
混淆矩陣(confusion matrix)理解
在機器學習中,當我們使用預先分配好的訓練集訓練好一個模型後,此時我們會使用預先分配好的測試集來檢測我們訓練好的這個模型怎麼樣?評價模型好壞的指標有很多,具體可以參見我以前的一篇部落格: 如何理解誤識率(FAR)拒識率(FRR),TPR,FPR以及ROC曲線,很常見的一個指標便是ROC曲線,它是在不同閾值的前提下以fpr以橫座標、tpr為縱座標的二維座標圖。
當我們用測試集去測試模型好壞時,輸出會是一個匹配分數矩陣,那怎麼根據這個匹配分數矩陣來判斷我們的測試集有沒有分對呢,常見的解決方案是我們將這個匹配分數矩陣裡的值從低到高分別設定為閾值,針對每一個閾值,與匹配分數矩陣同樣大小的標籤矩陣對比分別計算此時的tpr以及fpr,最後會得到一組tpr以及fpr值,根據這組tpr以及fpr值就可以畫出ROC曲線,由該ROC曲線就可以判斷我們模型的好壞。
閾值唯一確定之後,那麼我們的模型也就唯一確定了,針對測試集的輸入,fpr以及tpr也唯一確定,為了更好的視覺化我們的分類結果,我們引入混淆矩陣的概念。
在人工智慧中,混淆矩陣(confusion matrix)是視覺化工具,特別用於監督學習,在無監督學習一般叫做匹配矩陣。在影象精度評價中,主要用於比較分類結果和實際測得值,可以把分類結果的精度顯示在一個混淆矩陣裡面。混淆矩陣是通過將每個實測像元的位置和分類與分類影象中的相應位置和分類相比較計算的。
如有150個樣本資料,這些資料分成3類,每類50個。分類結束後得到的混淆矩陣為:
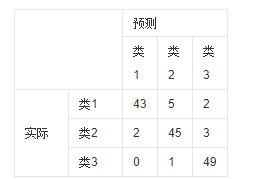
每一行之和為50,表示50個樣本,第一行說明類1的50個樣本有43個分類正確,5個錯分為類2,2個錯分為類3。
混淆矩陣的每一列代表了預測類別,每一列的總數表示預測為該類別的資料的數目;每一行代表了資料的真實歸屬類別,每一行的資料總數表示該類別的資料例項的數目。每一列中的數值表示真實資料被預測為該類的數目:如下圖,第一行第一列中的43表示有43個實際歸屬第一類的例項被預測為第一類,同理,第二行第一列的2表示有2個實際歸屬為第二類的例項被錯誤預測為第一類。
那麼針對以上的混淆矩陣,我們怎樣取計算fpr以及tpr值呢?
針對類1:共有150個測試樣本,類1為50個,那類2和類3就屬於其他樣本共為100個,此時 ;。嗯,該模型在fpr為0.02時,tpr達到了0.86,還算可以啊。
針對類2和類3:計算方式和類1一樣,這裡不再贅述。
ROC曲線一般針對的是二分類問題,那麼對於我們這裡的3分類問題怎樣畫ROC曲線,採取的策略是針對類1、類2以及類3這3個二分類器,分別計算其在特定閾值下fpr以及tpr的均值即可以畫ROC曲線。
相關推薦
混淆矩陣(confusion matrix)理解
在機器學習中,當我們使用預先分配好的訓練集訓練好一個模型後,此時我們會使用預先分配好的測試集來檢測我們訓練好的這個模型怎麼樣?評價模型好壞的指標有很多,具體可以參見我以前的一篇部落格: 如何理解誤識率(FAR)拒識率(FRR),TPR,FPR以及ROC曲線,很常
【模型評估】混淆矩陣(Confusion matrix)及其指標
混淆矩陣是對有監督學習分類演算法準確率進行評估的工具。通過將模型預測的資料與測試資料進行對比,使用各種指標對模型的分類效果進行度量。 true conditon 真實值 predicted con
置換矩陣(permutation matrix)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Leetcode演算法——54、螺旋矩陣(spiral matrix)
給定一個矩陣 m*n,返回所有元素的螺旋排列順序(從左上角開始,順時針旋轉,由外向內)。 示例1: Input: [ [ 1, 2, 3 ], [ 4, 5, 6 ], [ 7, 8, 9 ] ] Output: [1,2,3,6,9,8,7,4,5] 示例2:
【圖論】拉普拉斯矩陣(Laplacian matrix)
拉普拉斯矩陣是圖論中用到的一種重要矩陣,給定一個有n個頂點的圖 G=(V,E),其拉普拉斯矩陣被定義為 L = D-A,D其中為圖的度矩陣,A為圖的鄰接矩陣。例如,給定一個簡單的圖: 把此“圖”轉換為鄰接矩陣的形式,記為A: 把W的每一列元素加起來得到N個數,然後
【影象處理】海森矩陣(Hessian Matrix)及一個用例(影象增強)
前言 Hessian Matrix(海森矩陣)在影象處理中有廣泛的應用,比如邊緣檢測、特徵點檢測等。而海森矩陣本身也包含了大量的數學知識,例如泰勒展開、多元函式求導、矩陣、特徵值等。寫這篇部落格的目的,就是想從原理和實現上講一講Hessian Matr
黑塞矩陣(Hessian Matrix)
可見 lua 我們 obi show protobuf result rmi 解決 在機器學習課程裏提到了這個矩陣,那麽這個矩陣是從哪裏來,又是用來作什麽用呢?先來看一下定義: 黑塞矩陣(Hessian Matrix),又譯作海森矩陣、海瑟矩陣、海塞矩陣等,是一個多元函數
混淆矩陣(交叉表)及Kappa係數的計算
交叉分類表,是以兩個不同時期的地理實體型別為橫縱座標的表格。 ①用於參照的時期的型別位於表格的上方,按照橫方向排列 ②用以比較的時期的型別位於表格的左方,垂直排列 ③在橫縱座標上型別的排列順序一致 ④位於對角線上的方格中記錄的是兩個時期的資料集中
java計算混淆矩陣(分類指標:查準率P,查全率R,P和R的調和均值F1,正確率A)
【0】README 本文使用 java 計算混淆矩陣,並利用 混淆矩陣值計算 分類指標;通用分類指標有: 查準率,查全率,查準率和查全率的調和均值F1值,正確率, AOC, AUC等;本文計算前4個指標;(附原始碼和結果截圖) 【1】什麼是混淆矩陣(借用自己PPT截圖)
聊聊高並發(十九)理解並發編程的幾種"性" -- 可見性,有序性,原子性
sock clas 關註 條件 infoq zed 應該 單獨 ssa 這篇的主題本應該放在最初的幾篇。討論的是並發編程最基礎的幾個核心概念。可是這幾個概念又牽扯到非常多的實際技術。比方Java內存模型。各種鎖的實現,volatile的實現。原子變量等等,每個都可以展開
bzoj4165: 矩陣(堆+hash)
spl getch top urn sed puts opened -m || 求第k大用堆維護最值並出堆的時候擴展的經典題... 因為只有正數,所以一個矩陣的權值肯定比它的任意子矩陣的權值大,那麽一開始把所有滿足條件的最小矩陣加進堆裏,彈出的時候上下左右擴展一行
矩陣(待更)
archive AR 方法 hive .html arch TP ive www 矩陣構造方法 矩陣10題 矩陣(待更)
JVM理論:(二/4)理解GC日誌、垃圾收集器參數總結
相關 serial inf 說明 test 日誌 虛擬機啟動 cool 收集 JVM的GC日誌的主要參數包括如下幾個: -XX:+PrintGC 輸出GC日誌 -XX:+PrintGCDetails 輸出GC的詳細日誌 -XX:+PrintGCTimeStamps 輸出GC
BZOJ 1002 - 輪狀病毒 - [基爾霍夫矩陣(待補)+高精度][FJOI2007]
() out strlen esp lean 例如 計算 stream height 題目鏈接:https://www.lydsy.com/JudgeOnline/problem.php?id=1002 Description 輪狀病毒有很多變種,所有輪狀病毒的變種都是從
1050 螺旋矩陣 (25 分)
本題要求將給定的 N 個正整數按非遞增的順序,填入“螺旋矩陣”。所謂“螺旋矩陣”,是指從左上角第 1 個格子開始,按順時針螺旋方向填充。要求矩陣的規模為 m 行 n 列,滿足條件:m×n 等於 N;m≥n;且 m−n 取所有可能值中的最小值。 輸入格式: 輸入在第 1 行中給出一
JMeter聚合報告(Aggregate Report)理解
AggregateReport 是 JMeter 常用的一個 Listener,中文被翻譯為“聚合報告”。 對於每個請求,它統計響應資訊並提供請求數,平均值,最大,最小值,錯誤率,大約吞吐量(以請求數/秒為單位)和以kb/秒為單位的吞吐量. 聚合報告下方的圖是對上方的
1960 範德蒙矩陣(數學貪心)
1960 範德蒙矩陣 LYK最近在研究範德蒙矩陣與矩陣乘法,一個範德蒙矩陣的形式如下: 它想通過構造一個含有1~nm的n*m的矩陣G,使得G*V得到的n*n的矩陣T中所有
初夏小談:奇偶排隊,楊氏矩陣(查詢數字)大O階小於(N)
1.調整陣列使奇數全部都位於偶數前面。 #include<Aventador_SQ.h> #define ROW 100 void JiOuSort(int arr[ROW],int count) { int count1 = 0; int i = 0,j=0; int tem
協方差矩陣和相關係數矩陣(R語言)
一、協方差矩陣 1.協方差定義 &n
leetcode (Toeplitz Matrix)
Title:Toeplitz Matrix 766 Difficulty:Easy 原題leetcode地址:https://leetcode.com/problems/toeplitz-matrix/ 1.本題的行下標減去列下標