
論文筆記|Towards End-to-End Lane Detection: an Instance Segmentation
用盡量少的語言描述一篇paper
本文看點:
結合embedding和Segmentation mask提供一種做Lane Instance Segmentation的思路
Lane的Instance Segmentation可以比單純的Segmentation適應更多樣的路面情況,本文在Segmentation Mask的基礎上增加了embedding分支,用以使得每條lane中的畫素embedding結果更加接近,有了lane的segmentation mask和其中畫素的embedding就可以利用聚類的方法將mask 根據閾值切分為幾條單獨的lane。
網路思路如下:

embedding的學習還是通過類似於contrastive loss的方法,將同類拉近,異類拉遠。
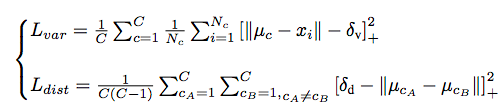
另外,文章中根據影象來學習lane的擬合引數,資料驅動的學習使得系統對於上下坡的場景適應性更強
相關推薦
論文筆記|Towards End-to-End Lane Detection: an Instance Segmentation
用盡量少的語言描述一篇paper 本文看點: 結合embedding和Segmentation mask提供一種做Lane Instance Segmentation的思路 Lane的Instance Segmentation可以比單純的Segmentati
論文筆記(1)DenseBox: Unifying Landmark Localization with End to End Object Detection
本文的貢獻有一下幾點: 1,實現了end-to-end的學習,同時完成了對bounding box和物體類別的預測; 2,在多工學習中融入定位資訊,提高了檢測的準確率。 我們先來看看他和其他幾篇代表性文章之間的不同。 在OverFeat[1]中提出了將分
2017-ICLR End-To-End Optimized Image Compression論文筆記
摘要 我們描述了一種影象壓縮方法,包括非線性分析變換,均勻量化器和非線性合成變換。變換是在卷積線性濾波器和非線性啟用函式的三個連續階段中構建的。與大多數卷積神經網路不同,選擇聯合非線性來實現區域性增益控制的形式,其靈感來自用於模擬生物神經元的那些。使用隨機梯度下降的變體,我們在訓練影象資料庫上聯合優化整個模
論文筆記:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application
1.歷史方法 1)基於字元的DCNN,比如photoOCR.單個字元的檢測與識別。要求單個字元的檢測器效能很強,crop的足夠好。 2)直接對圖片進行分類。9萬個單詞,組合成無數的單詞,無法直接應用 3)RNN,訓練和測試均不需要每個字元的位置。但是需要預處理,從圖片得到特
Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks閱讀筆記
1.摘要 論文提出一種統一的網路結構模型,這種模型可以直接通過一次前向計算就可以同時實現對影象中文字定位和識別的任務。這種網路結構可以直接以end-to-end的方式訓練,訓練的時候只需要輸入影象,影象中文字的bbox,以及文字對應的標籤資訊。這種end-to-end訓練的
【論文筆記07】End-To-End Memory Networks
1 背景 (1)在記憶網路中,主要由4個模組組成:I、G、O、R,前面也提到I和G模組其實並沒有進行多複雜的操作,只是將原始文字進行向量表示後直接儲存在記憶槽中。而主要工作集中在O和R模組,O用來選擇與問題相關的記憶,R用來回答,而這兩部分都需要監督,也就是需要
【論文筆記】An End-to-End Model for QA over KBs with Cross-Attention Combining Global Knowledge
一、概要 該文章發於ACL 2017,在Knowledge base-based question answering (KB-QA)上,作者針對於前人工作中存在沒有充分考慮候選答案的相關資訊來訓練question representation的問題,提出
DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks
step with 圖片 eight enter sub img layer each 1、Introduction DL解決VO問題:End-to-End VO with RCNN 2、Network structure a.CNN based Feature Ext
《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its...》論文閱讀之CRNN
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition paper: CRNN 翻譯:CRNN
CBHG 模組 來自TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS
作者的靈感來源於在文章Fully Character-Level Neural Machine Translation without Explicit Segmentation中的模型。原型如下圖所示: CBHG模組如下圖所示。首次提出在Goggle的一篇文章:TACO
《End-to-End Learning of Motion Representation for Video Understanding》論文閱讀
CVPR 2018 | 騰訊AI Lab、MIT等機構提出TVNet:可端到端學習視訊的運動表徵 動機 儘管端到端的特徵學習已經取得了重要的進展,但是人工設計的光流特徵仍然被廣泛用於各類視訊分析任務中。為了彌補這個不足而提出; 以前的方法:
深度學習論文翻譯解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
論文標題:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition 論文作者: Baoguang Shi, Xiang B
End-to-end recovery of human shape and pose閱讀筆記
本文講了如何從單張RGB圖片重建人體的mesh,這個方法為Human Mesh Recovery(HMR)。 關於從圖片或視訊重建人體的meshes可以分為兩類方法:兩階段法,直接估計法。 兩階段法: 1)用2Dpose檢測,預測2D關節位置 2)通過迴歸分析和model
MFCNET: END-TO-END APPROACH FOR CHANGE DETECTION IN IMAGES
2. RELATEDWORK 影象中的變化檢測是許多應用中影象處理和理解的基本步驟。已經開發了多種方法來檢測場景變化[14],並使用它們來支援其他任務。 背景減法可以被認為是一種變化檢測。 Brutzer等。 [15]比較了使用合成視訊監控資料集的九種現有方法的
深度學習筆記1:end-to-end、anchor box解釋、人體檢測程式碼
非end-to-end方法: 目前目標檢測領域,效果最好,影響力最大的還是RCNN那一套框架,這種方法需要先在影象中提取可能含有目標的候選框(region proposal), 然後將這些候選框輸入到CNN模型,讓CNN判斷候選框中是否真的有目標,以及目標的類別是什麼。在我們看到的結果中,往往是類似與下圖這種
論文閱讀《ActiveStereoNet:End-to-End Self-Supervised Learning for Active Stereo Systems》
最好 ati 計算 最重要的 non-rigid ssi local 模糊 trac 本文出自谷歌與普林斯頓大學研究人員之手並發表於計算機視覺頂會ECCV2018。本文首次提出了應用於主動雙目立體視覺的深度學習解決方案,並引入了一種新的重構誤差,采用自監督的方法來解決缺少g
論文閱讀《End-to-End Learning of Geometry and Context for Deep Stereo Regression》
註意 4.3 匹配算法 argmin hang 立體聲 移動 數據集 聚集 端到端學習幾何和背景的深度立體回歸 摘要 本文提出一種新型的深度學習網絡,用於從一對矯正過的立體圖像回歸得到其對應的視差圖。我們利用問題(對象)的幾何知識,形成一個使
論文翻譯:Generalized end-to-end loss for speaker verification
論文地址:2018_說話人驗證的廣義端到端損失 論文程式碼:https://google.github.io/speaker-id/publications/GE2E/ 地址:https://www.cnblogs.com/LXP-Never/p/11799985.html 作者:凌逆戰 摘要
Overview:end-to-end深度學習網絡在超分辨領域的應用(待續)
向量 不同的 這就是 src dimens sep max pos pca 目錄 1. SRCNN Contribution Inspiration Network O. Pre-processing I. Patch extraction and representat
【USE】《An End-to-End System for Automatic Urinary Particle Recognition with CNN》
Urine Sediment Examination(USE) JMOS-2018 目錄 目錄 1 Background and Motivation 2 Innovation