
爬蟲基本原理介紹和初步實現(以抓取噹噹網圖書資訊為例)
本文程式碼等僅作學習記錄使用
一、爬蟲原理
網路爬蟲指按照一定的規則(模擬人工登入網頁的方式),自動抓取網路上的程式。簡單的說,就是講你上網所看到頁面上的內容獲取下來,並進行儲存。網路爬蟲的爬行策略分為深度優先和廣度優先。
(1)、深度優先
深度優先搜尋策略從起始網頁開始,選擇一個URL進入,分析這個網頁中的URL,選擇一個再進入。如此一個連結一個連結地抓取下去,直到處理完一條路線之後再處理下一條路線。深度優先策略設計較為簡單。然而入口網站提供的連結往往最具價值,PageRank也很高,但每深入一層,網頁價值和PageRank都會相應地有所下降。這暗示了重要網頁通常距離種子較近,而過度深入抓取到的網頁卻價值很低。同時,這種策略抓取深度直接影響著抓取命中率以及抓取效率,對抓取深度是該種策略的關鍵。
(2)、廣度優先:
廣度優先搜尋策略是指在抓取過程中,在完成當前層次的搜尋後,才進行下一層次的搜尋。該演算法的設計和實現相對簡單。在目前為覆蓋儘可能多的網頁,一般使用廣度優先搜尋方法。也有很多研究將廣度優先搜尋策略應用於聚焦爬蟲中。其基本思想是認為與初始URL在一定連結距離內的網頁具有主題相關性的概率很大。另外一種方法是將廣度優先搜尋與網頁過濾技術結合使用,先用廣度優先策略抓取網頁,再將其中無關的網頁過濾掉。這些方法的缺點在於,隨著抓取網頁的增多,大量的無關網頁將被下載並過濾,演算法的效率將變低。
二、抓取結構和規則
1.結構檢視
本文主要介紹基礎的抓取方式,以html格式為例
以噹噹網書籍頁面為例,如圖
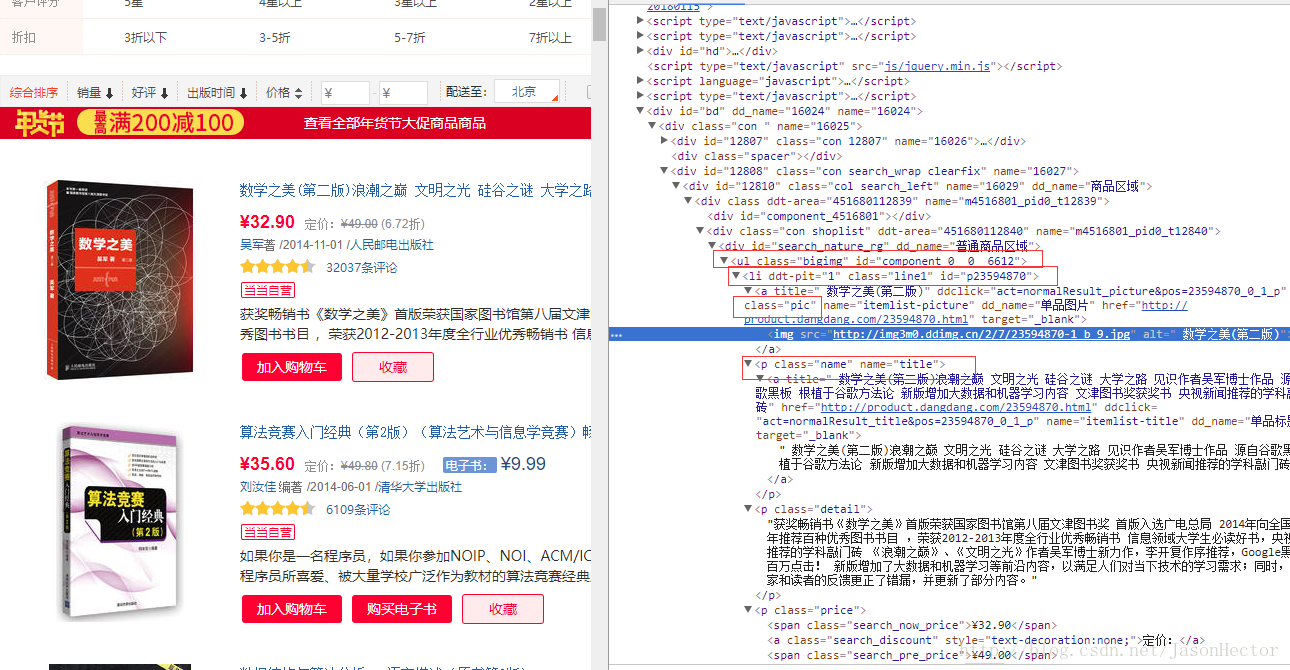
從圖中可以看出 ,網頁中的圖書列表是一個以 ul 開始的 li標籤遍歷列表
我們需要的就是每個li標籤中的資料,每個li標籤相當於一個java中的物件。
2.html資料規則
從上圖能看出每條資料外層都具備帶有class [CSS樣式]的標籤,如下圖
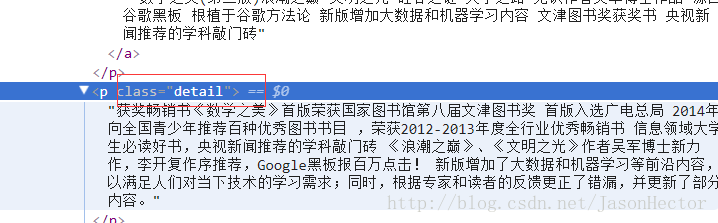
java 具有相對應的jar包來對html或xml資料結構進行解析,本文用的jar包為
三、程式碼實現
1.類展示
我用的springboot微框架 單純抓取的話直接寫main類就可以
(1)、model類
package com.weixin.model.book;
import com.weixin.model.BaseModel;
import 附帶公共類 BaseModel
package com.weixin.model;
import org.apache.ibatis.type.Alias;
import java.util.Date;
/**
* 基礎類
* create by frank
* on 2017/12/18
*/
public class BaseModel {
private int id;
private Date inputTime;
public Date getInputTime() {
return inputTime;
}
public void setInputTime(Date inputTime) {
this.inputTime = inputTime;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}
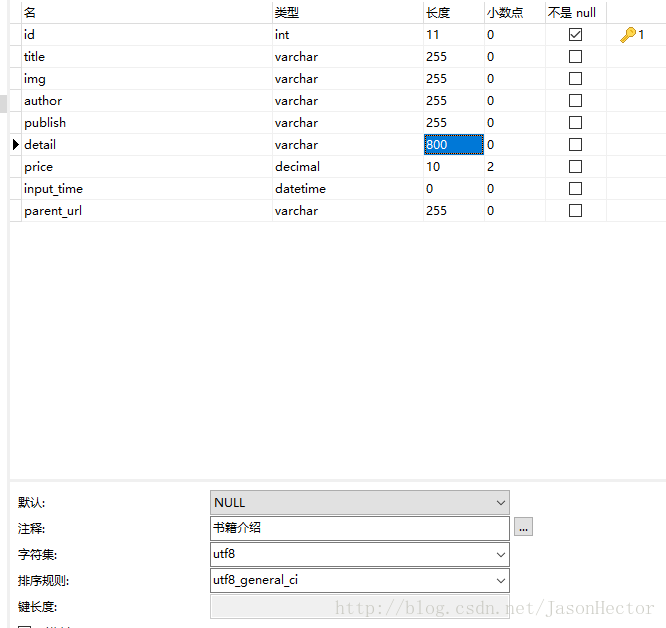
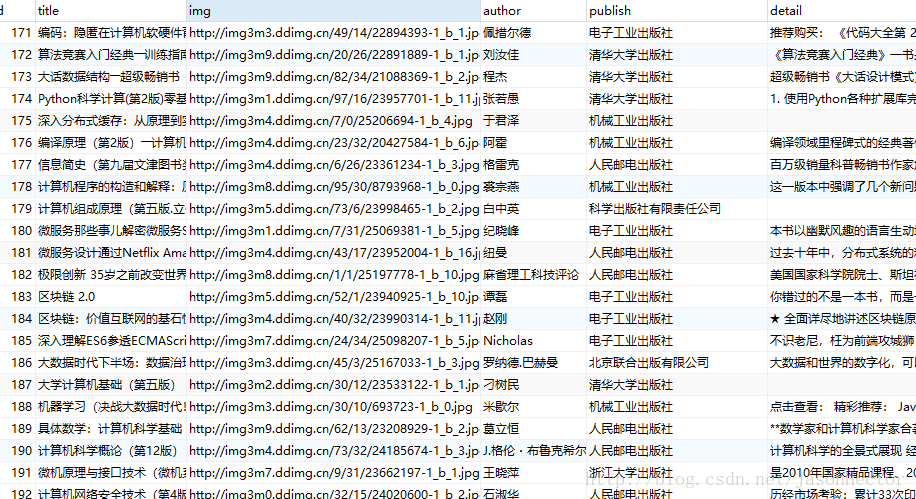
(2)、mapper 對映檔案(dao、service類省略)附帶資料庫表格,如圖
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="DangBook">
<insert id="insert" parameterType="dangBook">
INSERT INTO dd_book (title,img,author,publish,detail,price,input_time,parent_url)
VALUES
(#{title,jdbcType=VARCHAR},
#{img,jdbcType=VARCHAR},
#{author,jdbcType=VARCHAR},
#{publish,jdbcType=VARCHAR},
#{detail,jdbcType=VARCHAR},
#{price,jdbcType=NUMERIC},
#{inputTime,jdbcType=TIMESTAMP},
#{parentUrl,jdbcType=VARCHAR})
</insert>
</mapper>
(3)、連結請求工具類(根據url請求獲取html文字)
注意import 為apache包
package utils;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHttpResponse;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* http請求類
* create by frank
* on 2018/01/25
*/
public class HttpGetUtils {
private static Logger logger = LoggerFactory.getLogger(HttpGetUtils.class);
public static String getUrlContent(String url) {
if (url == null) {
logger.info("url地址為空");
return null;
}
logger.info("url為:" + url);
logger.info("開始解析");
String contentLine = null;
//最新版httpclient.jar已經捨棄new DefaultHttpClient()
//但是還是可以用的
HttpClient httpClient = new DefaultHttpClient();
HttpResponse httpResponse = getResp(httpClient, url);
if (httpResponse.getStatusLine().getStatusCode() == 200) {
try {
contentLine = EntityUtils.toString(httpResponse.getEntity(), "utf-8");
} catch (IOException e) {
e.printStackTrace();
}
}
logger.info("解析結束");
return contentLine;
}
/**
* 根據url 獲取response物件
*
* @param httpClient
* @param url
* @return
*/
public static HttpResponse getResp(HttpClient httpClient, String url) {
logger.info("開始獲取response物件");
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
try {
httpResponse = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
logger.info("獲取物件結束");
return httpResponse;
}
}
(4)、解析類(解析html獲取有用資料,重要類)
package utils;
import com.weixin.model.book.DangBook;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* 資料解析類 丁丁網圖集
* create by frank
* on 2018/01/25
*/
public class ParseUtils {
private static Logger logger = LoggerFactory.getLogger(ParseUtils.class);
public static List<DangBook> dingParse(String url) {
List<DangBook> list = new ArrayList<>();
Date date = new Date();
if (url == null) {
logger.info("url為空,資料獲取結束");
return null;
}
logger.info("開始獲取資料");
String content = HttpGetUtils.getUrlContent(url);
if (content != null)
logger.info("得到解析資料");
else {
logger.info("解析資料為空,資料獲取結束");
return null;
}
Document document = (Document) Jsoup.parse(content);
//遍歷噹噹圖書列表
for(int i =1;i<=60;i++){
Elements elements = document.select("ul[class=bigimg]").select("li[class=line"+i+"]");
for (Element e : elements) {
String title = e.select("p[class=name]").select("a").text();
logger.info("書名:" + title);
String img = e.select("a[class=pic]").select("img").attr("data-original");
logger.info("圖片地址:" + img);
String authorAndPublish = e.select("p[class=search_book_author]").select("span").select("a").text();
String []a = authorAndPublish.split(" ");
String author = a[0];
logger.info("作者:" + author);
String publish = a[a.length - 1];
logger.info("出版社:" + publish);
// String publish =e.select("p[class=name]").select("a").text();
String detail = e.select("p[class=detail]").text();
logger.info("圖書介紹:" + detail);
String priceS = e.select("p[class=price]").select("span[class=search_now_price]").text();
float price = Float.parseFloat(priceS.substring(1, priceS.length() - 1));
logger.info("價格:" + price);
logger.info("-------------------------------------------------------------------------");
DangBook dangBook = new DangBook();
dangBook.setTitle(title);
dangBook.setImg(img);
dangBook.setAuthor(author);
dangBook.setPublish(publish);
dangBook.setDetail(detail);
dangBook.setPrice(price);
dangBook.setInputTime(date);
dangBook.setParentUrl(url);
list.add(dangBook);
}
}
return list;
}
}
(5)、控制層類
package com.weixin.controller.book;
import com.alibaba.fastjson.JSONObject;
import com.weixin.model.book.DangBook;
import com.weixin.service.book.BookService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import utils.ParseUtils;
import utils.Test;
import java.util.List;
@RestController
@RequestMapping("/book")
public class BookController {
@Autowired
private BookService bookService;
private static Logger logger = LoggerFactory.getLogger(Test.class);
@RequestMapping("/parse")
public JSONObject parse(String url){
JSONObject jsonObject = new JSONObject();
List<DangBook> dangBooks = ParseUtils.dingParse(url);
if(dangBooks != null && dangBooks.size() >0){
logger.info("解析完資料,準備入庫");
bookService.insertBatch(dangBooks);
logger.info("入庫完成,入庫資料條數"+ dangBooks.size());
jsonObject.put("code",1);
jsonObject.put("result","success");
}else{
jsonObject.put("code",0);
jsonObject.put("result","fail");
}
return jsonObject;
}
}
以上就是完整的程式碼類
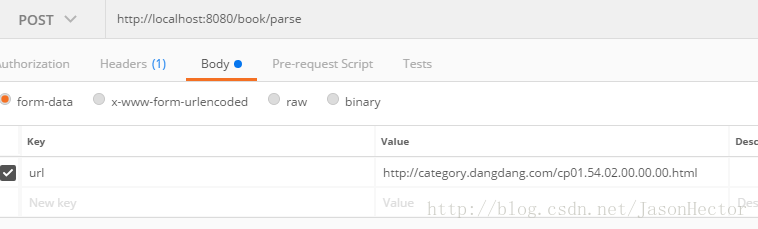
四、post man測試結果
1.請求方式 如圖
2.控制檯輸出
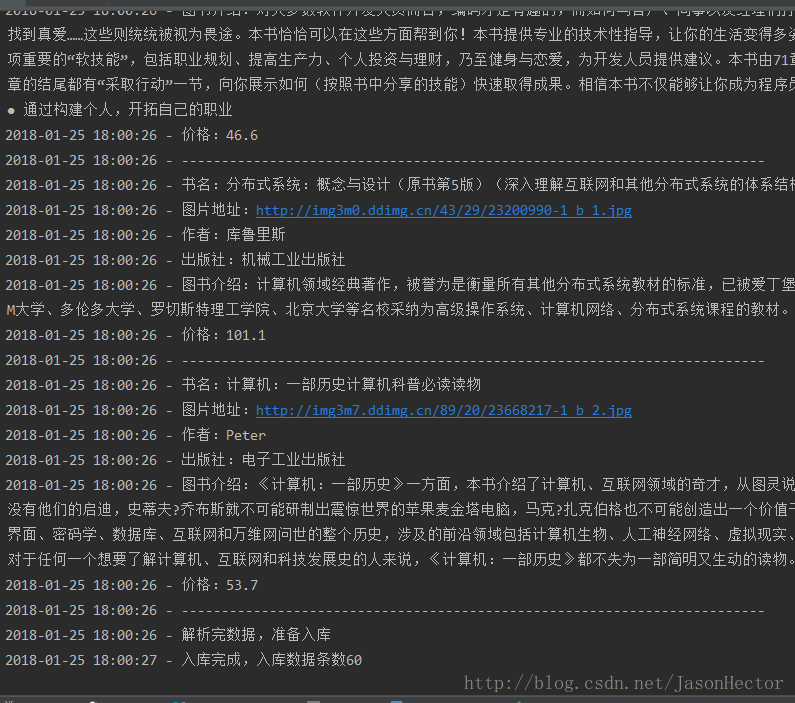
3、如上圖所示,最後執行入庫操作,檢視資料庫
我程式碼中的解析作者和出版社那邊程式碼有點小問題,導致解析部分沒有獲取到,這個具體就不改了,大體思路就是這樣
這種就算是最基本的資料爬取了,再深入就涉及到正則表示式、佇列、自動查詢等比較複雜的操作
五、總結
(1)、上述操作主要注意請求程式碼和資料解析程式碼,特別是資料解析
(2)、不同網站有不同的資料邏輯和結構,基本上不同網站都有特定的一套爬蟲規則
(3)、不少網站都設定反爬機制,想要得到更多資料還要進一步學習
(4)、雖然java有專門的封裝好的jar包進行解析,但是最為開發人員還是要去了解他的實現原理,懂得了最基本的才是最重要的,而不是依賴現成的東西。
相關推薦
爬蟲基本原理介紹和初步實現(以抓取噹噹網圖書資訊為例)
本文程式碼等僅作學習記錄使用 一、爬蟲原理 網路爬蟲指按照一定的規則(模擬人工登入網頁的方式),自動抓取網路上的程式。簡單的說,就是講你上網所看到頁面上的內容獲取下來,並進行儲存。網路爬蟲的爬行策略分為深度優先和廣度優先。 (1)、深度優先 深度
Python——使用高德API獲取POI(以深圳南山醫療保健服務POI為例)
tel range cnblogs 類別 ice index arch 獲取網頁 pla 以下內容為原創,轉載請註明出處。 1 import xlwt #創建Excel,見代碼行8,9,11,25,28;CMD下:運行pip install xlwt進行安裝 2 im
計算程序運行的時間(以求得1-10000之間的素數為例)
spa pen span 計算 sub 父類 println style 運行 //抽象類public abstract class Template { abstract void code();//要麽就聲明為實體方法,提供方法;要麽就加上abstract關鍵
設計模式-builder模式(以微信訊息的路由處理為例)
今天要講一個簡單的模式–builder模式。 你可能會覺得,builder模式有什麼好講的?本來我也這樣覺得,但當我有幸拜讀某位大神通過builder模式寫了一個開發工具包的初始化操作,嗯程式碼的樣子很叼 這位大神是誰呢? 就是這位仁兄啦,是碼雲上一個很火的微信開發工具包的貢獻者之一。
SpringMVC自定義註解進行引數校驗(以校驗列舉值是否合法為例)
pom引入springMVC依賴,以springboot專案為例 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-
2D的RPG遊戲人物角色移動程式碼(以egret遊戲引擎、TypeScript語言為例)
一般2D的RPG人物移動有三種: (一)背景固定,角色移動 (二)角色固定,背景移動 (三)角色移動,背景動態移動 第一種在移動端的遊戲比較少見,但在PC端的模擬類遊戲比較常見,因為螢幕較大,背景固定即可,角色在背景上移動;第二種在移動端比較多見,就是角色固定在螢幕中間
建立你的輸入法高階自定義短語(以PC版百度拼音輸入法為例)
由於我在Markdown寫作以及java程式碼中經常用到某些固定的短語,為此製作了自己的短語庫。比如通過輸入“sjx”就可以輸出“▲”、輸入“itable”就可以建立一個HTML語法的表格: PC版百度拼音輸入法的自定義短語功能的位置:
克魯斯卡爾重構樹 (以BZOJ 3732 Network,[NOI2018]歸程為例)
建樹方法 在克魯斯卡爾求最短路的基礎上對原來的圖進行一定的修改,與克魯斯卡爾求最短路的區別在於每當找到一條樹邊時,將其變成一個點,這個點連線這條邊連線的兩個聯通塊(的根節點),然後就可以得到一棵樹,這棵樹的葉子結點,其餘節點都是樹邊,權值就是樹邊的長度。
twemproxy0.4原理分析-基本原理介紹和優缺點分析
引言 接下來將會寫一個分析twemproxy的系列。該系列會對twemproxy最新版v0.4的原始碼進行分析,對設計原理進行剖析,力求用通俗的語言和圖來表達設計思想,並結合實際的使用達到深入淺出的效果。 概述 twemproxy是一個redis和memcached的輕量級分
模糊PID基本原理及matlab模擬實現(新手!新手!新手!)
有關模糊pid的相關知識就把自己從剛接觸到模擬出結果看到的大部分資料總結一下,以及一些自己的ps 以下未說明的都為轉載內容 在講解模糊PID前,我們先要了解PID控制器的原理(本文主要介紹模糊PID的運用,對PID控制器的原理不做詳細介紹)。PID控制器(比例
千萬級別資料的匯出到excel實現(以自己以前做的訂單匯出為demo給大家參考)
考慮幾個重點: 1,伺服器承載 2,redis資料快取避免資料重複匯出,3,匯出後的資料處理 4,死迴圈 5,資料大小,限制大變數的出現 遇到這樣的需求,大家根據自己的需求去處理業務,多方位去考慮程式的可執行性,效能等多方面因素(儘量減少迴圈中的查詢次數) 不多說附
python爬蟲遇到驗證碼的處理方法(以爬取中國執行資訊公開網為例)
朋友們大家好,python爬蟲是在學習python時比較容易上手的學習方式,爬蟲的思路簡要以下幾點: 1.獲取需要爬取頁面的網址,並且對網頁內容進行分析。(主要就原始碼討論,如果我們需要的內容沒有在原始碼出現,則需要進行抓包分析) 2.找到我們需要爬取的內容時我們
Scrapy爬蟲(5)爬取噹噹網圖書暢銷榜
本次將會使用Scrapy來爬取噹噹網的圖書暢銷榜,其網頁截圖如下: 我們的爬蟲將會把每本書的排名,書名,作者,出版社,價格以及評論數爬取出來,並儲存為csv格式的檔案。專案的具體建立就不再多講,可以參考上一篇部落格,我們只需要修改items.py檔
表單驗證時常用正則表示式(以“註冊資訊”為例)
個人在使用時看到網上總結的有很多了,但大多文章表述的都比較抽象,使用時需要自己組合,通常因為懶所以實際在用時習慣直接拿來用,總結的是本人寫程式的過程中用的頻率比較高的幾個例項: 另:這裡有一個博主總結的很不錯,連結貼上 /*驗證是否同意協議*/ function
Python 爬蟲第三步 -- 多執行緒爬蟲爬取噹噹網書籍資訊
XPath 的安裝以及使用 1 . XPath 的介紹 剛學過正則表示式,用的正順手,現在就把正則表示式替換掉,使用 XPath,有人表示這太坑爹了,早知道剛上來就學習 XPath 多省事 啊。其實我個人認為學習一下正則表示式是大有益處的,之所以換成 XPa
tensorflow 一個矩陣與多個矩陣相乘時的計算方法(二維和三維張量相乘為例)
當tensor1 的 shape 為[k, m, n], tensor2 的 shape 為 [n, p]時, 要將tensor1的後兩維構成的k個矩陣與tensor2中的矩陣做矩陣乘法得到 shape 為[k, m, p]的向量 解決辦法: 1,我們知道Tenso
python爬蟲——抓取自如網房源,匯出為csv
1.抓取自如網房源,其實為了後面一個小專案做資料採集工作 2.為什麼選擇自如,是因為我做租房的同學說,自如網的房源質量比較高 3.因為博主是暫居深圳,就先以深圳市的房源為示例 base_url = "http://sz.ziroom.com/z/nl/
Ubuntu 下cmake的安裝(以ubuntu14.0,cmake-3.14.0為例,其他版本也可進行參考)
down 返回 chm form 成功 ctrl+alt apt 指定 load 進入cmake的官網 https://cmake.org/download/ 以3.14.0版本為例可以發現,有很多種類型。如下圖: 大概的意思是“一般開放源代
雜湊表之簡易數學原理和簡易實現(史上最簡單易懂的雜湊表介紹)
什麼是雜湊表呢? 我先不說, 但其思想確實厲害。 下面, 我以最簡單易懂的方式來介紹雜湊表。 你要是去看教科書啊, 還沒有理解雜湊表的原理, 他就給你介紹近10種防衝突的方法, 這就是中國的教育。 你要是去網上搜點資料問為什麼雜湊表查詢的時間複雜
Django爬蟲基本原理及Request和Response分析
detail 密碼 href Go 模塊 ica 正則表達式 ons CI 一、爬蟲互聯網是由網絡設備(網線,路由器,交換機,防火墻等等)和一臺臺計算機連接而成,像一張網一樣。互聯網的核心價值在於數據的共享/傳遞:數據是存放於一臺臺計算機上的,而將計算機互聯到一起的目的就是