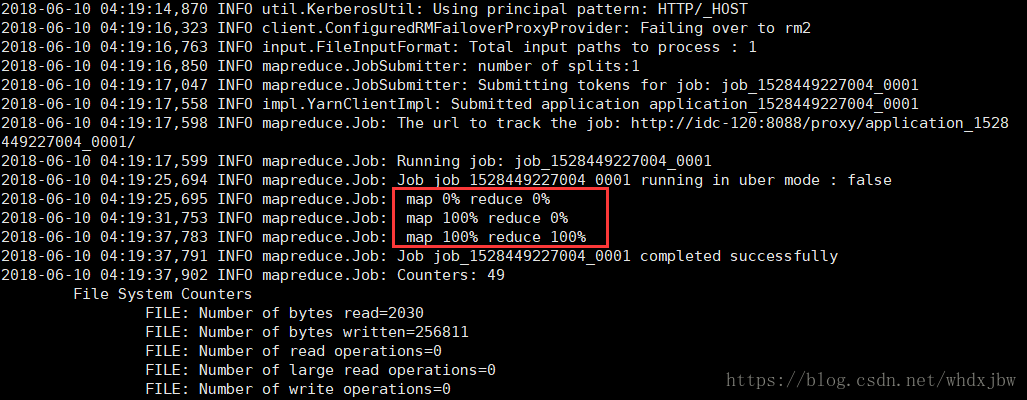
3、檢視執行結果
在HDFS的輸出檔案目錄下檢視是否有結果檔案,並檢視。
hadoop fs -ls /tmp/jbw/wordcount_output_dir
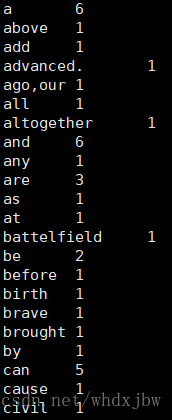
hadoop fs -cat 
結果如下,可以看到每個單詞的出現次數已經被統計出來:
Kill掉YARN上的某個任務
我們可以kill掉提交給YARN上的任何執行中的任務。這裡以大資料基準測試TPC造資料作為向YARN提交的任務。關於TPC,它其實會生成大量不同數量級別的用於測試大資料平臺效能的標準測試資料。這裡選它的原因是它造大量資料的時間比較長,我們有充分的時間可以kill掉它。
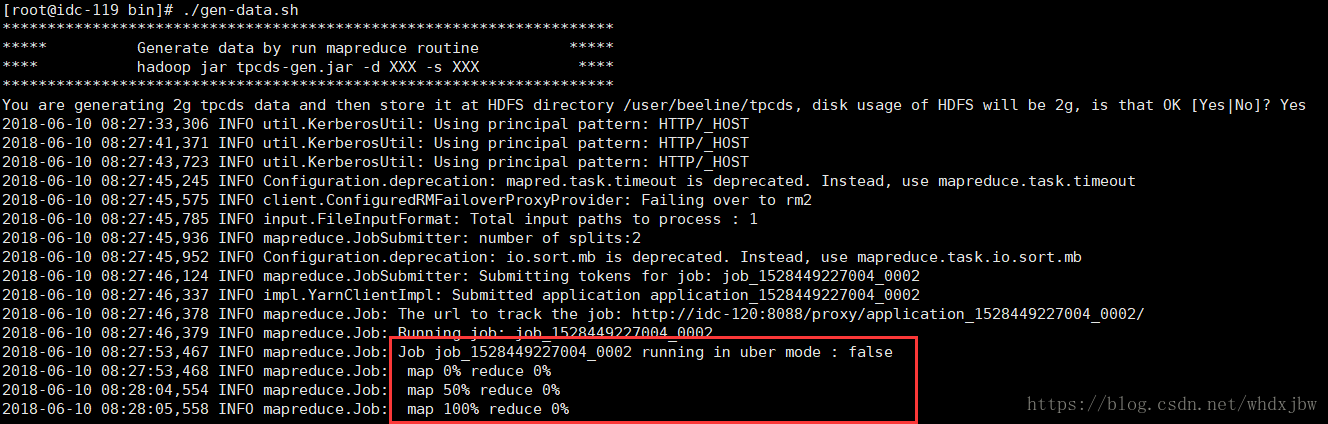
解壓tpcds-5.x.tar.gz檔案,進入bin目錄執行./gen-date.sh:
tar -zxvf tpcds-5.x.tar.gz
cd tpcds/bin
# 生成資料 過程如下:
現在我們看一下YARN上有哪些執行的作業,並檢視狀態:
yarn application -list
# 根據任務ID檢視任務狀態
yarn application -status application_1528449227004_0002
指定任務ID,kill掉它
yarn application -kill application_1528449227004_0002