
Solr 5.0.0配置中文分詞器IK Analyzer
Solr版本和IK分詞版本一定對應 (ps我版本沒對應好弄了快倆小時了)
只適合Solr 5.0.0版本
1.下載IK分詞器包
連結: https://pan.baidu.com/s/1hrXovly 密碼: 7yhs
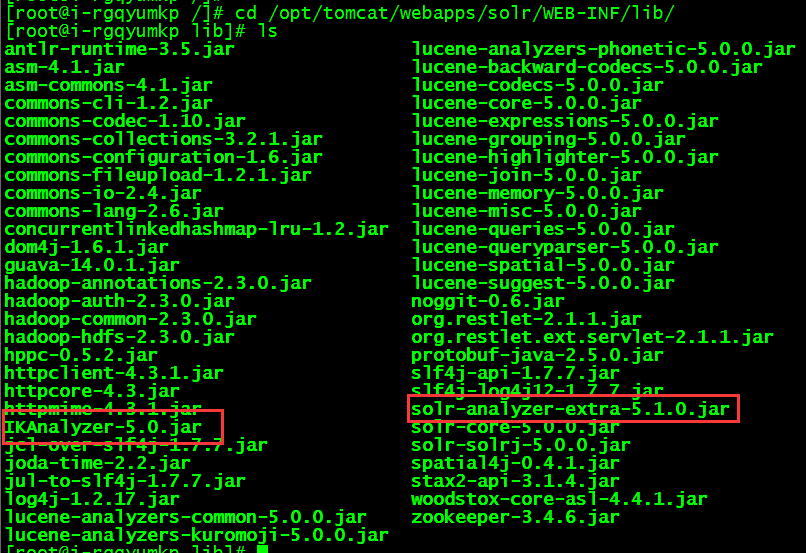
2.解壓並把IKAnalyzer-5.0.jar 、solr-analyzer-extra-5.1.0.jar拷貝到tomcat/webapps/solr/WEB-INF/lib下
網盤下載加壓後

伺服器tomcat/webapps/solr/WEB-INF/lib下
3.修改schema.xml配置檔案,如下:
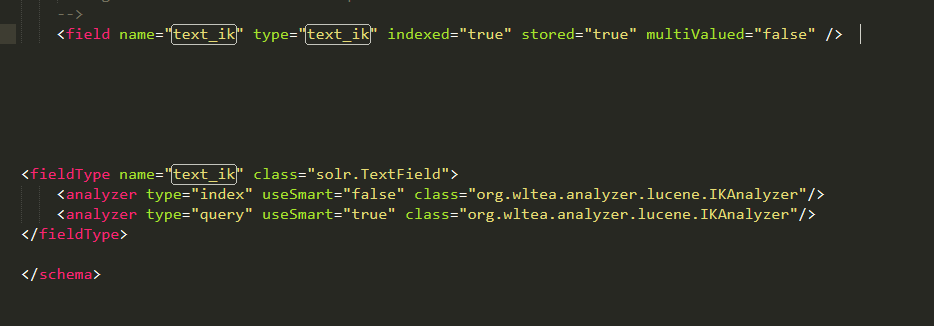
修改完成之後儲存並重啟solr伺服器。
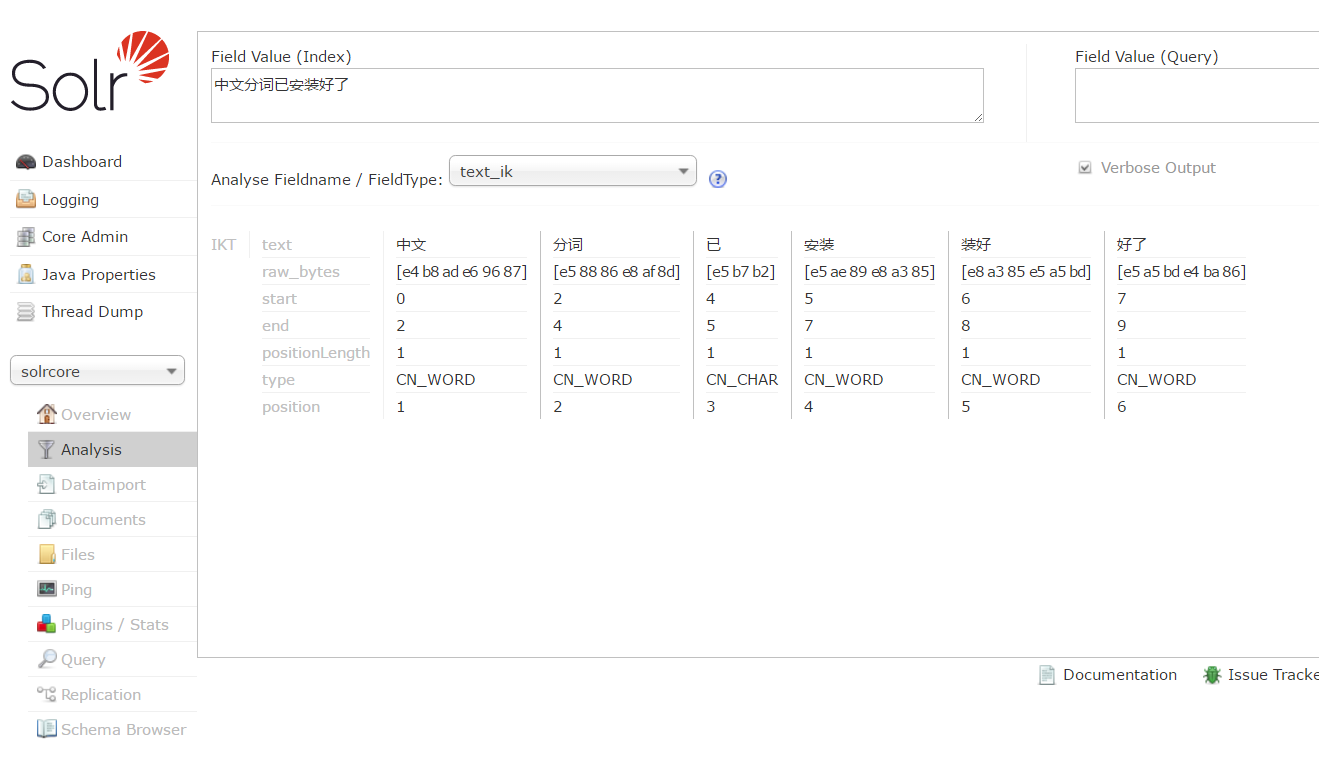
4,開啟solr管理介面,檢視執行結果
相關推薦
Solr 7.2.1 配置中文分詞器 IK Analyzer
一、什麼是中文分詞器? 為什麼不來個英文分詞器呢? “嘿,小夥子,就是你,說的就是你,你那麼有才咋不上天呢!” 首先我們來拽一句英文:“He is my favorite NBA star”
Solr 5.0.0配置中文分詞器IK Analyzer
Solr版本和IK分詞版本一定對應 (ps我版本沒對應好弄了快倆小時了) 只適合Solr 5.0.0版本 1.下載IK分詞器包 連結: https://pan.baidu.com/s/1hrXovly 密碼: 7yhs 2.解壓並把IKAnalyzer-5.0.jar 、solr-analyzer-extra
Solr配置中文分詞器IK Analyzer詳解
歡迎掃碼加入Java高知群交流 配置的過程中出現了一些小問題,一下將詳細講下IK Analyzer的配置過程,配置非常的簡單,但是首先主要你的Solr版本是哪個,如果是3.x版本的用IKAnalyzer2012_u6.zip如果是4.x版本的用IK Analyzer 20
(四)Solr6.4.1配置中文分詞器IK Analyzer詳解
Solr6.4.1配置中文分詞器IK Analyzer詳解 2.把IKAnalyzer.cfg.xml,mydict.dic,stopword.dic這三個檔案複製放入tomcat/solr專案web-info的classes下 3.把ik-analyz
配置中文分詞器 IK-Analyzer-Solr7
剛才 tokenize .org 參考 apps https 標簽 manage con 先下載solr7版本的ik分詞器,下載地址:http://search.maven.org/#search%7Cga%7C1%7Ccom.github.magese分詞器GitHub源
Solr6.0.1配置中文分詞器mmseg4j
1、下載mmseg4j包和所需dic檔案 2、配置mmseg4j中文分詞器 在solrhome中建立dic資料夾,並將dic欄位檔案複製進去 將mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar放到
Solr 配置中文分詞器 IK
host dex text class get mar con png 網址 1. 下載或者編譯 IK 分詞器的 jar 包文件,然後放入 ...\apache-tomcat-8.5.16\webapps\solr\WEB-INF\lib\ 這個 lib 文件目錄下;
solrcloud配置中文分詞器ik
lte config server field per str load fonts textfield 無論是solr還是luncene,都對中文分詞不太好,所以我們一般索引中文的話需要使用ik中文分詞器。 三臺機器(192.168.1.236,192.168.1.237
ElasticSearch搜索引擎安裝配置中文分詞器IK插件
art linux系統 nal smart 分享 內容 分詞 search dcl 一、IK簡介 ElasticSearch(以下簡稱ES)默認的分詞器是標準分詞器Standard,如果直接使用在處理中文內容的搜索時,中文詞語被分成了一個一個的漢字,因此引入中文分詞器IK就
Solr-6.5.1配置中文分詞器smartcn
solr的同步發行包smartcn可進行中文切詞,smartcn的分詞準確率不錯,但就是不能自己定義新的詞庫,不過smartcn是跟solr同步的,所以不需要額外的下載,只需在solr的例子中拷貝進去即可。 第一步: 找到如下目錄,複製中文分詞器jar到so
Solr-4.10 配置中文分詞器(IKAnalyzer)
1、下載IKAnalyzer http://pan.baidu.com/s/1i3eXhAH 密碼:34w6 2、將ik的相關檔案 拷貝到 webapps\solr\WEB-INF\lib 目錄下 3、引入相應詞典配置放到&
Solr學習總結 IK 配置中文分詞器
預設solr沒有使用中文分詞器 所有搜尋的詞都是整個句子是一個詞 需要配置中文分詞器目前比較好用的是IK 但2012就停更了 只支援到Lucene4.7所有solr5.5需要Lucene5支援需要修改部分原始碼來支援solr5.5找到IKAnalyze類 <dep
給solr配置中文分詞器
Solr的中文分詞器 中文分詞在solr裡面是沒有預設開啟的,需要我們自己配置一箇中文分詞器。 目前可用的分詞器有smartcn,IK,Jeasy,庖丁。其實主要是兩種,一種是基於中科院ICTCLA
Solr之配置中文分詞器
1、使用solr自帶分詞器 1.1、拷貝Jar包 cp /opt/solr/solr-7.3.1/contrib/analysis-extras/lucene-libs/lucene-ana
二、Solr配置中文分詞器IKAnalyzer並配置業務域
一、solr域的介紹 在solr中域的概念與lucene中域的概念相同,資料庫的一條記錄或者一個檔案的資訊就是一個document,資料庫記錄的欄位或者檔案的某個屬性就是一個Field域,solr中對索引的檢索也是對Field的操作。lucene中對域的操作是通過程式碼,solr對域的管理是通過一個配置檔案
Linux下ElasticSearch6.4.x、ElasticSearch-Head、Kibana以及中文分詞器IK的安裝配置
ElasticSearch 安裝配置 下載 # 官網下載壓縮包 [[email protected] /home]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.
Elasticsearch 5.X為index指定中文分詞器ik
Elasticsearch用於json格式資料的全文檢索十分方便,但是需要一些時間來熟悉和配置。最權威的配置說明在官方文件這裡,但是由於是英文的,而且新概念和內容十分多,初學者往往不容易找到解決問題的辦法。筆者解決這篇文章中的問題就花了2天時間,所以記錄下來,方便初學者查閱。
ElasticSearch 6.5.4 安裝中文分詞器 IK和pinyiin
ES的常用的中文分詞有基於漢字的ik和基於拼音的pinyin https://github.com/medcl/elasticsearch-analysis-ik/releases https://github.com/medcl/elasticsearch-analysis-pinyi
Elasticsearch 中文分詞器IK
1、安裝說明 https://github.com/medcl/elasticsearch-analysis-ik 2、release版本 https://github.com/medcl/elasticsearch-analysis-ik/releases 3、安裝外掛 bin/elasti
第二節 Elasticsearch加入中文分詞器IK
一、簡介 Elasticsearch 內建的分詞器是standard對英文分詞還好,但對中文的支援就比較弱,所以需要另 外引入一箇中文分詞器。目前比較流行的中文分詞器有: IKAnalyzer 、 MMSeg4j、 Paoding等