構建機器學習專案(一)- ML Strategy(1)
從本篇開始將是 deeplearning.ai的第三門課程,構如何構建機器學習專案以及需要注意的點
Introduction to ML Strategy
Why ML Strategy
為什麼要使用所謂ML Strategy,比如我們現在要設計一個影象分類器,我們已經得到了90%的accuracy,那麼接下來我們要如何再去提高它的accuracy呢,如下,我們有非常非常多的方向和方法,但是哪個方法方向是最有效的,我們並不知道,所以需要ML Strategy來幫我們進行選擇。

Orthogonalization
orthogonalization字面上理解就是正交化,在向量空間中呢,正交化即表示不相關,我的變化不會影響到你,你的變化不會影響到我。在ML Strategy中,orthogonalization表示,我們希望我們實施的策略具有針對性,比如在減小bias的同時,不希望variance有變化,這樣有助於我們針對問題進行逐步調節,不會互相影響導致最後所有東西都在變化。
如下圖,在ML專案中,我們首先希望模型能夠很好的fit我們的訓練集,然後希望能夠很好的fit我們的dev set,再然後希望它能夠fit我們的測試集,最後在現實中能夠很好地執行。orthogonalization保證我們在已經調整模型使其可以很好fit我們訓練集地情況下,我們在調dev set的時候,不會影響到我們的train accuracy。這樣我們才能一步步往下走。而early stopping就不是一種滿足orthogonalization的策略,因為它在減小dev error的時候同時增大了我們的bias,使train error增大。

那麼針對fit training set,我們可以嘗試更復雜的網路,使用更復雜的優化演算法等。
針對fit dev set,我們可以運用regularization,增大我們的training set等。
針對fit test set,我們可以增大 dev set來防止模型對dev set 過擬合。
最後如果fit test set well,但不能在現實中很好的運用,我們就需要改變我們的dev set,因為現實資料與dev set分佈不同或者改變我們的cost function,說明我們所最小化的東西不對。
Setting up your goal
Single number evaluation metric
對於這個問題,機器學習筆記有所講述,即運用單一的數值來衡量我們模型的好壞會有助於我們推進我們模型的改進。比如我們運用分類的accuracy來衡量,或者運用綜合了precision和recall的F1-score來衡量等。
Satisficing and Optimizing metric
有些時候我們很難將所有的因素結合成為一個single metric,如下,我們要同時考慮accuracy和running time。那麼這個時候,我們可以將兩個引數一個設定為Optimizing metric,即需要我們優化的引數,另一個設定為Satisficing metric,即需要滿足的引數。那麼我們satisficing metric設為需要小於100ms,即在滿足running time小於100ms的條件下,accuracy最大的為最優。當然如果我們有N個因素,我們就需要將其中一個選為Optimizing metric,剩下的N-1全部為satisficing metric。

Train/dev/test distributions
這裡再次強調dev set的作用,我們設計了很多模型並且使用trainning set去訓練這些模型,然後需要通過dev set來對所有的模型測試,選出一個效果最好的,最後再使用test set進行測試。
對於資料集的分佈,我們希望dev/test 這兩部分的資料集要來自同一分佈,只有這樣dev set測試出來的效果好的模型,才有可能在test set上取得很好的結果,那麼這就要求dev/test set要滿足下面這個guideline。有了這個guideline才能保證我們的模型在fit dev/test set的情況下,有可能在現實中取得好的效果。

Size of the dev and test sets
對於資料集劃分,即不再單純按照60/20/20劃分,而是根據已有的資料量大小進行劃分,dev和test sets希望滿足以下要求。至於這個要求也是要根據已有資料量的大小來決定,比如現在百萬級,千萬級的資料,1%即可。也有一種情況沒有test set,只有dev set,但是這種情況不推薦,這就需要採用較大的dev set以保證,訓練的模型不會對dev set過擬合。

When to change dev/test sets and metrics
有時候我們並不能一開始就預見我們選取的dev set和metrics是否能夠幫助訓練一個能夠非常好的運用到實際當中的模型,所以在專案進行過程中,有時候我們需要改變我們的dev/test sets或者改變我們的metrics。
第一個例子:影象二分類問題(是否是貓)
我們現在有兩個演算法,一個error 3%,一個error 5%。當然從error的角度,我們選擇演算法A,但是演算法A會錯誤地將很多淫穢圖片判定為貓,這是我們作為使用者來說不希望看到的。那麼這個時候說明如果將演算法A放到實際中,那麼效果不好,於是我們需要改變我們的error。

第二個例子:一樣的問題
我們用於dev/test是非常清晰的圖片,而使用者上傳的圖片是非常blurry的,那麼這個時候我們的分類器放到實際中效果並不好,於是我們需要改變我們的dev set。

這裡同樣體現了orthogonalization,第一步我們定義metric去評定我們的模型,第二步我們需要如何改變metric使它能夠work well。
Comparing to human-level performance
Why human-level performance
因為近年深度學習的飛速發展,深度學習在許多領域都取得了重大突破,接近甚至趕超了人類在這些領域所能達到的accuracy。那麼瞭解human-level performance能夠幫助我們進一步提高我們的正確率,這裡提出一個叫做bayes optimal error,表示最優的誤差,無論如何都無法超過的誤差,即有些圖片太模糊,無法識別,有些音訊太嘈雜,無法判斷等。那麼human-level performance和bayes optimal error之間還有一段間隔。
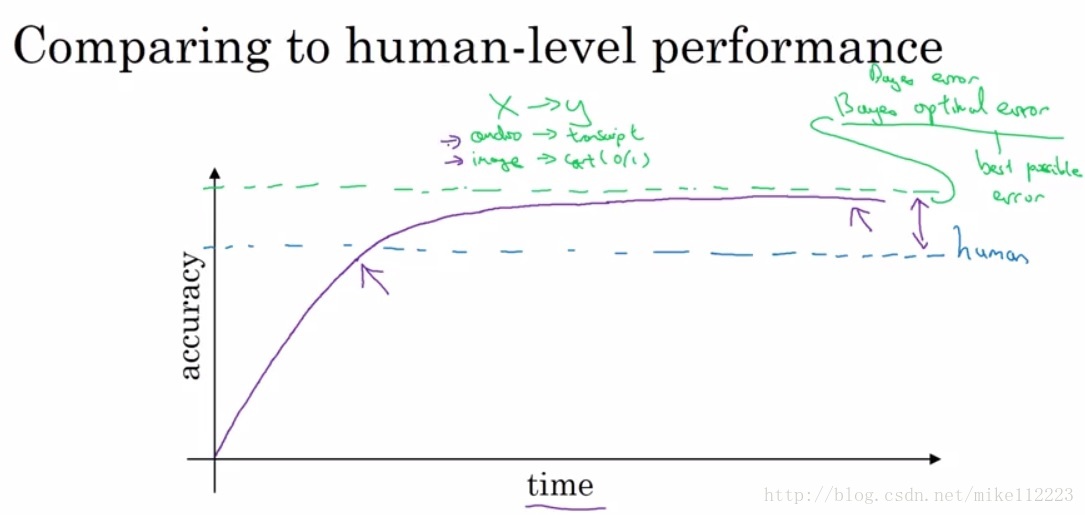
從上圖中,我們可以看出在accuracy低於human-level的時候,accuracy增長的很快,而超過human-level之後就會上升的很慢,這個原因是什麼呢。因為在低於human-level的時候,我們可以:
1. Get labeled data from humans
2. Gain insight from manual error analysis: Why did a person get this right?
3. Better analysis of bias/variance
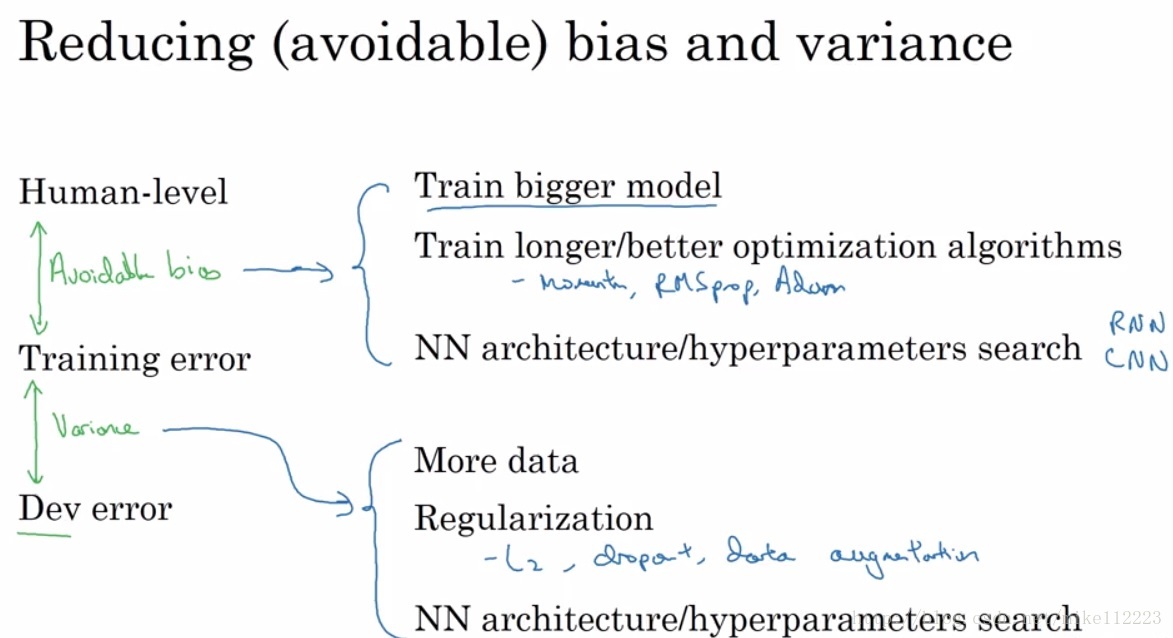
那麼我們為什麼需要human-level performance呢,這是為了更好的判斷我們的模型所存在的問題,到底是bias的問題大,還是variance的問題大,這樣決定我們先著手解決哪個問題。我們知道variance是根據train/dev error之間的差距來決定的,可是bias的話,我們不能單純使用train error和0來決定,於是我們引入human-level error,取train error 和human-level做差和train/dev error進行比較,誰大決定先解決誰。由於這裡的bias不再是train error 與 0 的差,於是我們將其定義為”avoidable bias”。即通過優化這個誤差是可以消除的。
Understanding human-level performance
Human-level error沒有一個很固定的值,如下圖,都可以作為human-level error,這一般是根據我們的目的來決定的。如果我們要發表一篇論文,那麼我們決定使用Typical doctor,因為如果我們的error小於Typical doctor,我們有理由相信它是一個好的成果。如果我們想要以Bayes error作為上限,那麼我們使用Team of experienced doctors。因為我們知道Bayes optimal error是一定小於任何human-level的,但是我們又不會知道確切值,所以我們使用最小的human-level來近似Bayes optimal error。

Surpassing human-level performance
如下圖左,當我們的train error 沒有超過我們的human-level error的時候,我們對human-level/train error做差與train/dev error做差進行比較,來確定我們下一步幹嘛。如下圖,0.2大於0.1,所以我們要降低variance。
下圖右,如果我們的training error 已經高於human-level error,這個時候呢,我們優化的方法和方向將不明確,但這並不意味著沒有辦法再make progress了。因為我們不知道真正的bayes optimal error是多少,理論上我們是可以接近這個值的。

Improving your model performance
接下來進行總結,對於有監督學習來說,有兩個基本的假設:
1. 我們可以非常好地擬合我們的training set,即我們可以基本消除avoidable bias。
2. 訓練出的模型能夠很好的泛化到我們的dev/test set上,即variance也可以很小。
小廣告
淘寶choker、耳飾小店 物理禁止
女程式設計師編碼時和編碼之餘 都需要一些美美的choker、耳飾來裝扮自己
男程式設計師更是需要常備一些來送給自己心儀的人
淘寶小店開店不易 希望有緣人多多支援 (O ^ ~ ^ O)
本號是本人 只是發則小廣告 沒有被盜 會持續更新深度學習相關博文和一些翻譯
感謝大家 不要拉黑我 ⊙﹏⊙|||°