
神經網路聚類方法:SOM演算法原理
一個神經網路接收外界輸入模式時,將會分為不同的對應區域,各區域對輸入模式有不同的響應特徵,而這個過程是自動完成的。其特點與人腦的自組織特性類似。SOM的目標是用低維(通常是二維或三維)目標空間的點來表示高維空間中的所有點,儘可能地保持點間的距離和鄰近關係(拓撲關係)。
自組織神經網路:是無導師學習網路。它通過自動尋找樣本中的內在規律和本質屬性,自組織,自適應地改變網路引數與結構。
結構:
SOM為層次型結構。典型結構是:輸入層加競爭層
輸入層:接收外界資訊,將輸入模式向競爭層傳遞,起“觀察”作用
競爭層:負責對輸入模式進行“分析比較”,尋找規律並歸類。
競爭學習規則就是從神經元細胞的側抑制現象獲得的,它的學習步驟如下:
(1)向量歸一化
對自組織網路中的當前輸入模式向量X、競爭層中各神經元對應的內星權向量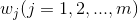
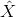
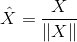
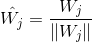
(2)尋找獲勝神經元
將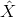
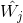
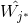
(3)網路輸出與權調整
按WTA學習法則,獲勝神經元輸出為“1”,其餘為0,即

只有獲勝神經元才有權調整其權向量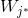

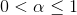

(4)重新歸一化處理
歸一化後的權向量經過調整後,得到的新向量不再是單位向量,因此要對學習調整後的向量重新歸一化,迴圈運算,直到學習率
SOM演算法原理:
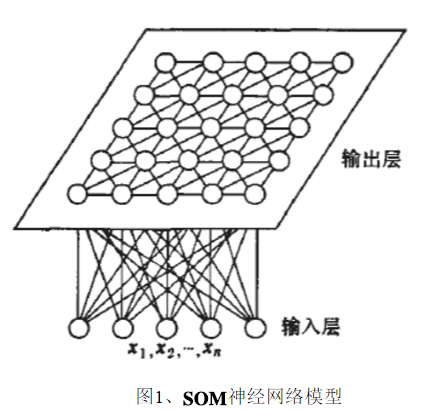
SOM人工神經網路是一個可以在一維或二維的處理單元陣列上,形成輸入訊號的特徵拓撲分佈,結構如圖一所示。網路模擬了人類大腦神經網路自組織特徵對映的功能。該網路由輸入層和輸出層組成,其中輸入層的神經元個數的選取按輸入網路的向量個數而定,輸入神經元為一維矩陣,接收網路的輸入訊號,輸出層則是由神經元按一定的方式排列成一個二維節點矩陣。輸入層的神經元與輸出層的神經元通過權值相互聯結在一起。當網路接收到外部的輸入訊號以後,輸出層的某個神經元便會興奮起來.
SOM神經網路模型


優點:它將相鄰關係強加在簇質心上,所以,互為鄰居的簇之間比非鄰居的簇之間更相關。這種聯絡有利於聚類結果的解釋和視覺化。
缺點:(1)使用者必選選擇引數、鄰域函式、網格型別和質心個數
(2)一個SOM簇通常並不對應單個自然簇、可能有自然簇的合併和分裂。
(3)缺乏具體的目標函式
(4)SOM不保證收斂,儘管實際中它通常收斂
SOM的應用:
(1)汽輪發電機多故障診斷的SOM神經網路方法
(2)基於SOM神經網路的柴油機故障診斷
相關推薦
神經網路聚類方法:SOM演算法原理
一個神經網路接收外界輸入模式時,將會分為不同的對應區域,各區域對輸入模式有不同的響應特徵,而這個過程是自動完成的。其特點與人腦的自組織特性類似。SOM的目標是用低維(通常是二維或三維)目標空間的點來表
聚類方法:DBSCAN演算法研究(1)--DBSCAN原理、流程、引數設定、優缺點以及演算法
DBSCAN聚類演算法三部分: 1、 DBSCAN原理、流程、引數設定、優缺點以及演算法; 2、 matlab程式碼實現; 3、 C++程式碼實現及與matlab例項結果比較。 DBSCAN(Density-based
聚類方法:DBSCAN演算法研究(2)--matlab程式碼實現
DBSCAN聚類演算法三部分: 1、 DBSCAN原理、流程、引數設定、優缺點以及演算法; 2、 matlab程式碼實現; 3、 C++程式碼實現及與matlab例項結果比較。 摘要:介紹DBSCAN原理、流程、引數設
機器學習實戰——python實現SOM神經網路聚類演算法
演算法基礎 SOM網路結構 輸入層:假設一個輸入樣本為X=[x1,x2,x3,…,xn],是一個n維向量,則輸入層神經元個數為n個。 輸出層(競爭層):通常輸出層的神經元以矩陣方式排列在二維空間中,每個神經元都有一個權值向量。 假設輸出層有m個神經元,則有m
聚類程式(彙總)k-means、層次聚類、神經網路聚類、高斯混合聚類等
利用不同方法對資料進行聚類,參考至:周志華 機器學習 %% 利用不同方法對債券樣本進行聚類 %說明 %分別採用不同的方法,對資料進行聚類 %kmens可以選擇的pdist/clustering距離 % 'sqeuclidean' 'cityblock
深度學習之神經網路(CNN/RNN/GAN)演算法原理+實戰目前最新
第1章 課程介紹 深度學習的導學課程,主要介紹了深度學習的應用範疇、人才需求情況和主要演算法。對課程章節、課程安排、適用人群、前提條件以及學習完成後達到的程度進行了介紹,讓同學們對本課程有基本的認識。 1-1 課程導學 第2章 神經網路入門 本次實戰課程的入門課程。對機器學習和深度學習做了引入
深度學習之神經網路(CNN/RNN/GAN) (演算法原理+實戰) 完整版下載
第1章 課程介紹 深度學習的導學課程,主要介紹了深度學習的應用範疇、人才需求情況和主要演算法。對課程章節、課程安排、適用人群、前提條件以及學習完成後達到的程度進行了介紹,讓同學們對本課程有基本的認識。 第2章 神經網路入門 本次實戰課程的入門課程。對機器學習和深
深度學習之神經網路(CNN/RNN/GAN) (演算法原理+實戰)完整版
第1章 課程介紹 深度學習的導學課程,主要介紹了深度學習的應用範疇、人才需求情況和主要演算法。對課程章節、課程安排、適用人群、前提條件以及學習完成後達到的程度進行了介紹,讓同學們對本課程有基本的認識。 1-1 課程導學 第2章 神經網路入門 本次實戰課程的入門課程。對機器學
神經網路反向傳播(BP)演算法原理
一.BP演算法簡介 BP演算法的學習過程由正(前)向傳播過程和反向傳播過程組成。 1.正向傳播 將訓練集資料輸入到ANN的輸入層,經過隱藏層,最後達到輸出層並輸出結果; 2.反向傳播 由於ANN的輸出結果與實際結果有誤差,則計算估計值與
演算法設計:基於密度的聚類方法
1、前言 我們生活在資料大爆炸時代,每時每刻都在產生海量的資料如視訊,文字,影象和部落格等。由於資料的型別和大小已經超出了人們傳統手工處理的能力範圍,聚類,作為一種最常見的無監督學習技術,可以幫助人們給資料自動打標籤,已經獲得了廣泛應用。聚類的目的就是把不同的資料點按照它們的相似與相異度分割成不
基於神經網路的目標檢測論文之神經網路基礎:神經網路的優化方法
注:本文源自本人的碩士畢業論文,未經許可,嚴禁轉載! 原文請參考知網:知網地址 本章節有部分公式無法顯示,詳見原版論文 2.4 神經網路的優化方法 2.4.1 過擬合與規範化 物理學家費米曾說過,如果有四個引數,我可以模擬一頭大象,而如果有五個引數,我還能讓他卷
sklearn實戰:對文件進行聚類分析(KMeans演算法)
%matplotlib inline import matplotlib.pyplot as plt import numpy as np from time import time from sklearn.datasets import load_fi
六、改進神經網路的學習方法(2):Softmax輸出層
本部落格主要內容為圖書《神經網路與深度學習》和National Taiwan University (NTU)林軒田老師的《Machine Learning》的學習筆記,因此在全文中對它們多次引用。初出茅廬,學藝不精,有不足之處還望大家不吝賜教。
西瓜書9.10:實現自動確定聚類數目的k_means演算法
問題: 試設計一個能自動確定聚類數的改進k均值演算法,程式設計實現並在西瓜資料集4.0上執行。 資料集: 西瓜資料集4.0 資料集描述: 該資料集共有30個樣本,每個樣本有密度和含糖度兩個特徵。 思路: 如何確定k的取值: 這裡希望每一類別內部
聚類演算法之DBSCAN(具有噪聲的基於密度的聚類方法)
# !/usr/bin/python # -*- coding:utf-8 -*- import numpy as np import matplotlib.pyplot as plt import sklearn.datasets as ds import matpl
聚類演算法(四)、基於高斯混合分佈 GMM 的聚類方法(補充閱讀)
基於高斯混合分佈的聚類,我看了很多資料,,寫的千篇一律,一律到讓人看不明白。直到認真看了幾遍周志華寫的,每看一遍,都對 GMM 聚類有一個進一步的認識。所以,如果你想了解這一塊,別看亂七八糟的部落格了,直接去看周志華的《機器學習》 P206頁。 下面是我額外看的
聚類方法之k-mean演算法
演算法思想: K-mean演算法又稱K均值演算法,屬於原型聚類中的一種基於距離度量的聚類演算法。其思想是: 1.隨機選取資料集中的k個初始點作為質心,遍歷整個資料集,對於每個樣本,將其歸類到距離其最近的質心所對應的簇。 2.接著計算每個簇的均值,作為當前簇
五、改進神經網路的學習方法(1):交叉熵代價函式
本部落格主要內容為圖書《神經網路與深度學習》和National Taiwan University (NTU)林軒田老師的《Machine Learning》的學習筆記,因此在全文中對它們多次引用。初出茅廬,學藝不精,有不足之處還望大家不吝賜教。
卷積神經網路(三):權值初始化方法之Xavier與MSRA
基礎知識 首先介紹一下Xavier等初始化方法比直接用高斯分佈進行初始化W的優勢所在: 一般的神經網路在前向傳播時神經元輸出值的方差會不斷增大,而使用Xavier等方法理論上可以保證每層神經元輸入輸出方差一致。 這裡先介紹一個方差相乘的公式,以便理解Xav
【資料探勘筆記十】聚類分析:基本概念和方法
1)10.聚類分析:基本概念和方法聚類是一個把資料物件集劃分成多個組或簇的過程,使得簇內的物件具有很高的相似性,但與其他簇中的物件很不相似。相異性和相似性根據描述物件的屬性值評估,涉及到距離度量。10.1 聚類分析聚類分析把一個數據物件(或觀測)劃分子集的過程。由聚類分析產生