
Scala +Spark+Hadoop+Zookeeper+IDEA實現WordCount單詞計數(簡單例項)
阿新 • • 發佈:2018-12-21
IDEA+Scala +Spark實現wordCount單詞計數
一、新建一個Scala的object單例物件,修改pom檔案
(1)下面文章可以幫助參考安裝 IDEA 和 新建一個Scala程式。
(2)pom檔案
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.mcb.scala02</groupId> <artifactId>scala02</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.10.5</scala.version> <spark.version>1.6.3</spark.version> <hadoop.version>2.7.5</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> </project>
二、Scala 程式碼
package day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable object SparkWordCount { def main(args: Array[String]): Unit = { //配置資訊類 //1,setAppName(任務名稱) setMaster(表示開啟多少個執行緒執行) val conf: SparkConf = new SparkConf().setAppName("SparkWordCount").setMaster("local[*]") //上下文物件 val sc: SparkContext = new SparkContext(conf) //讀取資料(資料通過陣列 args進入) val lines: RDD[String] = sc.textFile(args(0)) //處理資料 val map01: RDD[(String, Int)] = lines.flatMap(_.split(" ")).map((_,1)) val wordCount: RDD[(String, Int)] = map01.reduceByKey(_+_).sortBy(_._2,false) val wcToBuffer: mutable.Buffer[(String, Int)] = wordCount.collect().toBuffer println(wcToBuffer) sc.stop() } }
三、在伺服器上面啟動Hadoop的hdfs和spark(我這兒啟動的hdfs的高可用)
文章連結點選:
3.1 檢視Jps(三臺,其中centos01 為namenode,centos02是namenode,MyLinux是datanode)

3.2 web ui看一下hdfs 內部檔案
(1)web ui 顯示圖

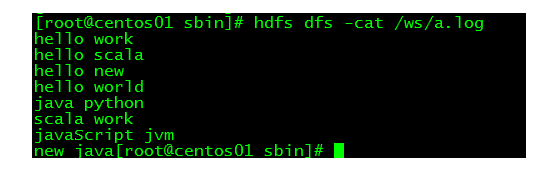
(2)檢視檔案內容(三個檔案均問以空格分割的單詞。)
3.3 IDEA 配置(傳參args)
(1)點選 右上角Edit Configurations

(2)新增application,名稱叫做SparkWordCount

3.4 執行結果(讀取並執行成功)~~~

完美~~
歡迎訂閱關注公眾號(JAVA和人工智慧)
獲取更多免費書籍、資源、視訊資料

文章超級連結: