
給solr配置中文分詞器
Solr的中文分詞器
- 中文分詞在solr裡面是沒有預設開啟的,需要我們自己配置一箇中文分詞器。
- 目前可用的分詞器有smartcn,IK,Jeasy,庖丁。其實主要是兩種,一種是基於中科院ICTCLAS的隱式馬爾科夫HMM演算法的中文分詞器,如smartcn,ictclas4j,優點是分詞準確度高,缺點是不能使用使用者自定義詞庫;另一種是基於最大匹配的分詞器,如IK ,Jeasy,庖丁,優點是可以自定義詞庫,增加新詞,缺點是分出來的垃圾詞較多。各有優缺點。
- 面給出兩種分詞器的安裝方法,任選其一即可,推薦第一種,因為smartcn就在solr發行包的contrib/analysis-extras/lucene-libs/下,就是lucene-analyzers-smartcn-4.2.0.jar,首選在solrconfig.xml中加一句引用analysis-extras的配置,這樣我們自己加入的分詞器才會引到的solr中。
smartcn 分詞器的安裝
1.首選將發行包的contrib/analysis-extras/lucene-libs/ lucene-analyzers-smartcn-4.2.0.jar複製到\solr\contrib\analysis-extras\lib下,在solr_home資料夾下
2.開啟/ims_advertiesr_core/conf/scheme.xml,編輯text欄位型別如下,新增以下程式碼到scheme.xml中的相應位置,就是找到fieldType定義的那一段,在下面多新增這一段就好啦
<fieldType name="text_smartcn" class 如果需要檢索某個欄位,還需要在scheme.xml下面的field中,新增指定的欄位,用text_ smartcn作為type的名字,來完成中文分詞。如 text要實現中文檢索的話,就要做如下的配置:
<field name ="text" type ="text_smartcn" indexed ="true" stored ="false" multiValued ="true"/>IK 分詞器的安裝
IKAnalyzer2012FF_u1.jar //分詞器jar包
IKAnalyzer.cfg.xml //分詞器配置檔案
stopword.dic //分詞器停詞字典,可自定義新增內容- 將IKAnalyzer2012FF_u1.jar 加入C:\apache-tomcat-7.0.57\webapps\solr\WEB-INF\lib中。
- 在C:\apache-tomcat-7.0.57\webapps\solr\WEB-INF下新建classes資料夾,將IKAnalyzer.cfg.xml、keyword.dic、stopword.dic加入classes裡。
- 然後就可以像smartcn一樣進行配置scheme.xml了
<!-- 配置IK分詞器start -->
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>中文分詞器mmseg4j
mmseg4j-solr-2.3.0支援solr5.3
1.將兩個jar包考入tomcat中solr專案裡的lib檔案內
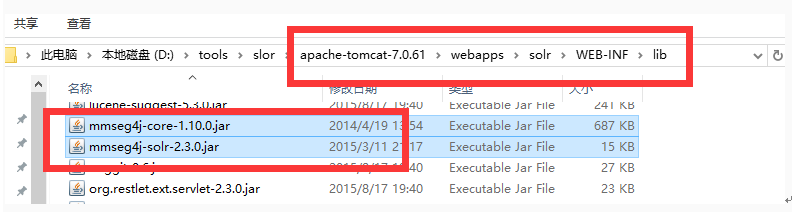
2.配置solr_home中的schema.xml
在下面標籤
<fieldType name="currency" class="solr.CurrencyField" precisionStep="8" defaultCurrency="USD" currencyConfig="currency.xml" /></fieldType>
裡新增:
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/>
</analyzer>
</fieldtype>
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldtype>
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="n:/custom/path/to/my_dic" />
</analyzer>
</fieldtype>重啟tomcat測試分詞
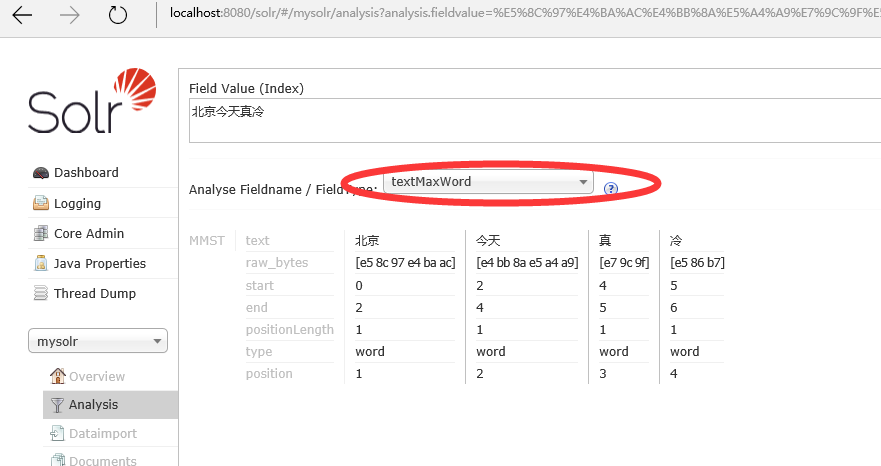
在schema.xml裡定義:
<field name="content_test" type="textMaxWord" indexed="true" stored="true" multiValued="true"/>然後測試:
相關推薦
給solr配置中文分詞器
Solr的中文分詞器 中文分詞在solr裡面是沒有預設開啟的,需要我們自己配置一箇中文分詞器。 目前可用的分詞器有smartcn,IK,Jeasy,庖丁。其實主要是兩種,一種是基於中科院ICTCLA
Solr 配置中文分詞器 IK
host dex text class get mar con png 網址 1. 下載或者編譯 IK 分詞器的 jar 包文件,然後放入 ...\apache-tomcat-8.5.16\webapps\solr\WEB-INF\lib\ 這個 lib 文件目錄下;
Solr配置中文分詞器IK Analyzer詳解
歡迎掃碼加入Java高知群交流 配置的過程中出現了一些小問題,一下將詳細講下IK Analyzer的配置過程,配置非常的簡單,但是首先主要你的Solr版本是哪個,如果是3.x版本的用IKAnalyzer2012_u6.zip如果是4.x版本的用IK Analyzer 20
二、Solr配置中文分詞器IKAnalyzer並配置業務域
一、solr域的介紹 在solr中域的概念與lucene中域的概念相同,資料庫的一條記錄或者一個檔案的資訊就是一個document,資料庫記錄的欄位或者檔案的某個屬性就是一個Field域,solr中對索引的檢索也是對Field的操作。lucene中對域的操作是通過程式碼,solr對域的管理是通過一個配置檔案
Solr-4.10 配置中文分詞器(IKAnalyzer)
1、下載IKAnalyzer http://pan.baidu.com/s/1i3eXhAH 密碼:34w6 2、將ik的相關檔案 拷貝到 webapps\solr\WEB-INF\lib 目錄下 3、引入相應詞典配置放到&
Solr學習總結 IK 配置中文分詞器
預設solr沒有使用中文分詞器 所有搜尋的詞都是整個句子是一個詞 需要配置中文分詞器目前比較好用的是IK 但2012就停更了 只支援到Lucene4.7所有solr5.5需要Lucene5支援需要修改部分原始碼來支援solr5.5找到IKAnalyze類 <dep
Solr-6.5.1配置中文分詞器smartcn
solr的同步發行包smartcn可進行中文切詞,smartcn的分詞準確率不錯,但就是不能自己定義新的詞庫,不過smartcn是跟solr同步的,所以不需要額外的下載,只需在solr的例子中拷貝進去即可。 第一步: 找到如下目錄,複製中文分詞器jar到so
Solr之配置中文分詞器
1、使用solr自帶分詞器 1.1、拷貝Jar包 cp /opt/solr/solr-7.3.1/contrib/analysis-extras/lucene-libs/lucene-ana
Solr 5.0.0配置中文分詞器IK Analyzer
Solr版本和IK分詞版本一定對應 (ps我版本沒對應好弄了快倆小時了) 只適合Solr 5.0.0版本 1.下載IK分詞器包 連結: https://pan.baidu.com/s/1hrXovly 密碼: 7yhs 2.解壓並把IKAnalyzer-5.0.jar 、solr-analyzer-extra
Solr 7.2.1 配置中文分詞器 IK Analyzer
一、什麼是中文分詞器? 為什麼不來個英文分詞器呢? “嘿,小夥子,就是你,說的就是你,你那麼有才咋不上天呢!” 首先我們來拽一句英文:“He is my favorite NBA star”
solr與中文分詞器的安裝配置
準備環境: solr版本:Solr4.10.3 jdk:1.8 Tomcat:apache-tomcat-7.0.59 一、solr和tomcat整合使用: 1.solr和tomcat整合 1、將Solr4.10.3 壓縮包內的dist目錄下的solr-4.10.3.w
solrcloud配置中文分詞器ik
lte config server field per str load fonts textfield 無論是solr還是luncene,都對中文分詞不太好,所以我們一般索引中文的話需要使用ik中文分詞器。 三臺機器(192.168.1.236,192.168.1.237
ElasticSearch搜索引擎安裝配置中文分詞器IK插件
art linux系統 nal smart 分享 內容 分詞 search dcl 一、IK簡介 ElasticSearch(以下簡稱ES)默認的分詞器是標準分詞器Standard,如果直接使用在處理中文內容的搜索時,中文詞語被分成了一個一個的漢字,因此引入中文分詞器IK就
solr配置IK分詞器報錯
new_core: org.apache.solr.common.SolrException:org.apache.solr.common.SolrException: JVM Error creating core [new_core]: class org.wltea.analy
Solr6.0.1配置中文分詞器mmseg4j
1、下載mmseg4j包和所需dic檔案 2、配置mmseg4j中文分詞器 在solrhome中建立dic資料夾,並將dic欄位檔案複製進去 將mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar放到
solr配置中文分詞遇到的問題
嚴重: Servlet.service() for servlet [default] in context with path [/solr] threw exception [Filter execution threw an exception] with root
(四)Solr6.4.1配置中文分詞器IK Analyzer詳解
Solr6.4.1配置中文分詞器IK Analyzer詳解 2.把IKAnalyzer.cfg.xml,mydict.dic,stopword.dic這三個檔案複製放入tomcat/solr專案web-info的classes下 3.把ik-analyz
配置中文分詞器 IK-Analyzer-Solr7
剛才 tokenize .org 參考 apps https 標簽 manage con 先下載solr7版本的ik分詞器,下載地址:http://search.maven.org/#search%7Cga%7C1%7Ccom.github.magese分詞器GitHub源
Solr安裝及中文分詞器配置
1、上傳並解壓Solr、Tomcat 2、複製Solr到Tomcat cp -r solr-7.3.1/server/solr-webapp/webapp /home/tomcat/webapps/solr 3、複製jar包到Tomcat下的Solr cp -
solr 6.2.0系列教程(二)IK中文分詞器配置及新增擴充套件詞、停止詞、同義詞
前言 2、solr的不同版本,對應不同版本的IK分詞器。由於IK 2012年停止更新了。所以以前的版本不適合新版的solr。 有幸在網上扒到了IK原始碼自己稍微做了調整,用來相容solr6.2.0版本。IK原始碼下載地址 步驟 1、解壓下載的src.rar壓縮包,這是我建