
Mapreduce例項---統計單詞個數(wordcount)
阿新 • • 發佈:2019-02-10
一:問題介紹
統計每一個單詞在整個資料集中出現的總次數。
資料流程:
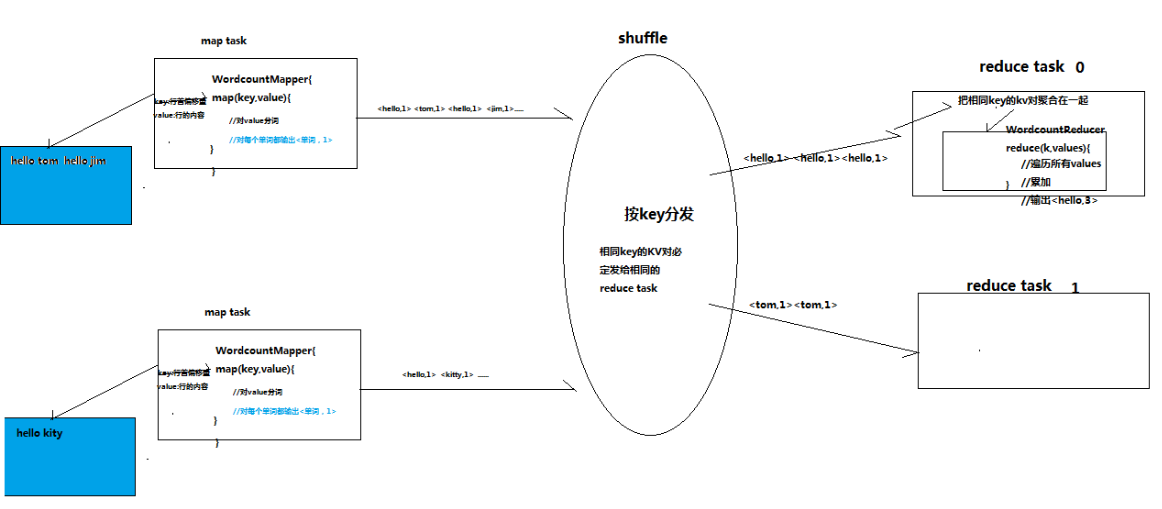
二:需要的jar包
Hadoop-2.4.1\share\hadoop\hdfs\hadoop-hdfs-2.4.1.jar
hadoop-2.4.1\share\hadoop\hdfs\lib\所有jar包
hadoop-2.4.1\share\hadoop\common\hadoop-common-2.4.1.jar
hadoop-2.4.1\share\hadoop\common\lib\所有jar包
hadoop-2.4.1\share\hadoop\mapreduce\除hadoop-mapreduce-examples-2.4.1.jar之外的jar包
hadoop-2.4.1\share\hadoop\mapreduce\lib\所有jar包
三:程式碼
mapper類實現:
/* * KEYIN:輸入kv資料對中key的資料型別 * VALUEIN:輸入kv資料對中value的資料型別 * KEYOUT:輸出kv資料對中key的資料型別 * VALUEOUT:輸出kv資料對中value的資料型別 */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /* * map方法是提供給map task程序來呼叫的,map task程序是每讀取一行文字來呼叫一次我們自定義的map方法 * map task在呼叫map方法時,傳遞的引數: * 一行的起始偏移量LongWritable作為key * 一行的文字內容Text作為value */ @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { //拿到一行文字內容,轉換成String 型別 String line = value.toString(); //將這行文字切分成單詞 String[] words=line.split(" "); //輸出<單詞,1> for(String word:words){ context.write(new Text(word), new IntWritable(1)); } } }
reducer類實現:
/* * KEYIN:對應mapper階段輸出的key型別 * VALUEIN:對應mapper階段輸出的value型別 * KEYOUT:reduce處理完之後輸出的結果kv對中key的型別 * VALUEOUT:reduce處理完之後輸出的結果kv對中value的型別 */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override /* * reduce方法提供給reduce task程序來呼叫 * * reduce task會將shuffle階段分發過來的大量kv資料對進行聚合,聚合的機制是相同key的kv對聚合為一組 * 然後reduce task對每一組聚合kv呼叫一次我們自定義的reduce方法 * 比如:<hello,1><hello,1><hello,1><tom,1><tom,1><tom,1> * hello組會呼叫一次reduce方法進行處理,tom組也會呼叫一次reduce方法進行處理 * 呼叫時傳遞的引數: * key:一組kv中的key * values:一組kv中所有value的迭代器 */ protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { //定義一個計數器 int count = 0; //通過value這個迭代器,遍歷這一組kv中所有的value,進行累加 for(IntWritable value:values){ count+=value.get(); } //輸出這個單詞的統計結果 context.write(key, new IntWritable(count)); } }
job提交客戶端實現:
public class WordCountJobSubmitter {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job wordCountJob = Job.getInstance(conf);
//重要:指定本job所在的jar包
wordCountJob.setJarByClass(WordCountJobSubmitter.class);
//設定wordCountJob所用的mapper邏輯類為哪個類
wordCountJob.setMapperClass(WordCountMapper.class);
//設定wordCountJob所用的reducer邏輯類為哪個類
wordCountJob.setReducerClass(WordCountReducer.class);
//設定map階段輸出的kv資料型別
wordCountJob.setMapOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
//設定最終輸出的kv資料型別
wordCountJob.setOutputKeyClass(Text.class);
wordCountJob.setOutputValueClass(IntWritable.class);
//設定要處理的文字資料所存放的路徑
FileInputFormat.setInputPaths(wordCountJob, "hdfs://192.168.77.70:9000/wordcount/srcdata/");
FileOutputFormat.setOutputPath(wordCountJob, new Path("hdfs://192.168.77.70:9000/wordcount/output/"));
//提交job給hadoop叢集
wordCountJob.waitForCompletion(true);
}
}四:操作流程
1、將專案打成jar包上傳到虛擬機器上


2、建立文字資料

3、將文字資料上傳到hdfs

4、執行jar檔案
5、結果
