
統計一篇文章單詞的個數(map)
統計一篇英文文章中單詞出現的頻率(為簡單起見,假定依次從鍵盤輸入該文章)
關鍵字是string型別
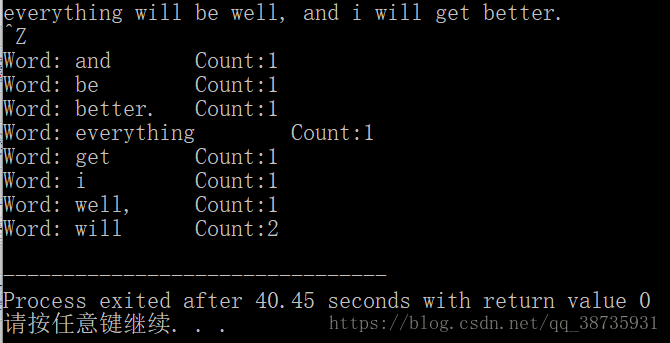
#include<bits/stdc++.h> using namespace std; int main() { map<string, int> wordCount; //map string word; //string while ( cin >> word ) ++wordCount[word]; //單詞頻率統計 map<string, int>::iterator it ; for ( it= wordCount.begin(); it != wordCount.end(); ++it) cout<<"Word: "<<(*it).first <<" \tCount:"<<(*it).second<<endl; return 0; }
輸出:
相關推薦
統計一篇文章單詞的個數(map)
統計一篇英文文章中單詞出現的頻率(為簡單起見,假定依次從鍵盤輸入該文章) 關鍵字是string型別 #include<bits/stdc++.h> using namespace std; int main() { map<string, int
資料庫的原理,一篇文章搞定(三)
合併聯接 合併聯接是唯一產生排序的聯接演算法。 注:這個簡化的合併聯接不區分內表或外表;兩個表扮演同樣的角色。但是真實的實現方式是不同的,比如當處理重複值時。 1.(可選)排序聯接運算:兩個輸入源都按照聯接關鍵字排序。 2.合併聯接運算:排序後的輸入源合併到一起。
一篇文章有若干行,以空行作為輸入結束的條件。統計一篇文章中單詞the(不管大小寫,單詞the是由空格隔開的)的個數。
#include <iostream>using namespace std; int k = 0;int n = 0;int main() { char c; char a[1000]; do { cin.get(c); if(c>='A'&
演算法之"統計一篇文章裡不同單詞的個數"
輸入: 有多組資料,每組一行,每行就是一篇文章。每篇小文章由小寫字母和空格組成,沒有標點符號,遇到#時表示輸入結束。 輸出: 每組輸入一個整數,其單獨成行,該整數代表一篇文章裡不同單詞的總數。 例如: hello world hello hi haha hh
Python - 統計一篇文章中單詞的頻率
readlines lis pre sta spl pen word lower pri def frenquence_statistic(file_name): frequence = {} for line in open(file_name,‘r‘)
統計一篇文章中各英語單詞出現的頻數
package com.icinfo; import java.io.*; import java.util.*; /** * 統計一個檔案中各詞出現的頻率,並列印 */ public class FileWordCount { // 使用HashMap來儲存單詞的頻率
統計一篇文章裡不同單詞的總數
Input 有多組資料,每組一行,每組就是一篇小文章。每篇小文章都是由小寫字母和空格組成,沒有標點符號,遇到#時表示輸入結束。 Output 每組只輸出一個整數,其單獨成行,該整數代表一篇文章裡不同單詞的總數。 和uva10815感覺差不多,只是需要對每一行進行一
Java實現統計一篇文章中每個單詞出現的次數
import java.io.File; import java.io.FileReader; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; import jav
Java統計一篇文章中出現次數最多的漢字或英文單詞 又出現次數的統計
思想是用到了Map集合的鍵唯一性儲存漢字或者單詞,單詞的獲取通過正則獲取: 統計類: import java.util.ArrayList; import java.util.Map; import java.util.Set; import java.util.Tree
統計一行文字的單詞個數 (15 分) 本題目要求編寫程式統計一行字元中單詞的個數。所謂“單詞”是指連續不含空格的字串,各單詞之間用空格分隔,空格數可以是多個。 輸入格式: 輸入給出一行字元。 輸出格式: 在一行中輸出單詞個數。 輸入樣例: Let's go to room 209. 輸出樣例
MD,一開始就想著怎麼 用空格和結尾前判斷字母 來計算寫的頭的爆了, 反過來判斷空格後面是否有 =‘ ’就尼瑪容易多了 #include<stdio.h> #include<stdlib.h> #include<string.h> int
習題6-8 統計一行文字的單詞個數 (15 point(s))
習題6-8 統計一行文字的單詞個數 (15 point(s)) 本題目要求編寫程式統計一行字元中單詞的個數。所謂“單詞”是指連續不含空格的字串,各單詞之間用空格分隔,空格數可以是多個。 輸入格式: 輸入給出一行字元。 輸出格式: 在一行中輸出單詞個數。 輸入樣例: Let
水一水 )統計一行文字的單詞個數 (15 分)(c語言)
7-2 統計一行文字的單詞個數 (15 分) 本題目要求編寫程式統計一行字元中單詞的個數。所謂“單詞”是指連續不含空格的字串,各單詞之間用空格分隔,空格數可以是多個。 輸入格式: 輸入給出一行字元。 輸出格式: 在一行中輸出單詞個數。 輸入樣例: Let’s go
7-2 統計一行文字的單詞個數 (15 分)
7-2 統計一行文字的單詞個數 (15 分) 本題目要求編寫程式統計一行字元中單詞的個數。所謂“單詞”是指連續不含空格的字串,各單詞之間用空格分隔,空格數可以是多個。 輸入格式: 輸入給出一行字元。 輸出格式: 在一行中輸出單詞個數。 輸入樣例: Let’s go to room
android webview一篇文章全面瞭解(基本使用,url攔截,js跟java互動)
1.前言 最近幾年混合應用越來越流行,及一部分功能用原生程式碼開發,一部分功能用html5實現。那什麼時候用原生什麼時候用網頁呢?很多人第一反應就是經常變化的頁面用網頁開發,避免經常發包,不全對。其實因為網頁使用體驗遠遠不及原生開發,所以一般有以下兩種情況建議
資料庫的原理,一篇文章搞定(一)
https://blog.csdn.net/zhangcanyan/article/details/51439012 一提到關係型資料庫,我禁不住想:有些東西被忽視了。關係型資料庫無處不在,而且種類繁多,從小巧實用的 SQLite 到強大的 Teradata 。但很少有文章講解資料庫是如何工作的。你可以自己
習題6-8 統計一行文字的單詞個數(15 分)
本題目要求編寫程式統計一行字元中單詞的個數。所謂“單詞”是指連續不含空格的字串,各單詞之間用空格分隔,空格數可以是多個。輸入格式:輸入給出一行字元。輸出格式:在一行中輸出單詞個數。輸入樣例:Let's go to room 209. 輸出樣例:5#include<std
習題6-8 統計一行文字的單詞個數 (15 分)
本題目要求編寫程式統計一行字元中單詞的個數。所謂“單詞”是指連續不含空格的字串,各單詞之間用空格分隔,空格數可以是多個。 輸入格式: 輸入給出一行字元。 輸出格式: 在一行中輸出單詞個數。 輸入樣例: Let’s go to room 209. 輸出樣例: 5 #includ
Mapreduce例項---統計單詞個數(wordcount)
一:問題介紹 統計每一個單詞在整個資料集中出現的總次數。 資料流程: 二:需要的jar包 Hadoop-2.4.1\share\hadoop\hdfs\hadoop-hdfs-2.4.1.ja
統計一篇文章中出現次數最多的前k個詞,文章中一行一詞
應該考慮檔案大小和詞的多少,有一個1G大小的一個檔案,裡面每一行是一個詞,詞的大小不超過16位元組,記憶體限制大小是1M。返回頻數最高的100
Java中的多執行緒你只要看這一篇就夠了(轉)
引 如果對什麼是執行緒、什麼是程序仍存有疑惑,請先Google之,因為這兩個概念不在本文的範圍之內。 用多執行緒只有一個目的,那就是更好的利用cpu的資源,因為所有的多執行緒程式碼都可以用單執行緒來實現。說這個話其實只有一半對,因為反應“多角色”的程式程式碼,最起碼每個角色要給他一個執行緒吧,否