
複雜網路社群結構發現演算法-基於igraph 標籤傳播演算法
【前言】
繼續我們本系列對複雜網路社群結構的方法探索,之前已經嘗試過spark上標籤傳播演算法、igraph 中隨機遊走演算法、networkx中的clique滲透演算法(見筆者相關文章),但一直侷限於無向、無權重圖的分析。本次,向前邁一步,引入權重。選用了igraph中的標籤傳播演算法。
【方法討論】
相比於spark上的標籤傳播演算法,發現igraph中的介面增加了對權重的支援,同時不用事先指定迭代的次數,這是兩點好的地方。當然,可以處理的資料量級上,igraph單機版本沒法和spark叢集版本相提並論了。但是相比於python版本networkx的效能瓶頸,igraph C library的計算效率領先幾條街。(小小吐槽一下:igraph同時提供有python、R、C三種版本的介面,相比之下,C library的使用要繁瑣很多,如果不是追求效能稍好些,真心推薦使用其它兩種方式)
在對權重的處理上,官方文件如是說:
Weights are taken into account as follows: when the new label of node i is determined, the algorithm iterates over all edges incident on node i and calculate the total weight of edges leading to other nodes with label 0, 1, 2, ..., k-1 (where k is the number of possible labels). The new label of node i will then be the label whose edges (among the ones incident on node i) have the highest total weight.
演算法介面也比較簡潔明確(稍後咱們詳細看如何使用):
int igraph_community_label_propagation(const igraph_t *graph, igraph_vector_t *membership, const igraph_vector_t *weights, const igraph_vector_t *initial, igraph_vector_bool_t *fixed, igraph_real_t *modularity);
【不廢話,上完整版程式碼】
#include <stdio.h>
#include <stdlib.h>
#include </usr/local/igraph-0.7.1/include/igraph.h>
#include <string.h>
int main(int argc,char *argv[])
{
printf("Hello world!\n");
FILE *edgeListFile;
FILE *communityWriteFile;
igraph_t wbNetwork;
long int i;
long int no_of_nodes;
long int no_of_edges;
int rstCode;
igraph_vector_t gtypes, vtypes, etypes;
igraph_strvector_t gnames, vnames, enames;
/* turn on attribute handling */
igraph_i_set_attribute_table(&igraph_cattribute_table);
//初始化物件
igraph_vector_t membership;
igraph_vector_init(&membership,0);
igraph_vector_t weights;
igraph_vector_init(&weights,0);
if(argc < 2){
printf("Usage: %s <inputRelationFile> \n", argv[0]);
exit(1);
}
//邊存放的檔案,空格分隔
edgeListFile = fopen(argv[1],"r");
//從檔案中讀入圖
igraph_read_graph_ncol(&wbNetwork,
edgeListFile,
NULL, /*預定義的節點名稱*/
1, /*讀入節點名稱*/
IGRAPH_ADD_WEIGHTS_YES , /*是否將邊的權重也讀入*/
0 /*有向圖*/
);
fclose(edgeListFile);
//警惕:下面這個函式要慎用,第二個引數及最後一個引數有可能會把權重屬性抹掉
//igraph_simplify(&wbNetwork, 1, 1, 0);
igraph_vector_init(>ypes, 0);
igraph_vector_init(&vtypes, 0);
igraph_vector_init(&etypes, 0);
igraph_strvector_init(&gnames, 0);
igraph_strvector_init(&vnames, 0);
igraph_strvector_init(&enames, 0);
igraph_cattribute_list(&wbNetwork, &gnames, >ypes, &vnames, &vtypes,
&enames, &etypes);
no_of_nodes = igraph_vcount(&wbNetwork);
no_of_edges = igraph_ecount(&wbNetwork);
printf("Graph node numbers: %d \n",no_of_nodes);
printf("Graph edge numbers: %d \n",no_of_edges);
printf("圖屬性個數: %d \n", igraph_strvector_size(&gnames));
printf("節點屬性個數: %d \n", igraph_strvector_size(&vnames));
printf("邊屬性個數: %d \n", igraph_strvector_size(&enames));
if(igraph_cattribute_has_attr(&wbNetwork,IGRAPH_ATTRIBUTE_EDGE,"weight")){
//將權重提取到向量中
EANV(&wbNetwork,"weight",&weights);
//printf("邊權重屬性值的個數為:%d \n", igraph_vector_size(&weights));
printf("Edge weight: \n");
//這裡列印2份是為了驗證從屬性集合中取值與上面所存權重向量的值是否一致
for(i=0; i<10; i++) {
printf("Edge weight: %g %g \n",igraph_cattribute_EAN(&wbNetwork,"weight",i),VECTOR(weights)[i]);
}
}else{
printf("The Graph does not have attribute of weight \n");
}
rstCode = igraph_community_label_propagation(&wbNetwork,
&membership, /*重要:儲存最終每個節點被劃分到的社群編號*/
&weights,
NULL, /*對節點分配的初始化標籤*/
NULL, /*是否將一部分節點的標籤固定*/
NULL /*最終社區劃分結果的模組度*/
);
if(rstCode != 0){
printf("igraph_community_label_propagation 執行失敗");
return -2;
}else{
printf("Success! \n");
printf("劃分的社群總數為:%g\n", igraph_vector_max(&membership));
for(i=0;i<10;i++){
printf("節點: %d -> 社群:%g \n",i,VECTOR(membership)[i]);
}
}
//將節點劃分的社群結構儲存到檔案中
communityWriteFile = fopen("/data/tmp/igraph_lp_result.txt","w");
for(i=0;i<no_of_nodes;i++){
fprintf(communityWriteFile,"%s\t%g\n",igraph_cattribute_VAS(&wbNetwork,"name",i),VECTOR(membership)[i]);
}
fclose(communityWriteFile);
igraph_vector_destroy(&membership);
igraph_vector_destroy(>ypes);
igraph_vector_destroy(&vtypes);
igraph_vector_destroy(&etypes);
igraph_strvector_destroy(&gnames);
igraph_strvector_destroy(&vnames);
igraph_strvector_destroy(&enames);
igraph_vector_destroy(&weights);
igraph_destroy(&wbNetwork);
return 0;
}
在我們的測試資料集上,上述程式碼執行結果示意如下,9萬個節點,52萬條邊,瞬間完成。比之前嘗試networkx時9萬節點,30萬條邊就已經抗不住了,這裡的計算效能令人十分滿意。
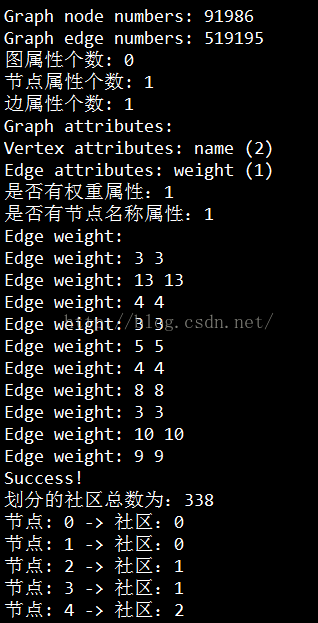
【要點討論】
- 從檔案中讀入加權圖
在上面程式碼中,從一個儲存邊資訊的檔案中讀入圖結構,使用的方法是:
igraph_read_graph_ncol(&wbNetwork,
edgeListFile,
NULL, /*預定義的節點名稱*/
1, /*讀入節點名稱*/
IGRAPH_ADD_WEIGHTS_YES , /*是否將邊的權重也讀入*/
0 /*有向圖*/
);注意其中 IGRAPH_ADD_WEIGHTS_YES 這個資訊就表示將邊的權重讀入圖的屬性中,而且千萬要注意接下來不要寫 igraph_simplify(&wbNetwork, 1, 1, 0); 這樣的方法,會把權重資料從邊的屬性中刪除掉,我猜想是最後那個引數把權重抹掉了,暫時也沒時間細究,但這一點真心花了俺好長時間才意識到,因為之前匯入圖時,喜歡使用這個方法再去除多重邊及環啥的,現在先對邊資料檔案預處理好,可以實現簡化。
同樣一個功能,在R中只需要更加簡單的一句話:
g <- read.graph("your_edge_file.ncol", format="ncol")- 處理圖的屬性值
如果你認為像上面那樣匯入圖後,就可以開心地處理各種屬性值,你就錯了! igraph C 版本中,圖的屬性處理是最最讓人抓狂的。比如像上面那樣匯入一個圖後,在R中,你就可以直接使用各種屬性了,比如

但是,在c library中,你要至少操作以下幾步:一、建立儲存屬性的各種變數,如下所示:
igraph_vector_t gtypes, vtypes, etypes;
igraph_strvector_t gnames, vnames, enames;
/* turn on attribute handling */
igraph_i_set_attribute_table(&igraph_cattribute_table);二、匯入圖後,要初始化這些屬性變數,如下所示:
igraph_vector_t gtypes, vtypes, etypes;
igraph_strvector_t gnames, vnames, enames;
/* turn on attribute handling */
igraph_i_set_attribute_table(&igraph_cattribute_table);三、屬性又分圖屬性、節點屬性、邊屬性,各有各的方法,比如
檢視各有哪些屬性時,可如此這般:
printf("Graph attributes: ");
for (i=0; i<igraph_strvector_size(&gnames); i++) {
printf("%s (%i) ", STR(gnames, i), (int)VECTOR(gtypes)[i]);
}
printf("\n");
printf("Vertex attributes: ");
for (i=0; i<igraph_strvector_size(&vnames); i++) {
printf("%s (%i) ", STR(vnames, i), (int)VECTOR(vtypes)[i]);
}
printf("\n");
printf("Edge attributes: ");
for (i=0; i<igraph_strvector_size(&enames); i++) {
printf("%s (%i) ", STR(enames, i), (int)VECTOR(etypes)[i]);
}
printf("\n");本文完整程式碼中檢視是否存在邊的權重屬性時,可如此這般:
igraph_cattribute_has_attr(&wbNetwork,IGRAPH_ATTRIBUTE_EDGE,"weight")【結語】
事實上,不同方法的使用都有相通的地方,上手未必困難,但箇中細節又往往需要花費時間去研究。這也是為何我們堅持把最近嘗試過的一些方法完完整整記錄下相關經驗,以便於同道中人相互交流,減少一些細節點對時間的消耗。如本文有此功效,則幸甚。
相關推薦
複雜網路社群結構發現演算法-基於igraph 標籤傳播演算法
【前言】 繼續我們本系列對複雜網路社群結構的方法探索,之前已經嘗試過spark上標籤傳播演算法、igraph 中隨機遊走演算法、networkx中的clique滲透演算法(見筆者相關文章),但一直侷限於無向、無權重圖的分析。本次,向前邁一步,引入權重。選用了
複雜網路社群結構發現演算法-基於python networkx clique滲透演算法
前言 最近因為業務資料分析的需要,看社群發現相關的東東稍多些,剛剛寫過一篇基於igraph C library的方法(http://blog.csdn.net/a_step_further/article/details/51176973),然後想用kcliqu
深度神經網路(DNN)模型與前向傳播演算法
深度神經網路(Deep Neural Networks, 以下簡稱DNN)是深度學習的基礎,而要理解DNN,首先我們要理解DNN模型,下面我們就對DNN的模型與前向傳播演算法做一個總結。 1. 從感知機到神經網路 在感知機原理小結中,我們介紹過感知機的模型,它是一個有若干輸入和一個輸出的模型,
半監督學習演算法——標籤傳播演算法(LPA)與其擴充套件
標籤傳播演算法LPA與其擴充套件 1. 什麼是標籤傳播演算法? 標籤傳播演算法(Label Propagation Algorithm,LPA,2007)是基於圖的一種標籤演算法,也是社群發現(Community Detection)領域的一種經典方法。社群發現是為
標籤傳播演算法(LPA)Python實現
標籤傳播演算法(LPA)的做法比較簡單: 第一步:為所有節點指定一個唯一的標籤; 第二步:逐輪重新整理所有節點的標籤,直到達到收斂要求為止。對於每一輪重新整理,節點標籤重新整理的規則如下:
聚類——標籤傳播演算法以及Python實現
標籤傳播演算法(label propagation)是典型的半監督聚類演算法。半監督是指訓練資料集中小部分樣本點已知標籤,大部分樣本點未知標籤。 核心思想 相似性較大的樣本點間應該具有相同的標籤,將已知標籤通過相似性矩陣傳播到未知的標籤。 演算法簡
BP(反向傳播)演算法和CNN反向傳播演算法推導(轉載)
轉載來源: http://blog.csdn.net/walegahaha/article/details/51867904 http://blog.csdn.net/walegahaha/article/details/51945421 關於CNN推導可以參考文獻:
基於最短路徑演算法的社群發現演算法-Gewman and Girvan演算法)
基於最短路徑演算法的社群發現演算法-Gewman and Girvan演算法) 重要概念 邊介數(betweenness):網路中任意兩個節點通過此邊的最短路徑的數目。 GN演算法的思想:在一個網路之中,通過社群內部的邊的最短路徑相對較少,而通過社群之間的邊的最短路徑的數目則相對
開源複雜網路分析軟體中社團發現演算法總結
複雜網路研究中的一個重要部分就是社團發現(Community Detection)演算法的研究,密歇根大學物理學系教授Mark Newman就主要在社團發現方面做出了很多貢獻。今天簡單總結一下幾個開源複雜網路分析軟體中的社團發現演算法: 首先是NetworkX,這個軟體非常好用,功能強大,文件清晰。我
Python利用igraph繪製複雜網路聚類(社群檢測)結果圖
前言:研究生期間主要做複雜網路聚類,也稱為社群檢測。臨畢業前,老師讓之前發表的論文裡的演算法程式碼C化,並寫出介面進行視覺化。由於之前雖然做過視覺化,但基本上都是將聚類結果匯入到pajek或者gephi這類專門的軟體裡進行繪製的。想要將社群檢測結果實時的進行
複雜網路|基於複雜網路的新型分類器
目錄 0、簡介 1、演算法原理 1.1構造複雜網路 1.2計算spatio-structural differential efficiency 1.3計算PageRank 1.4建立測試節點的臨時邊 1.5計算測試節點對每一類的重要性 1.6預
社群發現演算法之標籤傳播(LPA)
標籤傳播演算法(LPA)的做法比較簡單: 第一步: 為所有節點指定一個唯一的標籤; 第二步: 逐輪重新整理所有節點的標籤,直到達到收斂要求為止。對於每一輪重新整理,節點標籤重新整理的規則如下: 對於某一個節點,考察其所有鄰居節點的標籤,並進行統計,將出現個數最多
玩轉Android Camera開發 五 基於Google自帶演算法實時檢測人臉並繪製人臉框 網路首發 附完整demo
本文主要介紹使用Google自帶的FaceDetectionListener進行人臉檢測,並將檢測到的人臉用矩形框繪製出來。本文程式碼基於PlayCameraV1.0.0,在Camera的open和preview流程上進行了改動。原先是放在單獨執行緒裡,這次我又把它放到
關於基於比較的排序演算法,時間複雜度“最壞”下界o(nlogn)與“最優”下界o(n)說明
前言 之前在查詢基於比較排序演算法的時間複雜度時發現,好多博主對“最壞”下界與“最優”下界沒有分清,而是預設的把時間複雜度o(nlogn)當成了“最優”下界。這樣很是誤導大家,影響很不好。所以特此寫一篇說明文章,能讓大家理解得更透徹。 下界
堆排序演算法基於二叉樹資料結構的python實現
堆排序的原理略,此處只是作為記錄,提供整個程式碼的實現,其中每個細節會給出註釋和函式的設計思路(程式碼末尾)。 注:堆排序演算法的實現,以陣列結構來實現要簡潔高效!此處只是作為練手使用,由於堆排序的陣列實現已經有很多, 此處略。 自定義模組: 這個模組我們只用到其節點物件的建立、根據陣列生成
神經網路演算法(基於Tensorflow、基於Python實現BP)
1. 演算法思想 神經網路可分為兩個過程,前向傳播和反向傳播過程。前向傳播是對線性結果的非線性轉化,獲得對映關係,此非線性對映關係可依據層數的增加而累加;反向傳播是對前向傳播結果的誤差進行修正,依據各種型別的梯度下降演算法更新梯度,使得前向傳播的結果能更接近真
網路拓撲發現演算法的分析
摘 要: 介紹了幾種常見的網路拓撲發現工具,從負載、速度、準確性及適用範圍幾個方面對各工具的執行效果進行了對比;分類歸納了常用的網路拓撲發現的方法;分析了利用這些方法實現的七種拓撲發現演算法,並針對每種演算法詳細列出了其優缺點。給出了對網路拓撲發現演算法進行評價的標準及其量化的表示形式。 關鍵詞: 拓撲發現
基於tensorflow的簡單BP神經網路的結構搭建
tensorflow的構建封裝的更加完善,可以任意加入中間層,只要注意好維度即可,不過numpy版的神經網路程式碼經過適當地改動也可以做到這一點,這裡最重要的思想就是層的模型的分離。下面介紹關於tensorflow的構建神經網路的方法,特此記錄。 import tensorflow as tf
關於基於複雜網路的資料探勘的學習筆記
最近一直投身 複雜網路的各種問題 簡單記錄一下 我這一路關注的問題 開始學到用聚集係數來判別垃圾簡訊的傳送號碼 我就想臨摹一個 用聚集係數在微信朋友關係中 判別微商 結果是失敗的 一是取不到資料 二是 微商很多就是買給熟人 他的朋友不一定不是朋友 他的聚集係數
從時間序列到複雜網路:可見圖演算法
這篇文章實現的演算法來源於PNAS雜誌: 程式碼參考: # coding: utf-8 import networkx as nx import matplotlib.pyplot as plt from itertools import combinations d