
資料探勘演算法之深入樸素貝葉斯分類
寫在前面的話:
我現在大四,畢業設計是做一個基於大資料的使用者畫像研究分析。所以開始學習資料探勘的相關技術。這是我學習的一個新技術領域,學習難度比我以往學過的所有技術都難。雖然現在在一家公司實習,但是工作還是挺忙的,經常要加班,無論工作多忙,還是決定要寫一個專欄,這個專欄就寫一些資料探勘演算法、資料結構、演算法設計和分析的相關文章。通過寫博文來督促自己不斷學習。以前對於數學沒有多大的興趣愛好,從小到大,學數學也是為了考試能考個好的成績,學過的很多數學知識,並沒有深刻的感受到它的用途,不用也就慢慢遺忘,但自從我看了數學之美這本書和開始學習資料探勘後,使我對數學有了很大的興趣。數學源於生活,用於生活。資料探勘中涉及到很多統計學、線性代數、微積分等相關知識,而我的很多數學知識都已經還給我以前的老師了,所以現在只能慢慢一點一點撿起來。要感謝網上有很多作者寫出的好的文章,讓我受益匪淺,也算是站在他們的肩膀上學習。減少了我的學習困難,而我今天開始寫的專欄裡的一系列文章,很多例子都是借鑑於他們文章中的例子。想了想,這個專欄名稱就叫<<演算法大雜燴>>
不一定每天都更會更新,但是肯定會堅持寫下去。
今天寫的第一篇博文,是關於樸素貝葉斯分類的。幾年前,我就聽說過這個演算法,只是稍微瞭解一點點,僅僅停留在只知道它是通過貝葉斯定理來分類的。寫這篇文章之前,我看了很多的相關知識,包括書籍和網上的一些優秀的博文。哈哈,到現在也應該算對於這個演算法入門了吧。後面的參考連結中會附上一些參考的文章地址。
樸素貝葉斯分類
引子
樸素貝葉斯分類是一種常用的分類演算法,他根據研究物件的某些特徵,來推斷出該研究物件屬於該研究領域的哪個類別。概述
要了解貝葉斯分類,必須瞭解貝葉斯定理,貝葉斯定理離不開條件概率 條件概率定義: 事件A在另外一個事件B已經發生條件下的發生概率。條件概率表示為P(A|B),讀作“在B條件下A的概率”。 根據文氏圖,可以很清楚地看到在事件B發生的情況下,事件A發生的概率就是P(A∩B)除以P(B)。

根據文氏圖,可以很清楚地看到在事件B發生的情況下,事件A發生的概率就是P(A∩B)除以P(B)。
P(A|B)=P(A∩B)/P(B)
因此,
P(A∩B)=P(A|B)P(B)
所以,
P(A|B)P(B)=P(B|A)P(A)
即
P(A|B)=P(B|A)P(A)/P(B)
病人疾病預測分類例子
看一個簡單的形式化的列子,來說明貝葉斯分類的作用 這個例子來自:阮一峰老師的介紹貝葉斯應用博文中的一個病人分類的例子 如下:其中特徵屬性是症狀和職業,類別是疾病(包括感冒,過敏、腦震盪) 某個醫院早上收了六個門診病人,如下表。 症狀 職業 疾病
打噴嚏 護士 感冒
打噴嚏 農夫 過敏
頭痛 建築工人 腦震盪
頭痛 建築工人 感冒
打噴嚏 教師 感冒
頭痛 教師 腦震盪現在又來了第七個病人,是一個打噴嚏的建築工人。請問他患上感冒的概率有多大? 根據貝葉斯定理: P(A|B) = P(B|A) P(A) / P(B) 可得
P(感冒|打噴嚏x建築工人)
= P(打噴嚏x建築工人|感冒) x P(感冒)
/ P(打噴嚏x建築工人)假定"打噴嚏"和"建築工人"這兩個特徵是獨立的,因此,上面的等式就變成了
P(感冒|打噴嚏x建築工人)
= P(打噴嚏|感冒) x P(建築工人|感冒) x P(感冒)
/ P(打噴嚏) x P(建築工人)這是可以計算的。
P(感冒|打噴嚏x建築工人)
= 0.66 x 0.33 x 0.5 / 0.5 x 0.33
= 0.66因此,這個打噴嚏的建築工人,有66%的概率是得了感冒。同理,可以計算這個病人患上過敏或腦震盪的概率。比較這幾個概率,就可以知道他最可能得什麼病。 這就是貝葉斯分類器的基本方法:在統計資料的基礎上,依據找到的一些特徵屬性,來計算各個類別的概率,找到概率最大的類,從而實現分類。
貝葉斯分類的定義
1、設為一個待分類項,而每個a為x的一個特徵屬性。
2、有類別集合。
3、計算。
4、求出在X個屬性條件下,所有類別的概率,選取概率最大的。則X屬於概率最大的類別
,則
。
根據貝葉斯定理,要求P(A|B),只要求出P(B|A)即可 .這裡Y指A,X指B.把B分解為各個特徵屬性,求出每個類別的每個特徵屬性即可,如下
1、找到一個已知分類的待分類項集合,這個集合叫做訓練樣本集。
2、統計得到在各類別下各個特徵屬性的條件概率估計。即。
3、如果各個特徵屬性是條件獨立的,則根據貝葉斯定理有如下推導:
因為分母對於所有類別為常數,因為我們只要將分子最大化皆可。又因為各特徵屬性是條件獨立的,所以有:
上式等號右邊的每一項,都可以從統計資料中得到,由此就可以計算出每個類別對應的概率,從而找出最大概率的那個類。
注意:各個特徵屬性是條件獨立的,這是樸素貝葉斯所要求的,如果各個特徵屬性不獨立,就不屬於樸素貝葉斯,屬於貝葉斯網路,後面的文章會講解。
賬號真假檢測例子
再看一個例子,該例子來自網上張陽的演算法雜貨鋪博文
根據某社群網站的抽樣統計,該站10000個賬號中有89%為真實賬號(設為C0),11%為虛假賬號(設為C1)。
C0 = 0.89
C1 = 0.11
接下來,就要用統計資料判斷一個賬號的真實性。假定某一個賬號有以下三個特徵:
F1: 日誌數量/註冊天數
F2: 好友數量/註冊天數
F3: 是否使用真實頭像(真實頭像為1,非真實頭像為0)F1 = 0.1
F2 = 0.2
F3 = 0
請問該賬號是真實賬號還是虛假賬號?
方法是使用樸素貝葉斯分類器,計算下面這個計算式的值。
P(F1|C)P(F2|C)P(F3|C)P(C)
雖然上面這些值可以從統計資料得到,但是這裡有一個問題:F1和F2是連續變數,不適宜按照某個特定值計算概率。
一個技巧是將連續值變為離散值,計算區間的概率。比如將F1分解成[0, 0.05]、(0.05, 0.2)、[0.2, +∞]三個區間,然後計算每個區間的概率。在我們這個例子中,F1等於0.1,落在第二個區間,所以計算的時候,就使用第二個區間的發生概率。
根據統計資料,可得:
P(F1|C0) = 0.5, P(F1|C1) = 0.1
P(F2|C0) = 0.7, P(F2|C1) = 0.2
P(F3|C0) = 0.2, P(F3|C1) = 0.9
因此,
P(F1|C0) P(F2|C0) P(F3|C0) P(C0)
= 0.5 x 0.7 x 0.2 x 0.89
= 0.0623P(F1|C1) P(F2|C1) P(F3|C1) P(C1)
= 0.1 x 0.2 x 0.9 x 0.11
= 0.00198
可以看到,雖然這個使用者沒有使用真實頭像,但是他是真實賬號的概率,比虛假賬號高出30多倍,因此判斷這個賬號為真。
貝葉斯分類的含義
長久以來,人們對一件事情發生或不發生的概率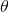
直到貝葉斯定理的出現,貝葉斯定理不把概率θ看做一個固定的值(比如上面取白球的概率一直都是1/2),而看做一個隨機變數,他會隨著觀察結果變化
貝葉斯及貝葉斯派提出了一個思考問題的固定模式:
- 先驗分佈
+ 樣本資訊
後驗分佈
上述思考模式意味著,新觀察到的樣本資訊將修正人們以前對事物的認知。換言之,在得到新的樣本資訊之前,人們對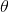
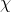
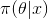
條件概率公式進行變形,可以得到如下形式:
P(A|B)=P(A) * P(B|A)/P(B)
我們把P(A)稱為"先驗概率",即在事件B發生之前,事件A發生的概率,在事件B發生之前,它是一個無條件分佈,因為A還沒有與事件B關聯上,他是先驗分佈。
P(A|B)稱為"後驗概率"(Posterior probability),即在B事件發生之後,我們對A事件概率的重新評估。P(B|A)/P(B)稱為"可能性函式"(Likelyhood),這是一個調整因子,使得預估概率更接近真實概率。它的分佈就是後驗分佈
所以,條件概率可以理解成下面的式子:
後驗概率 = 先驗概率 x 調整因子
這就是貝葉斯推斷的含義。我們先預估一個"先驗概率",然後加入實驗結果,看這個實驗到底是增強還是削弱了"先驗概率",由此得到更接近事實的"後驗概率"。
在這裡,如果"可能性函式"P(B|A)/P(B)>1,意味著"先驗概率"被增強,事件A的發生的可能性變大;如果"可能性函式"=1,意味著B事件無助於判斷事件A的可能性;如果"可能性函式"<1,意味著"先驗概率"被削弱,事件A的可能性變小。
水果糖問題例子
這個例子同樣來自阮一峰老師的博文,加深對貝葉斯推斷的理解

第一個例子。兩個一模一樣的碗,一號碗有30顆水果糖和10顆巧克力糖,二號碗有水果糖和巧克力糖各20顆。現在隨機選擇一個碗,從中摸出一顆糖,發現是水果糖。請問這顆水果糖來自一號碗的概率有多大?
我們假定,H1表示一號碗,H2表示二號碗。由於這兩個碗是一樣的,所以P(H1)=P(H2),也就是說,在取出水果糖之前,這兩個碗被選中的概率相同。因此,P(H1)=0.5,我們把這個概率就叫做"先驗概率",即沒有做實驗之前,來自一號碗的概率是0.5。
再假定,E表示水果糖,所以問題就變成了在已知E的情況下,來自一號碗的概率有多大,即求P(H1|E)。我們把這個概率叫做"後驗概率",即在E事件發生之後,對P(H1)的修正。
根據貝葉斯定理,得到
P(H1|E)=P(H1) * P(E|H1)/P(E)
已知,P(H1)等於0.5,P(E|H1)為一號碗中取出水果糖的概率,等於0.75,那麼求出P(E)就可以得到答案。根據全概率公式(不懂全概率公式的可以查詢相關資料理解),
P(E)=P(E|H1)
* P(H1) + P(E|H2)*P(H2)
所以,將數字代入原方程,得到
P(H1|E)=0.5* 0.75/0.625=0.6
這表明,來自一號碗的概率是0.6。也就是說,取出水果糖之後,H1事件的可能性得到了增強。
連續型特徵屬性和零概率事件處理
上面講的特徵屬性值,都是離散的,賬號真假檢測例子中把連續的轉換成區間,每個區間也可以看成離散的,但是如果在不能這樣轉換的情況下怎麼解決?如果特徵屬性值是不是離散的,而是連續的怎麼辦?
我們是站在巨人的肩膀上,前人早已經為我們找到了應對之策
當特徵屬性為連續值時,通常假定其值服從高斯分佈(也稱正態分佈)。即:
而
因此只要計算出訓練樣本中各個類別中此特徵項劃分的各均值和標準差,代入上述公式即可得到需要的估計值。(ak為觀察到的屬性值)
另一個需要討論的問題就是當P(a|y)=0怎麼辦,當某個類別下某個特徵項劃分沒有出現時,就是產生這種現象,這會令分類器質量大大降低。為了解決這個問題,引入了拉普拉斯校準,它的思想非常簡單,就是對沒類別下所有劃分(概率為零的)的計數加1,這樣如果訓練樣本集數量充分大時,並不會對結果產生影響,並且解決了上述頻率為零的尷尬局面。
買電腦是否和收入相關的例子
驗證買電腦,是否和收入有關的場景下:
類 buys_computer=yes包含1000個元組,有0個元組income=low ,990個元組 income=medium,10個元組income=high,這些事件的概率分別是0, 0.990, 0.010.
有概率為0,肯定不行.使用拉普拉斯校準,對每個收入-值對應加1個元組,分別得到如下概率
1/1003=0.001
991/1003=0.998
11/1003=0.011這些校準的概率估計與對應的未校準的估計很接近,但是避免了零概率值
性別分類的例子
再看一個阮一峰老師的樸素貝葉斯應用一文中摘自維基百科的例子,關於處理連續變數的另一種方法。
下面是一組人類身體特徵的統計資料。
性別 身高(英尺) 體重(磅) 腳掌(英寸)
男 6 180 12
男 5.92 190 11
男 5.58 170 12
男 5.92 165 10
女 5 100 6
女 5.5 150 8
女 5.42 130 7
女 5.75 150 9已知某人身高6英尺、體重130磅,腳掌8英寸,請問該人是男是女?
根據樸素貝葉斯分類器,計算下面這個式子的值。
P(身高|性別) x P(體重|性別) x P(腳掌|性別) x P(性別)
這裡的困難在於,由於身高、體重、腳掌都是連續變數,不能採用離散變數的方法計算概率。而且由於樣本太少,所以也無法分成區間計算。怎麼辦?
這時,可以假設男性和女性的身高、體重、腳掌都是正態分佈,通過樣本計算出均值和方差,也就是得到正態分佈的密度函式。有了密度函式,就可以把值代入,算出某一點的密度函式的值。
比如,男性的身高是均值5.855、方差0.035的正態分佈。所以,男性的身高為6英尺的概率的相對值等於1.5789(大於1並沒有關係,因為這裡是密度函式的值,只用來反映各個值的相對可能性)。

有了這些資料以後,就可以計算性別的分類了。
P(身高=6|男) x P(體重=130|男) x P(腳掌=8|男) x P(男)
= 6.1984 x e-9P(身高=6|女) x P(體重=130|女) x P(腳掌=8|女) x P(女)
= 5.3778 x e-4
可以看到,女性的概率比男性要高出將近10000倍,所以判斷該人為女性。
下一篇會寫貝葉斯網路。
參考文章:
http://www.ruanyifeng.com/blog/2011/08/bayesian_inference_part_one.html
http://www.ruanyifeng.com/blog/2013/12/naive_bayes_classifier.html
http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
http://blog.csdn.net/zdy0_2004/article/details/41096141
參考書籍:資料探勘概念與技術。資料探勘十大演算法,統計學概率論方面的數學知識
碼字不易,轉載請指明出自http://blog.csdn.net/tanggao1314/article/details/66478782
相關推薦
資料探勘演算法之深入樸素貝葉斯分類
寫在前面的話: 我現在大四,畢業設計是做一個基於大資料的使用者畫像研究分析。所以開始學習資料探勘的相關技術。這是我學習的一個新技術領域,學習難度比我以往學過的所有技術都難。雖然現在在一家公司實習,
【大資料分析常用演算法】4.樸素貝葉斯
開發十年,就只剩下這套架構體系了! >>>
【十九】機器學習之路——樸素貝葉斯分類
最近在看周志華《機器學習》的貝葉斯分類器這一章時覺得書上講的很難理解,很多專業術語和符號搞的我頭大,大學時候概率論我還是學的還是不錯的,無奈網上搜了搜前輩的部落格,看到一篇把樸素貝葉斯講的很簡單的文章,頓時豁然開朗。關於貝葉斯分類且聽我慢慢道來: 貝葉
資料探勘十大經典演算法(九) 樸素貝葉斯分類器 Naive Bayes
分類演算法--------貝葉斯定理: 樸素貝葉斯的基本思想:對於給出的待分類項,求解在此項出現的條件下各個類別出現的概率,哪個最大,就認為此待分類項屬於哪個類別。 可以看到,整個樸素貝葉斯分類分為三個階段: 第一階段——準備工作階段,這個階段的任務是為樸
資料探勘經典演算法總結-樸素貝葉斯分類器
貝葉斯定理(Bayes theorem),是概率論中的一個結果,它跟隨機變數的條件概率以及邊緣概率分佈有關。在有些關於概率的解說中,貝葉斯定理(貝葉斯更新)能夠告知我們如何利用新證據修改已有的看法。 通常,事件A在事件B(發生)的條件下的概率,與事件B在事件A的條件下的概率
資料探勘:基於樸素貝葉斯分類演算法的文字分類實踐
前言: 如果你想對一個陌生的文字進行分類處理,例如新聞、遊戲或是程式設計相關類別。那麼貝葉斯分類演算法應該正是你所要找的了。貝葉斯分類演算法是統計學中的一種分類方法,它利用概率論中的貝葉斯公式進行擴充套件。所以,這裡建議那些沒有概率功底或是對概率論已經忘記差不多的讀者可
資料探勘演算法之K_means演算法
轉載地址:https://blog.csdn.net/baimafujinji/article/details/50570824 聚類是將相似物件歸到同一個簇中的方法,這有點像全自動分類。簇內的物件越相似,聚類的效果越好。支援向量機、神經網路所討論的分類問題都是有監督的學習方式
資料探勘演算法之Apriori和FP-growth
1、基本概念 支援度(support):資料集中包含該項集的記錄所佔比例 置信度或可信度(confidence):主要是針對莫以具體的關聯規則進行定義的,如:{尿布}->{啤酒}的可信度可以被定義為:支援度{尿布、葡萄酒}/支援度{尿布} 2、Apr
資料探勘演算法之聚類分析(二)canopy演算法
canopy是聚類演算法的一種實現 它是一種快速,簡單,但是不太準確的聚類演算法 canopy通過兩個人為確定的閾值t1,t2來對資料進行計算,可以達到將一堆混亂的資料分類成有一定規則的n個數據堆 由於canopy演算法本身的目的只是將混亂的資料劃分成大概的幾個類別,所以它
資料探勘演算法之關聯規則挖掘(二)FPGrowth演算法
之前介紹的apriori演算法中因為存在許多的缺陷,例如進行大量的全表掃描和計算量巨大的自然連線,所以現在幾乎已經不再使用 在mahout的演算法庫中使用的是PFP演算法,該演算法是FPGrowth演算法的分散式執行方式,其內部的演算法結構和FPGrowth演算法相差並不是
資料探勘演算法之-關聯規則挖掘(Association Rule)
在資料探勘的知識模式中,關聯規則模式是比較重要的一種。關聯規則的概念由Agrawal、Imielinski、Swami 提出,是資料中一種簡單但很實用的規則。關聯規則模式屬於描述型模式,發現關聯規則的演算法屬於無監督學習的方法。 一、關聯規則的定義和屬性 考察一
【python資料探勘課程】二十一.樸素貝葉斯分類器詳解及中文文字輿情分析
這是《Python資料探勘課程》系列文章,也是我上課內容及書籍中的一個案例。本文主要講述樸素貝葉斯分類演算法並實現中文資料集的輿情分析案例,希望這篇文章對大家有所幫助,提供些思路。內容包括:1.樸素貝葉斯數學原理知識 2.naive_bayes用法及簡單案例 3.
詳解十大經典資料探勘演算法之——Apriori
本文始發於個人公眾號:**TechFlow**,原創不易,求個關注 今天是機器學習專題的第19篇文章,我們來看經典的Apriori演算法。 Apriori演算法號稱是十大資料探勘演算法之一,在大資料時代威風無兩,哪怕是沒有聽說過這個演算法的人,對於那個著名的啤酒與尿布的故事也耳熟能詳。但遺憾的是,隨著
分類演算法之樸素貝葉斯分類
原文http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html 0、寫在前面的話 我個人一直很喜歡演算法一類的東西,在我看
機器學習之實戰樸素貝葉斯演算法
貝葉斯分類是一類分類演算法的總稱,這類演算法均以貝葉斯定理為基礎,故統稱為貝葉斯分類,而樸素貝葉斯分類可謂是裡面最簡單、入門的一種。 首先關於貝葉斯定理,感覺簡單而偉大,前些天一直在看吳軍的數學之美(沒看過的極力推薦)系列文章,看到自然語言處理從規則模型到統計
機器學習經典演算法之樸素貝葉斯分類
很多人都聽說過貝葉斯原理,在哪聽說過?基本上是在學概率統計的時候知道的。有些人可能會說,我記不住這些概率論的公式,沒關係,我儘量用通俗易懂的語言進行講解。 /*請尊重作者勞動成果,轉載請標明原文連結:*/ /* https://www.cnblogs.com/jpcflyer/p/11069659
生成式學習演算法(四)之----樸素貝葉斯分類器
樸素貝葉斯分類器(演算法)與樸素貝葉斯假設 在高斯判別分析模型(GDA)中,特徵向量$ x$ 是連續實值向量。現在我們來討論分量$ x_j$ 取離散值的貝葉斯樸素貝葉斯模型。 在文字分類問題中,有一個問題是分出一個郵件是(\(y=1\) )或者不是(\(y=1\) )垃圾郵件。我們的訓練資料集是一些標好是否是
<Machine Learning in Action >之二 樸素貝葉斯 C#實現文章分類
options 直升機 water 飛機 math mes 視頻 write mod def trainNB0(trainMatrix,trainCategory): numTrainDocs = len(trainMatrix) numWords =
機器學習之路: python 樸素貝葉斯分類器 預測新聞類別
groups group news ckey put epo test electron final 使用python3 學習樸素貝葉斯分類api 設計到字符串提取特征向量 歡迎來到我的git下載源代碼: https://github.com/linyi0604/kag
sklearn庫學習之樸素貝葉斯分類器
樸素貝葉斯模型 樸素貝葉斯模型的泛化能力比線性模型稍差,但它的訓練速度更快。它通過單獨檢視每個特徵來學習引數,並從每個特徵中收集簡單的類別統計資料。想要作出預測,需要將資料點與每個類別的統計資料進行比較,並將最匹配的類別作為預測結果。 GaussianNB應用於任意連續資料,