
hadoop簡單例項-WordCount
本例項先貼原始碼,再講解步驟。
程式碼如下:
package test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache 執行測試:
一、 打包WordCount.java成jar包
兩種方法:
1. 採用javac 指令打包,因為程式依賴兩個jar包hadoop-core.1.2.1.jar,和commons-cli.1.2.jar。所以要指定依賴包的路徑。
#編譯WordCount.java 轉成.class
javac -classpath D:/lib/hadoop-core-1.2.1.jar:D:/lib/commons-cli.1.2.jar -d D:/output WordCount.java
#打包成jar包
jar -cvf wordcount.jar *.class 2.採用IDE來打包,這裡我使用的是eclipse。
建立專案,maven構建,或者建立普通java專案都可以(自行匯入依賴包),這裡我使用了maven構建專案。
pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.2</version>
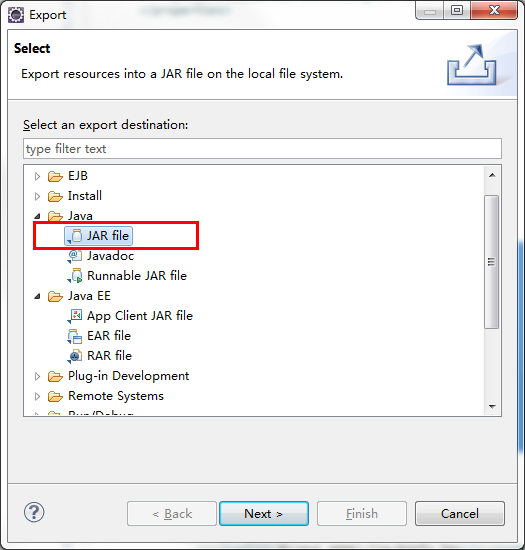
</dependency>點選WordCount.java右鍵Export。
選擇JAR file
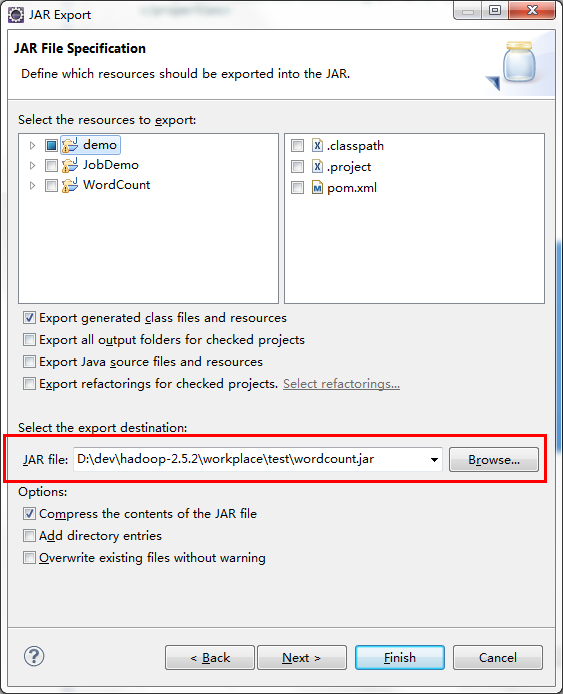
選擇匯入目錄
選擇程式主入口
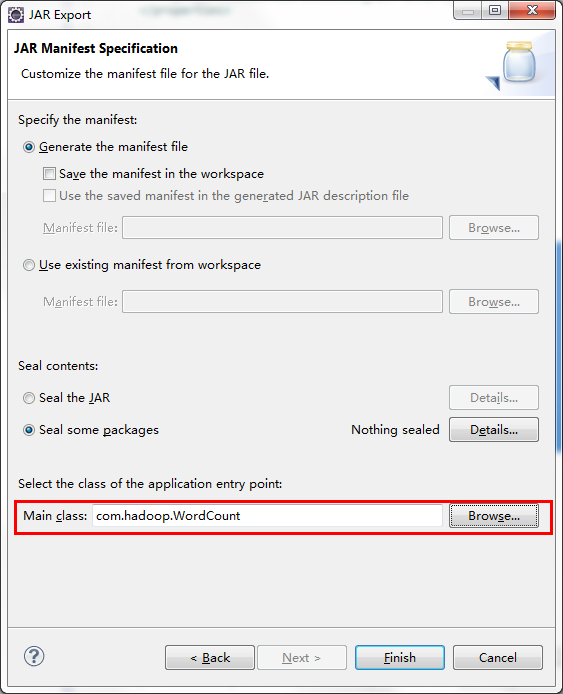
Finish即可。
二、 執行WordCount.jar
上篇文章中,我們已經在hadoop下建立了輸入目錄/user/wcinput,並上傳了2個txt文字檔案。
現在只需一個命令即可執行WordCount,cd切換到wordcount.jar包目錄,指定輸入目錄,和輸出目錄,回車。(output目錄,如果不存在,會自動建立,無需先mkdir建立目錄)
hadoop jar wordcount.jar hdfs://localhost:9000/user/wcinput hdfs://localhost:9000/user/output 
執行完畢後,執行命令:hadoop fs -ls 檢視output資料夾裡的檔案。
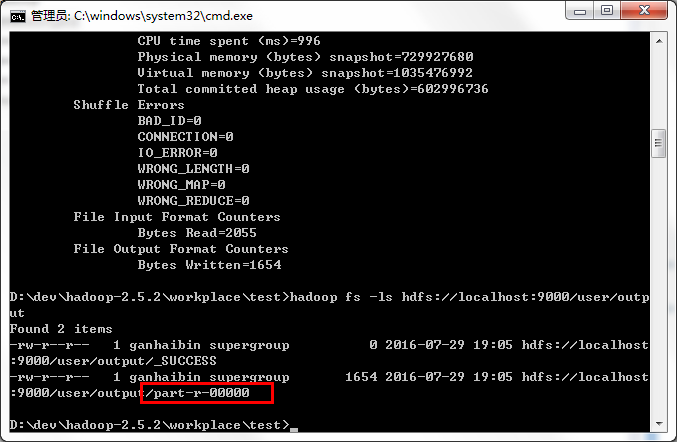
其中part-r-0000就是輸出結果檔案。
執行命令:hadoop fs -cat 開啟檔案檢視,結果如圖
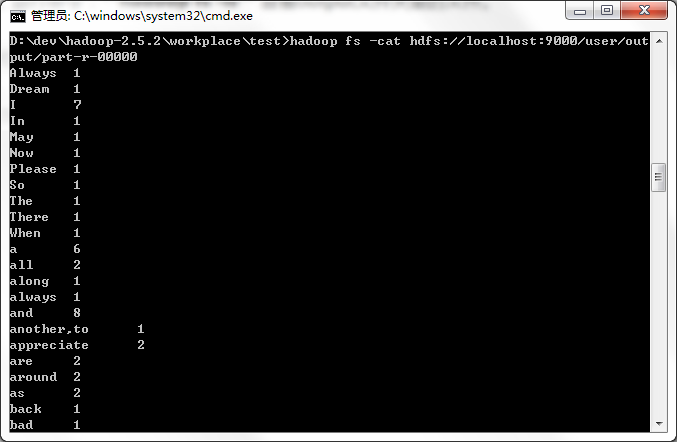
大功告成
第一個hadoop程式跑起來了,趕緊去試試看吧~
相關推薦
hadoop簡單例項-WordCount
本例項先貼原始碼,再講解步驟。 程式碼如下: package test; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.
Scala +Spark+Hadoop+Zookeeper+IDEA實現WordCount單詞計數(簡單例項)
IDEA+Scala +Spark實現wordCount單詞計數 一、新建一個Scala的object單例物件,修改pom檔案 (1)下面文章可以幫助參考安裝 IDEA 和 新建一個Scala程式。 (2)pom檔案 <?xml
Scala+Spark+Hadoop+IDEA實現WordCount單詞計數,上傳並執行任務(簡單例項-下)
Scala+Spark+Hadoop+IDEA上傳並執行任務 本文接續上一篇文章,已經在IDEA中執行Spark任務執行完畢,測試成功。 一、打包 1.1 將setMaster註釋掉 package day05 import
Hadoop基礎-MapReduce入門篇之編寫簡單的Wordcount測試程式碼
Hadoop基礎-MapReduce入門篇之編寫簡單的Wordcount測試程式碼 作者:尹正傑 版權宣告:原創作品,謝絕轉載!否則將追究法律責任。
Java通過Hadoop實現RPC通訊簡單例項
一、定義server端程式碼 1.定義一個介面,該介面繼承org.apache.hadoop.ipc.VersionedProtocol介面 import org.apache.hadoop.ipc.VersionedProtocol; /** * 1.伺服器定義介面
Hadoop第一個測試例項WordCount的執行
首先確保hadoop已經正確安裝、配置以及執行。 拷貝WordCount.java到我們的資料夾,下載的hadoop裡帶有WordCount.java,路徑為: hadoop-0.20.203.0/src/examples/org/apache/hadoop/example
hadoop學習(7)—— 使用yarn執行mapreduce一個簡單的wordcount示例
1.hdfs檔案系統目錄要求(建議) /user /{username} --使用者名稱 /mr
命令列執行hadoop例項wordcount程式
需要說明的有以下幾點。 1.如果wordcount程式不含層次,即沒有package 那麼使用如下命令: hadoop jar wordcount.jar WordCount2 /home/hadoop/input/20418.txt /home/hadoop/outp
Hadoop3 在eclipse中訪問hadoop並執行WordCount例項
前言: 畢業兩年了,之前的工作一直沒有接觸過大資料的東西,對hadoop等比較陌生,所以最近開始學習了。對於我這樣第一次學的人,過程還是充滿了很多疑惑和不解的,不過我採取的策略是還是先讓環境跑起來,然後在能用的基礎上在多想想為什麼。 通過這三個禮拜(基本上就是週六週日,其他時間都在
hadoop入門(六)JavaAPI+Mapreduce例項wordCount單詞計數詳解
剛剛研究了一下haoop官網單詞計數的例子,把詳細步驟解析貼在下面: 準備工作: 1、haoop叢集環境搭建完成 2、新建一個檔案hello,並寫入2行單詞,如下: [[email protected] hadoop-2.6.0]# vi hello hello
Hadoop例項WordCount程式修改--詞頻降序
修改wordcount例項,改為: 1、 對詞頻按降序排列 2、 輸出排序為前三,和後三的資料 首先是第一項: 對詞頻排序,主要針對的是最後輸出的部分。 ** 分析程式內容: ** WordCount.java package org.
hadoop常用演算法簡單例項
例項一、對以下資料進行排序,根據收入減去支出得到最後結餘從大到小排序,資料如下: SumStep執行之後結果如下: SortStep執行之後結果為上圖根據結餘從大到小排序。 程式碼如下: public class InfoBean implements Writabl
Hadoop Mapreduce之WordCount實現
註意 com split gin 繼承 [] leo ring exce 1.新建一個WCMapper繼承Mapper public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritab
004簡單介紹WordCount,統計文本單詞次數
override map() inter 根據 tasks mat import values com MapReduce簡介 MapReduce是一種分布式計算模型,主要解決海量數據的計算問題。 MR有兩個階段組成:Map和Reduce,用戶只需實現map()和redu
S2SH簡單例項註解版——登入功能實現
第一步:Spring4 整合 Hibernate4 Spring4 接管 Hibernate4 所有 Bean 例項,以及 SessionFactory,事務管理器; 泛型注入; Entity package com.java1234.entity; import j
簡單知識點例項之三:Bootstrap-Table和後臺進行百分百互動的簡單例項
這是一個針對前後臺互動的例子,可以直接套進專案中通暢執行。第二頁之所以資料不對,是因為例子畢竟沒有真正的後臺,所以資料不對。但是可以套入專案中,就正常了。 重點: 其中bootstrap-table有一個search:truse搜尋框的引數我沒有使用,而是自己寫了一個搜尋框,
express-session 簡單例項
express-session 例項 app.js var express = require('express'); var path = require('path'); var cookieParser = require('cookie-parser'); v
qt拖拽事件簡單例項
話不多說直接上程式碼,一看就懂 注意:當使用管理員許可權執行qt creator時,程式可能無法檢測到拖拽事件! widget.h 檔案 class Widget : public QWidget { Q_OBJECT public: explicit
Vue.js + Vue Router簡單例項
Vue.js + Vue Router簡單例項 使用 Vue.js ,我們已經可以通過組合元件來組成應用程式,當你要把 Vue Router 新增進來,我們需要做的是,將元件 (components) 對映到路由 (routes),然後告訴 Vue Router 在哪裡渲染它們。 1
WPF 路由事件簡單例項
在Winform窗體中,新增一個按鈕然後雙擊按鈕就可以在.cs程式碼自動生成有關事件的程式碼,這就是一個簡單的事件模型,但是如果對於大型的設計介面,數量過多的控制元件通過每次都生成相關的時間程式碼,將是一個好大的時間與控制元件的浪費,如何解決這個問題,可以用路由事件解決(通俗籠統的解釋,詳解自行查閱