
學習樸素貝葉斯演算法的5個簡單步驟
貝葉斯分類是一類分類演算法的總稱,這類演算法均以貝葉斯定理為基礎,故統稱為貝葉斯分類。
而樸素貝葉斯分類是貝葉斯分類中最簡單,也是常見的一種分類方法。
本文將通過6個步驟帶領你學習樸素貝葉斯演算法。
Step1
什麼是樸素貝葉斯演算法?
樸素貝葉斯演算法是一種基於貝葉斯定理的分類技術,假設在預測變數之間具有獨立性。
給定一個水果,如果水果是黃色的,圓形的,直徑約30釐米,則可以認為它是橘子。
即使對於橘子描述的這些特徵彼此依賴或依賴於其他特徵的存在,但所有的這些特徵都促成了這個水果是橘子的可能性,這就是它被稱為“樸素”的原因。
樸素貝葉斯模型易於構建,特別適用於非常大的資料集。
貝葉斯定理提供了一種從P(c),P(x)和P(x | c)計算後驗概率P(c | x)的方法。
請看下面的等式:

·P(c | x)是給定預測值(x,屬性)的類(c,目標)的後驗概率。
·P(c )是先驗概率。
·P(x | c)是給定類別的預測概率的似然性。
·P(x)是預測的先驗概率。
簡單來說,貝葉斯定理是基於假設的先驗概率、給定假設下觀察到不同資料的概率,提供了一種計算後驗概率的方法。
Step2
樸素貝葉斯演算法如何工作
讓我們用一個例子來理解它。下面有一個關於天氣和空氣質量的訓練資料集,根據天氣記錄的空氣質量的好壞。
現在,我們需要根據天氣情況對空氣質量的好壞進行分類。
第1步:將資料集轉換為頻率表。
第2步:通過找到陰天概率= 0.28和空氣質量好概率為0.64的概率來建立似然表。
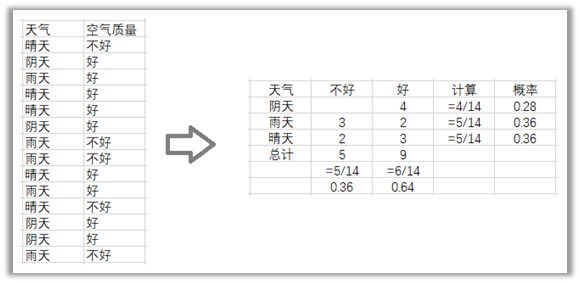
第3步:現在,使用樸素貝葉斯方程計算每個類的後驗概率。具有最高後驗概率的類是預測的結果。
問題:如果天氣晴朗,空氣質量會是好。這個陳述是正確的嗎?
我們可以使用上面討論的後驗概率方法來解決它。
·P(好|晴天)= P(晴天|好)* P(好)/ P(晴天)
·P(晴天|好)= 3/9 = 0.33
·P(晴天)= 5/14 = 0.36
·P(好)= 9/14 = 0.64
·P(好| 晴天)= 0.33 *0.64 / 0.36 = 0.60
得出結論,天氣晴朗空氣質量好具有更高的概率。
NaiveBayes使用類似的方法根據各種屬性預測不同類別的概率。該演算法主要用於文字分類,並且具有多個類的問題。
Step3
樸素貝葉斯的優點和缺點
優點
1)預測測試資料集很容易也很快,在多類預測中表現良好。
2)演算法簡單,常用於文字分類。
3)樸素貝葉斯模型有穩定的分類效率。
4)適合增量式訓練,尤其是資料量超出記憶體時,可以一批批的去增量訓練。
缺點
1)如果分類變數具有在訓練資料集中未觀察到的類別,則模型將指定0(零)概率並且將無法進行預測。
2)獨立預測因子的假設無法實現,我們幾乎不可能得到一組完全獨立的預測變數。
3)需要知道先驗概率,且先驗概率很多時候取決於假設。
4)通過先驗和資料來決定後驗的概率從而決定分類,所以分類決策存在一定的錯誤率。
5)對輸入資料的表達形式很敏感。
step4
樸素貝葉斯演算法的應用
1、實時預測
樸素貝葉斯是一個非常快速的學習分類器,因此,它可以用於實時預測。
2、多類預測
可以預測多類目標變數的概率。
3、文字分類/垃圾郵件過濾/情感分析
樸素貝葉斯分類器對於多類問題和獨立性規則具有更高的成功率,因此,它被廣泛用於文字分類、垃圾郵件過濾和情感分析。
4、推薦系統
樸素貝葉斯分類器和協同過濾一起構建一個推薦系統,這有助於預測使用者是否願意提供資源。
Step5
在Python中使用Naive Bayes構建基本模型
同樣,scikit learn(python庫)將幫助在這裡用Python構建Naive Bayes模型。在scikit學習庫下有三種類型的樸素貝葉斯模型:
-高斯模型
它用於分類,假設特徵屬於某個類別的觀測值符合高斯分佈。在處理連續的特徵變數時,採用高斯模型。
-多項式模型
用於離散計數。例如,假設我們有文字分類問題。在這裡我們可以考慮更進一步的bernoulli試驗,而不是“在文件中出現的單詞”,我們“計算文件中出現單詞的頻率”,你可以將其視為“觀察到結果數x_i的次數”超過n次試驗“。
-伯努利模型
與多項式模型一樣,伯努利模型適用於離散特徵的情況,所不同的是,伯努利模型中每個特徵的取值只能是1和0(以文字分類為例,某個單詞在文件中出現過,則其特徵值為1,否則為0).
根據你的資料集,您可以選擇上面討論的任何模型。以下是高斯模型的示例。
Python 程式碼
#從高斯樸素貝葉斯模型到入庫
sklearn. naive _ bayes 中匯入 GaussianNB
import numpy as np
#分配預測變數和目標變數
x= np.array([[-3,7],[1,5], [1,2], [-2,0],[2,3], [-4,0], [-1,1], [1,1], [-2,2], [2,7], [-4,1], [-2,7]])
Y = np.array([3, 3, 3, 3, 4, 3, 3, 4, 3, 4,4, 4])
#建立高斯分類器
model = GaussianNB()
# 使用訓練集訓練模型
model.fit(x, y)
#預測輸出
predicted= model.predict([[1,2],[3,4]])
print predicted
Output: ([3,4])
以上就是學習樸素貝葉斯的五個簡單步驟,現在就開始學習吧!
歡迎關注公眾號:DC學習助手,探索資料科學之旅