
如何在Kubernetes上玩轉TensorFlow ?
女主宣言
該文章出自於ADDOPS團隊,是關於如何在K8S上玩轉tensorflow的主題,該文章深入淺出的給我們介紹了當前tensorflow的現狀和架構特點等,然後介紹了讓tensorflow如何基於k8s快速落地,讓大家都能簡單的上手tensorflow,整體文章脈絡清晰,內容適度,所以希望能給大家帶來啟發。
PS:豐富的一線技術、多元化的表現形式,盡在“HULK一線技術雜談”,點關注哦!
前言
Tensorflow作為深度學習領域逐漸成熟的專案,以其支援多種開發語言,支援多種異構平臺,提供強大的演算法模型,被越來越多的開發者使用。但在使用的過程中,尤其是GPU叢集的時候,我們或多或少將面臨以下問題:
- 資源隔離。Tensorflow(以下簡稱tf)中並沒有租戶的概念,何如在叢集中建立租戶的概念,做到資源的有效隔離成為比較重要的問題;
- 缺乏GPU排程。tf通過指定GPU的編號來實現GPU的排程,這樣容易造成叢集的GPU負載不均衡;
- 程序遺留問題。tf的分散式模式ps伺服器會出現tf程序遺留問題;
- 訓練的資料分發以及訓練模型儲存,都需要人工介入;
- 訓練日誌儲存、檢視不方便;
因此,我們需要一個叢集排程和管理系統,可以解決GPU排程、資源隔離、統一的作業管理和跟蹤等問題。
目前,社群中有多種開源專案可以解決類似的問題,比如yarn,kubernetes。yarn是hadoop生態中的資源管理系統,而kubernetes(以下簡稱k8s)作為Google開源的容器叢集管理系統,在tf1.6版本加入GPU管理後,已經成為很好的tf任務的統一排程和管理系統。
下文是我們公司在tensorflow on kubernetes方面的實踐經驗。
設計目標
我們將tensorflow引入k8s,可以利用其本身的機制解決資源隔離,GPU排程以及程序遺留的問題。除此之外,我們還需要面臨下面問題的挑戰:
- 支援單機和分散式的tensorflow任務;
- 分散式的tf程式不再需要手動配置clusterspec資訊,只需要指定worker和ps的數目,能自動生成clusterspec資訊;
- 訓練資料、訓練模型以及日誌不會因為容器銷燬而丟失,可以統一儲存;
為了解決上面的問題,我們開發了tensorflow on kubernetes系統。
架構
tensorflow on kubernetes包含三個主要的部分,分別是client、task和autospec模組。client模組負責接收使用者建立任務的請求,並將任務傳送給task模組。task模組根據任務的型別(單機模式和分散式模式)來確定接下來的流程:
如果type選擇的是single(單機模式),對應的是tf中的單機任務,則按照按照使用者提交的配額來啟動container並完成最終的任務;
如果type選擇的是distribute(分散式模式),對應的是tf的分散式任務,則按照分散式模式來執行任務。需要注意的是,在分散式模式中會涉及到生成clusterspec資訊,autospec模組負責自動生成clusterspec資訊,減少人工干預。
下面是tensorflow on kubernetes的架構圖:
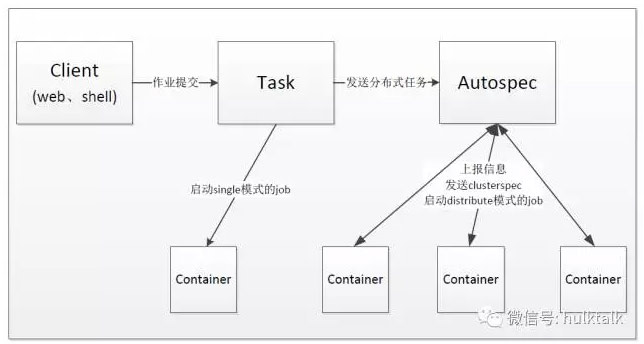
接下來將對三個模組進行重點介紹。
client模組
tshell
在容器中執行任務的時候,我們可以通過三種方式獲取執行任務的程式碼和訓練需要的資料:
- 將程式碼和資料做成新的映象;
- 將程式碼和資料通過卷的形式掛載到容器中;
- 從儲存系統中獲取程式碼和資料;
前兩種方式不太適合使用者經常修改程式碼的場景,最後一種場景可以解決修改程式碼的問題,但是它也有下拉程式碼和資料需要時間的缺點。綜合考慮後,我們採取第三種方式。
我們做了一個tshell客戶端,方便使用者將程式碼和程式進行打包和上傳。比如給自己的任務起名字叫cifar10-multigpu,將程式碼打包放到code下面,將訓練資料放到data下面。
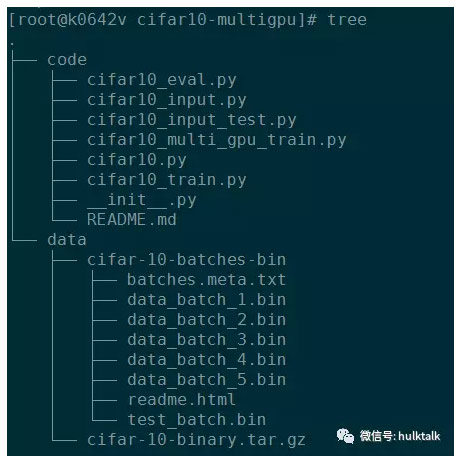
最後打包成cifar10-multigpu.tar.gz並上傳到s3後,就可以提交任務。
提交任務
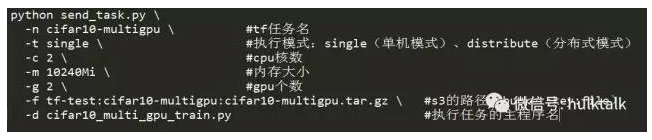
在提交任務的時候,需要指定提前預估一下執行任務需要的配額:cpu核數、記憶體大小以及gpu個數(預設不提供),當然也可以按照我們提供的初始配額來排程任務。
比如,按照下面格式來將配額資訊、s3地址資訊以及執行模式填好後,執行send_task.py我們就可以提交一次任務。
 task模組
task模組
單機模式
對於單機模式,task模組的任務比較簡單,直接呼叫python的client介面啟動container。container裡面主要做了兩件事情,initcontainer負責從s3中下載事先上傳好的檔案,container負責啟動tf任務,最後將日誌和模型檔案上傳到s3裡,完成一次tf單機任務。
分散式模式
對於分散式模式,情況要稍微複雜些。下面先簡單介紹一下tensforlow分散式框架。tensorflow的分散式並行基於gRPC框架,client負責建立Session,將計算圖的任務下發到TF cluster上。
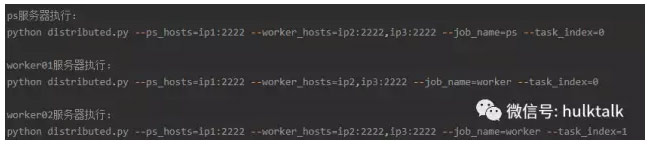
TF cluster通過tf.train.ClusterSpec函式建立一個cluster,每個cluster包含若干個job。 job由好多個task組成,task分為兩種,一種是PS(Parameter server),即引數伺服器,用來儲存共享的引數,還有一種是worker,負責計算任務。

我們在執行分散式任務的時候,需要指定clusterspec資訊,如下面的任務,執行該任務需要一個ps和兩個worker,我們先需要手動配置ps和worker,才能開始任務。這樣必然會帶來麻煩。如何解決clusterspec,成為了一個必須要解決的問題。
所以在提交分散式任務的時候,task需要autospec模組的幫助,收集container的ip後,才能真正啟動任務。所以分散式模式要做兩件事情:
- 按照yaml檔案啟動container;
- 通知am模組收集此次任務container的資訊後生成clusterspec;
Autospec模組
tf分散式模式的node按照角色分為ps(負責收集引數資訊)和worker,ps負責收集引數資訊,worker執行任務,並定期將引數傳送給worker。
要執行分散式任務,涉及到生成clusterspec資訊,模型的情況下,clusterspec資訊是通過手動配置,這種方式比較麻煩,而且不能實現自動化,我們引入autospec模型很好的解決此類問題。
Autospec模組只有一個用途,就是在執行分散式任務時,從container中收集ip和port資訊後,生成clusterspec,傳送給相應的container。下面是autospec模組的工作流程圖:

Container設計
tf任務比較符合k8s中kind為job的任務,每次執行完成以後這個容器會被銷燬。我們利用了此特徵,將container都設定為job型別。
k8s中設計了一種hook:poststart負責在容器啟動之前做一些初始化的工作,而prestop負責在容器銷燬之前做一些備份之類的工作。
我們利用了此特點,在poststart做一些資料獲取的工作,而在prestop階段負責將訓練產生的模型和日誌進行儲存。我們接下來分單機和分散式兩種模式來說明Container的設計思想。
總結
至此,我們已經介紹了tensorflow on kubernetes的主要流程。還有許多需要完善的地方,比如:web端提交任務以及檢視執行狀況和作業的日誌;支援GPU的親和性等等,總之,這只是我們前期的探索,後面還有許多東西需要完善。
相關推薦
如何在Kubernetes上玩轉TensorFlow ?_Kubernetes中文社群
女主宣言 該文章出自於ADDOPS團隊,是關於如何在K8S上玩轉tensorflow的主題,該文章深入淺出的給我們介紹了當前tensorflow的現狀和架構特點等,然後介紹了讓tensorflow如何基於k8s快速落地,讓大家都能簡單的上手tensorflow,整體文章脈絡清晰,內容適度,所以
如何在Kubernetes上玩轉TensorFlow ?
女主宣言 該文章出自於ADDOPS團隊,是關於如何在K8S上玩轉tensorflow的主題,該文章深入淺出的給我們介紹了當前tensorflow的現狀和架構特點等,然後介紹了讓tensorflow如何基於k8s快速落地,讓大家都能簡單的上手tensorflow,整體文
教程 | 沒有博士學位,照樣玩轉TensorFlow深度學習
flow doc 深度 tensor sdn shtml art 線性 算法系列 香港科技大學TensorFlow三天速成課件 https://blog.csdn.net/zhongxon/article/details/54709347 香港科技大學TensorFlow三
在Ubuntu 16.04.3 LTS上玩轉QUIC開源專案proto-quic
說明proto-quic專案是民間從chromium中抽取出的QUIC實現相關的程式碼。採用這個專案的程式碼,比從chromium原始碼編譯,要更快速和簡單。因為畢竟GFW限制,不是所有的人都可以翻牆去下載近10G的chromium專案原始碼。下面的實操過程完全遵照githu
在CENTOS7上玩轉Ethereum區塊鏈(3):Ethereum挖礦轉賬初體驗
三、Ethereum挖礦轉賬初體驗 # 準備好兩個SSH連線到虛機上 # 第一個SSH先建立一個日誌檔案geth_log_file,並開始持續觀察 rm geth_log_file -f echo >> geth_log_file tail -f geth_l
為想學SQLite或練習SQL語言的朋友搭建簡單的命令列環境------在Windows, Linux, Android(用adb連線安卓手機)上玩轉SQLite資料庫的sqlite3命令列
有言在先: 如果你是隻想玩玩SQL語句的lazy bone, 請直接看本文最後的"LAST部分" 之所以寫這篇文章, 是因為覺得SQLite實在是太棒了, 想學習資料庫的朋友們, 千萬不要錯過這麼優秀的資料庫。 對於初學者來說, SQLite
TensorFlow 1.0.0rc1上玩量化神經網路 ——轉自 慢慢學TensorFlow 微信公眾號
這裡的量化不是指“量化交易(Quantitative trade)”,而是 Quantization ,即離散化,注意是否走錯片場。 前言 開發神經網路時最大的挑戰是讓它真正起作用,訓練時一般希望速度越快越好,準確率越高越好。使用浮點演算法是保持結果精確最簡單的方式,GPU 擁有加速浮點演算法的
玩轉圖片上傳————原生js XMLHttpRequest 結合FormData對象實現的圖片上傳
con tel ech 圖片 xmlhttp scrip state clas document var form=document.getElementById("formId"); var formData=new FormData(form);
學習 Kubernetes 的 Why 和 How - 每天5分鐘玩轉 Docker 容器技術(11
kubernetes docker 容器 教程 這是一個系統學習 Kubernetes 的教程,有下面兩個特點:系統講解當前最流行的容器編排引擎 Kubernetes包括了安裝部署、應用管理、網絡、存儲、監控、日誌管理等多各個方面。重實踐並兼顧理論通過大量實驗和操作帶領大家學習 Kuberne
部署 k8s Cluster(上)- 每天5分鐘玩轉 Docker 容器技術(118)
tis pre 自動 img 為我 ida advertise kube-dns mil 我們將部署三個節點的 Kubernetes Cluster。k8s-master 是 Master,k8s-node1 和 k8s-node2 是 Node。所有節點的操作系統均為 U
CX10基於Python玩轉人工智能最火框架 TensorFlow應用實踐
AI 把手 能開 技術 如何 package 不知道 困難 學習 CX10基於Python玩轉人工智能最火框架 TensorFlow應用實踐 新年伊始,學習要趁早,點滴記錄,學習就是進步! 不要到處找了,抓緊提升自己。 對於學習有困難不知道如何提升自己可以加扣:122546
大神教你輕松玩轉Docker和Kubernetes中如何運行MongoDB微服務
cdn 成員 實現 細節 步驟 class 就會 接受 blog 本文介紹了利用Docker和Kubernetes搭建一套具有冗余備份集合的MongoDB服務,從容器對CI和CD引發的改變入手,討論了容器技術對MongoDB帶來的挑戰和機會,然後實戰如何部署一套穩定的Mo
Kubernetes Dashboard - 每天5分鐘玩轉 Docker 容器技術(173)
title 一個 ash orm 完成 creat nbsp edi 分鐘 前面章節 Kubernetes 所有的操作我們都是通過命令行工具 kubectl 完成的。為了提供更豐富的用戶體驗,Kubernetes 還開發了一個基於 Web 的 Dashboard,用戶可以用
六天帶你玩轉mysql資料庫--第三天筆記(上)
回顧: 欄位型別(列型別):數值型,時間日期和字串型別。 數值型:整數和小數型(浮點型和定點型) 時間日期型:datetime,date,time,timestamp,year。 字串型別:定長,變長,文字字串(text和blob),列舉(單選)和集合(多選)。 mysql的 記錄長度:
六天帶你玩轉mysql資料庫--第五天筆記(上)
回顧: 連線查詢:多張表連線到一起,不管記錄數如何,欄位數一定會增加。 分類:內連線,外連線,自然連線和交叉連線。 交叉連線:cross join(笛卡爾積) 內連線:inner join,左右兩張表中有連線條件匹配(不忽略的匹配) 外連線:outer [left/righ
21個專案玩轉深度學習:基於TensorFlow的實踐詳解03—打造自己的影象識別模型
書籍原始碼:https://github.com/hzy46/Deep-Learning-21-Examples CNN的發展已經很多了,ImageNet引發的一系列方法,LeNet,GoogLeNet,VGGNet,ResNet每個方法都有很多版本的衍生,tensorflow中帶有封裝好各方法和網路的函式
分享《21個項目玩轉深度學習:基於TensorFlow的實踐詳解》PDF+源代碼
更多 技術分享 書籍 詳解 http alt ges text process 下載:https://pan.baidu.com/s/19GwZ9X2E20L3BykhoxhjTg 更多資料:http://blog.51cto.com/3215120 《21個項目玩轉深度學
《21個專案玩轉深度學習:基於TensorFlow的實踐詳解》PDF+原始碼下載
1.本書以TensorFlow為工具,從基礎的MNIST手寫體識別開始,介紹了基礎的卷積神經網路、迴圈神經網路,還包括正處於前沿的對抗生成網路、深度強化學習等課題,程式碼基於TensorFlow 1.4.0 及以上版本。 2.書中所有內容由21個可以動手實驗的專案組織起來,並在其中穿插Te
《21個專案玩轉深度學習:基於TensorFlow的實踐詳解》
下載:https://pan.baidu.com/s/1NYYpsxbWBvMn9U7jvj6XSw更多資料:http://blog.51cto.com/3215120《21個專案玩轉深度學習:基於TensorFlow的實踐詳解》PDF+原始碼PDF,378頁,帶書籤目錄,文字可以複製。配套原始碼。深度學習經
《21個項目玩轉深度學習:基於TensorFlow的實踐詳解》
源代碼 .com 實踐詳解 項目 term vpd 更多 mage mar 下載:https://pan.baidu.com/s/1NYYpsxbWBvMn9U7jvj6XSw更多資料:http://blog.51cto.com/3215120《21個項目玩轉深度學習:基於