
遺傳演算法(四)MATLAB GA工具箱使用 附解TSP問題
基本使用
1. 直接參見函式ga
函式原型:[x fval] = ga(@fitnessfun, nvars, options)
x是使fitnessfun函式取最小值使的自變數值。nvars為自變數的數目即x向量中包含的元素個數,option可暫時不填。
[x, f] = ga(@cos, 1);即得到一段簡單的遺傳演算法程式碼,其作用為求解某函式的最小值。
如何調參:
x = ga(fitnessfcn,nvars,A,b,Aeq,beq,LB,UB,nonlcon,IntCon,options)- A, b,Aep, beq, LB, UB為線性約束項,即滿足如下約束:
- nonlcon為非線性約束nonlenear constraints。其中運用了向量化約束(Vectorized Constraints)的方法。nonlcon是一個返回兩個引數的函式控制代碼,可以是當前路徑下的一個函式檔案@functionfile。其具有如下原型:
[c ceq] = nonlcon(x)其約束為
具有三個變數的規劃中,有非線性約束:
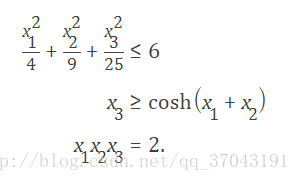
則其向量化約束函式nonlcon可以寫為:

IntCon:自變數向量正整數的下標,從1到nvars.
options: 比較複雜,感興趣的讀者可以去查一下幫助文件。在這裡舉例用幾個比較常用的option:
| 選項 | 功能 | 值 |
|---|---|---|
| CrossoverFraction | 交叉的概率 | 0-1的小數 |
| EliteCount | 用於精英原則, 每次遺傳中一定會活下來的個體的個數 |
正整數 |
| FitnessLimit | 適應度的範圍 | 標量/ {-Inf} |
| Generations | 迭代遺傳的次數 | 正整數 |
| InitialPopulation | 初始種群 | 可以用上一次遺傳生成的種群 作為下一次GA的初始種群 |
option中的功能要通過gaoptimset('param1',value1,'param2',value2,...)
再呼叫一個簡單的GA程式碼作結:
[x, f] = ga(@cos, 1, [], [], [], [], 0, 2 * pi, [], gaoptimset('CrossoverFraction', 0.3))示例,解組合優化
1. 解TSP
由於MATLAB提供了很好的遺傳演算法介面,故對於使用者來說只需要將問題抽象化,再進行編碼、解碼、計算適應度即可。
這裡直接給出適應度計算函式,包含編碼和解碼:
function Fitness = GA_TSPfun(chrom)
%% Create City
NumCity = 9;
Fitness = 0;
Dist =[0 2.8946 6.5107 5.5845 5.2429 5.8733 4.4377 2.7627 6.5644;
2.8946 0 4.3313 5.1381 5.7211 3.1830 2.3729 5.2763 5.0574;
6.5107 4.3313 0 3.6548 5.2943 1.8590 2.0889 9.2412 8.3103;
5.5845 5.1381 3.6548 0 1.7362 4.8792 3.3486 8.190210.1465;
5.2429 5.7211 5.2943 1.7362 0 6.2723 4.5224 7.531710.7633;
5.8733 3.1830 1.8590 4.8792 6.2723 0 1.8705 8.4338 6.4969;
4.4377 2.3729 2.0889 3.3486 4.5224 1.8705 0 7.1555 6.9906;
2.7627 5.2763 9.2412 8.1902 7.5317 8.4338 7.1555 0 7.1508;
6.5644 5.0574 8.310310.146510.7633 6.4969 6.9906 7.15080];
%% Decode:
order = [];
city = 1 : NumCity;
for j = 1 : NumCity
order = [order, city(1+rem( chrom(j)-1, length(city)))];
city(1 + rem(chrom(j)-1, length(city))) = [];
end
for i = 1 : NumCity
city1 = order(i);
city2 = order(1 + rem(i, NumCity));
Fitness = Fitness + Dist((city1-1)*NumCity + city2);
end
end經驗證發現,同樣的TSP問題,MATLAB的GAtools得出的解大多為31.7, 33左右,逼近最優解。但是前一篇中作者自己編寫的遺傳演算法程式,得出的平均結果為40左右。可見自己寫的程式碼爬山能力還不夠強,挖個坑,以後再研究一下。
相關推薦
遺傳演算法(四)MATLAB GA工具箱使用 附解TSP問題
基本使用 1. 直接參見函式ga 函式原型:[x fval] = ga(@fitnessfun, nvars, options) x是使fitnessfun函式取最小值使的自變數值。nvars為自變數的數目即x向量中包含的元素個數,option
圖——基本的圖演算法(四)關鍵路徑
圖——基本的圖演算法(四)關鍵路徑 1. 基本概念 (1)AOV網(Activity On Vertex Network) AOV網是一個表示工程的有向圖中,其中的頂點用來表示活動,弧則用來表示活動之間的優先關係。舉個簡單的例子,假定起床後可以邊煮水,邊刷牙洗臉,但洗臉要在刷牙後
從零開始學演算法(四)歸併排序
從零開始學演算法(四)歸併排序 歸併排序 演算法介紹 演算法原理 演算法簡單記憶說明 演算法複雜度和穩定性 程式碼實現 歸併排序 程式碼是Javascript語言寫的(幾乎是虛擬碼) 演算
Logistic迴歸之梯度上升優化演算法(四)
Logistic迴歸之梯度上升優化演算法(四) 從疝氣病症狀預測病馬的死亡率 1、實戰背景 我們使用Logistic迴歸來預測患疝氣病的馬的存活問題。原始資料集點選這裡下載。資料中一個包含了368個樣本和28個特徵。這種病不一定源自馬的腸胃問題,其他問題也可能引發疝氣病。該資料集中包含了
【尋優演算法】量子遺傳演算法(QGA) 引數尋優的python實現
【尋優演算法】量子遺傳演算法(QGA) 引數尋優的python實現 一、量子編碼 1、染色體量子編碼 2、量子編碼轉換為二進位制編碼 二、量子進化 1、全乾擾交叉 2、量子變異 三、QGA多引數
Python3實現機器學習經典演算法(四)C4.5決策樹
一、C4.5決策樹概述 C4.5決策樹是ID3決策樹的改進演算法,它解決了ID3決策樹無法處理連續型資料的問題以及ID3決策樹在使用資訊增益劃分資料集的時候傾向於選擇屬性分支更多的屬性的問題。它的大部分流程和ID3決策樹是相同的或者相似的,可以參考我的上一篇部落格:https://www.cnblogs.
深入理解JVM——配置引數(三);垃圾回收演算法(四)
深入理解JVM(三)——配置引數 1、跟蹤引數 2、堆分配引數 3、棧分配引數 這三類引數分別用於跟蹤監控JVM狀態,分配堆記憶體、棧記憶體。 跟蹤引數 跟蹤監控JVM,用於JVM調優以及故障排查。 1、當發生GC時,列印GC簡要資訊 使
js演算法(四)
輸入一個四位數,分解個十百千位上的數並輸出: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title>
Java資料結構和演算法(四)赫夫曼樹
Java資料結構和演算法(四)赫夫曼樹 哈夫曼樹又稱為最優二叉樹,赫夫曼樹的一個最主要的應用就是哈夫曼編碼。 一、赫夫曼樹 can you can a can as a can canner can a can. 1.1 定長編碼 99 97 110 32 121 111 117 32 99 97
java排序演算法(四)------希爾排序
希爾排序 希爾排序也是一種插入排序,它是簡單插入排序經過改進之後的一個更高效的版本,也稱為縮小增量排序,同時該演算法是衝破O(n2)的第一批演算法之一。 程式碼實現: /** *希爾排序的誕生是由於插入排序在處理大規模陣列的時候會遇到需要移動太多元素的問
演算法(四)散列表
雜湊查詢演算法 (一)用雜湊函式將被查詢的鍵轉化為陣列的索引 (二)處理碰撞衝突:拉鍊法和線性探測法 散列表是演算法在時間和空間上作出權衡的經典例子 雜湊函式 特點 (一)易於計算 (二)均勻分佈 基於拉鍊法的散列表 (一) 將大小為M的陣列中的每個元素指向一條
java排序演算法(四)------歸併排序
歸併排序: 是利用歸併的思想實現的排序方法,該演算法採用經典的分治(divide-and-conquer)策略(分治法將問題分(divide)成一些小的問題然後遞迴求解,而治(conquer)的階段則將分的階段得到的各答案"修補"在一起,即分而治之)。 合
線性規劃專題——SIMPLEX 單純形演算法(四)——實現
實現的原理見: 線性規劃專題——SIMPLEX 單純形演算法(一) 線性規劃專題——SIMPLEX 單純形演算法(二) 線性規劃專題——SIMPLEX 單純形演算法(三)——示例、注意點 實現過程 重點是實現PIVOT 指定主元的高斯約旦消元,以及INITICIALSIMPLEX
遺傳演算法(待續)
問題前瞻: 遺傳演算法為何稱為遺傳演算法? 編碼方式 目標函式 迭代方式 終止原則 名字由來 在二十世紀五十年代,生物學家已經知道基因在自然演化中的作用了,他們希望藉助計算機模擬這個過程,嘗試定量研究基因與進化之間的關係.這是遺傳演算法的濫觴.後來有人將
排序演算法(四)、選擇排序 —— 簡單選擇排序 和 堆排序
1、簡單選擇排序簡單選擇排序思想是:從頭到尾(從後往前也行)遍歷序列,先固定第一個位置的資料,將該位置後面的資料,依次和這個位置的資料進行比較,如果比固定位置的資料大,就交換。這樣,進行一趟排序以後,第一個位置就是最小的數了。然後重複進行,第 2 次遍歷並且比較後,第二個位置
標準粒子群演算法(PSO)matlab實現
標準PSO演算法的核心公式如下: 其中,w,c1,c2是預置好的: w稱為慣性權重,大小一般在[0.5,1.5]。 c1,c2稱為學習因子,一般取值[1,4],通常設定的c1=c2,但是c1與c2不必完全相同。 此實驗是在二維空間尋找最小值,設定多峰函式: z = x^2 + y-7c
基礎演算法(四)---深度優先搜尋(DFS)
深度優先搜尋演算法(Depth-First-Search),是搜尋演算法的一種。 它沿著樹的深度遍歷樹的節點,儘可能深的搜尋樹的分支。 當節點v的所有邊都己被探尋過,搜尋將回溯到發現節點v的那條邊的起始節點。這一過程一直進行到已發現從源節點可達
資料結構與演算法(四)二叉樹結構
1.二叉樹定義 樹結構產生的由來:為了解決陣列和連結串列在修改元素和查詢元素的複雜度上做平衡。樹是一種半線性結構,經過某種遍歷,即可確定某種次序。以平衡二叉搜尋樹為例,修改與查詢的操作複雜度均在O(logn)時間內完成。 樹的性質:連通無環圖,有唯一的根,每個節點到根的路徑唯一。有根有序性。
聚類演算法(四)、基於高斯混合分佈 GMM 的聚類方法(補充閱讀)
基於高斯混合分佈的聚類,我看了很多資料,,寫的千篇一律,一律到讓人看不明白。直到認真看了幾遍周志華寫的,每看一遍,都對 GMM 聚類有一個進一步的認識。所以,如果你想了解這一塊,別看亂七八糟的部落格了,直接去看周志華的《機器學習》 P206頁。 下面是我額外看的
排序演算法(四)——插入排序
插入排序(英語:Insertion Sort)是一種簡單直觀的排序演算法。通過對未排序的資料執行逐個插入至合適的位置而完成排序工作。 插入排序演算法的運作如下: 1.首先對陣列的前兩個資料進行從小到大的排序; 2.接著將第3個數據與排好序的兩個資料進行比較,將第三個資料插入合適的位置;