
機器學習筆記(一)微積分
微積分
@(Machine Learning)[微積分, 概率論]
1.夾逼定理:
當
2.極限存在定理:
- 單調有界數列必有極限
- 單增數列有上界,則其必有極限
3.導數:
導數就是曲線的斜率,是曲線變化快慢的反應。
- 二階導是斜率變化快慢的反應,表徵曲線的凹凸性,但是方向呢總是指向軌跡曲線凹的一側。
常用函式的導數:
C′=0
(xn)′=nxn−1
(sinx)′=cosx
(cos x)′=−sinx
(ax)′=axlna
(ex)′=ex
(logax)′=1xlogae
(lnx)′=1x
(u+v)′=u′+v′
(uv)′=u′v+uv′
重要應用:冪指函式(牢記套路)
- 已知函式
f(x)=xx,x>0 , 求f(x) 的最小值: - 解:
t=xx - 取指數———>
lnt=xlnx - 兩邊對x求導———>
1tt′=lnx+1 - 令
t′ 等於0(取駐點求最小值)———>lnx+1=0 x=e−1 t=e−1e
上面就是求冪指函式的一般套路,像求
最大似然估計一定會用到這個套路
看一下結果和程式碼:
# -*- coding:utf8 -*-
import math
import matplotlib.pyplot as plt
if __name__ == '__main__':
x = [float(i)/100 for i in range(1,150)]
y = [math.pow(i,i) for i in x]
plt.plot(x, y, 'r-', linewidth = 3, label = 'y(x)=x^x')
plt.grid(True)
plt.xlabel('X')
plt.ylabel('Y')
plt.show() 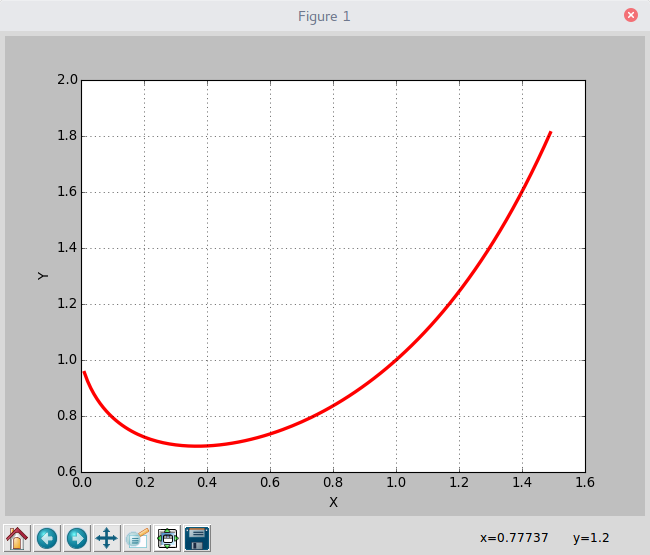
4.Taylor公式 — Maclaurin公式
如果我們知道了函式的一階導,二階導。。n階導就可以寫出
x0 泰勒公式:一階導×差距+二階導×差距除以階乘到最後x的一個高階無窮小(扔掉)。
f(x)=f(x0)+f′(x0)(x−x0)+f′′(x0)2!(x−x0)2+....+fn(x0)n!(x−x0)n+Rn(x)
如果我們把x0 換成0便得到了邁克勞林公式。
f(x)=f(0)+f′(0)x+f′′(0)2!x2+....+fn(0)n!xn+o(xn)
Taylor公式的應用:
數值計算:初等函式值的計算(在原點展開)
相關推薦
機器學習筆記(一)微積分
微積分 @(Machine Learning)[微積分, 概率論] 1.夾逼定理: 當x∈U(x0,r)時,有g(x)≤f(x)≤h(x)成立,並且limx→x0g(x)=A,limx→x0h(x)=A那麼:limx→x0f(x)=A 2.極限存
機器學習筆記(一)
get 實現 mach 理論 怎樣 算法 分類 AI 結構 1、基礎概念 什麽是機器學習? 機器學習(Machine Learning, ML)是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、算法復雜度理論等多門學科。專門研究計算機怎樣模擬或實現人類的
模式識別與機器學習筆記(一)
本系列博文是對研一課程《模式識別與機器學習》的隨堂筆記,希望將老師所講的與自己的見解記錄下來,方便加深自己的理解以及以後複習檢視,筆記完全按照老師所講順序,歡迎交流。 一、模式識別與機器學習的基本問題 機器學習主要解決以下四類問題: 1.監督學習:指的是訓練的資料既包括特徵(feat
機器學習筆記(一):最小二乘法和梯度下降
一、最小二乘法 1.一元線性擬合的最小二乘法 先選取最為簡單的一元線性函式擬合助於我們理解最小二乘法的原理。 要讓一條直接最好的擬合紅色的資料點,那麼我們希望每個點到直線的殘差都最小。 設擬合直線為
機器學習筆記(一)線性迴歸模型
一、線性迴歸模型 (一)引入—梯度下降演算法 1. 線性假設: 2. 方差代價函式: 3. 梯度下降: 4. : learning rate (用來控制我們在梯度下降時邁出多大的步子,值較大,梯度下降就很迅速) 值過大易造成無法收斂到minimum(每一步邁更大)
吳恩達機器學習筆記(一),含作業及附加題答案連結
吳恩達機器學習筆記(一) 標籤(空格分隔): 機器學習 吳恩達機器學習筆記一 一機器學習簡介 機器學習的定義 監督學習 非監督學習
深入理解java虛擬機器學習筆記(一)
Java記憶體區域模型 Java虛擬機器在執行Java程式的過程中,會把它所管理的記憶體區域劃分為若干個不同的資料區域,這些區域一般被稱為執行時資料區(Runtime Data Area),也就是我們常說的JVM記憶體。 執行時資料區通常包括以下這幾個部分: 程式計數器(Program Counte
深入理解JAVA虛擬機器學習筆記(一)JVM記憶體模型
一、JVM記憶體模型概述 JVM記憶體模型其實也挺簡單的,這裡先提2個知識點: 1、組成:java堆,java棧(即虛擬機器棧),本地方法棧,方法區和程式計數器。 2、是否共享:其中方法區和堆區是執行緒共享的,虛擬機器棧,本地方法棧和程式計數器是執行緒私有的,也稱執行緒
Java虛擬機器學習筆記(一):記憶體區域與HotSpot虛擬機器物件探祕
執行時資料區域 Java虛擬機器在執行Java程式的過程中會把它所管理的記憶體劃分為若干個不同的資料區域。這些區域都有各自的用途,以及建立和銷燬的時間,有的區域隨著虛擬機器程序的啟動而存在,有些區域則依賴使用者執行緒的啟動和結束而建立和銷燬。根據《Java虛擬機
機器學習筆記(一):極大似然估計與貝葉斯估計的區別
似然函式: 樣本資料的分佈和在引數為下的概率分佈的相似程度 極大似然估計:只要求出符合樣本資料分佈的最優引數即可,不需要考慮先驗。 貝葉斯估計 MAP(最大後驗估計)
機器學習筆記(一)----線性方程擬合的梯度下降法
機器學習 引言 定義:一個年代近一點的定義,由 Tom Mitchell 提出,來自卡內基梅隆大學,Tom 定義的機器學習是,一個好的學習問題定義如下,他說,一個程式被認為能從經驗 E 中學習,解決任務 T,達到效能度量值P,當且僅當,有了經驗 E 後,
機器學習筆記(一)——基於單層決策樹的AdaBoost演算法實踐
基於單層決策樹的AdaBoost演算法實踐 最近一直在學習周志華老師的西瓜書,也就是《機器學習》,在第八章整合學習中學習了一個整合學習演算法,即AdaBoost演算法。AdaBoost是一種迭代演算法,其核心思想
機器學習筆記(一):關於隱含馬爾科夫模型
這篇文章是我在看完吳軍老師的數學之美一書中關於隱馬爾科夫模型之後所寫,旨在記錄一下自己對隱馬爾科夫模型的認識, 隱馬爾科夫模型我在很早之前就有所接觸,在學習語音識別的時候,會涉及到隱馬爾科夫模型,當時是完全不懂,現在雖然還是一知半解,因為沒有再次去使用,接下來的主攻方向是機器視覺,對隱馬爾可
周志華機器學習筆記(一)
新人一枚,既是機器學習的初學者,也是首次發部落格。謹以此記錄我的學習體會,做一些總結。望與大家共同學習、共同進步。文中若有內容錯誤或有措詞不嚴謹之處,望大家不吝指出。謝謝! 機器學習中的基本概念 基本術語 根據上圖我們可以用一個三維空間來了解以
機器學習筆記(一)樸素貝葉斯的Python程式碼實現
上研究生的時候,一心想讀生物資訊學的方向,由此也選修了生物數學,計算生物學等相關課程。給我印象最深的是給我們計算生物學的主講老師,他北大數學系畢業,後來做起了生物和數學的交叉學科研究。課上講的一些演算法比如貝葉斯,馬爾科夫,EM等把我給深深折磨了一遍。由於那時候
機器學習筆記(一)邏輯迴歸與多項邏輯迴歸
1.邏輯迴歸與多項邏輯迴歸 1.1什麼是邏輯迴歸? 邏輯迴歸,可以說是線上性迴歸的基礎上加上一個sigmoid函式,將線性迴歸產生的值歸一化到[0-1]區間內。sigmoid函式如下:
機器學習筆記(一):梯度下降演算法,隨機梯度下降,正規方程
一、符號解釋 M 訓練樣本的數量 x 輸入變數,又稱特徵 y 輸出變數,又稱目標 (x, y) 訓練樣本,對應監督學習的輸入和輸出 表示第i組的x 表示第i組的y h(x)表示對應演算法的函式 是
機器學習筆記(一) 邏輯斯蒂迴歸LR
本文是在學習完李航老師的《統計學習方法》後,在網上又學習了幾篇關於LR的部落格,算是對LR各個基礎方面的一個回顧和總結。 一 簡述 邏輯斯蒂迴歸是一種對數線性模型。經典的邏輯斯蒂迴歸模型(LR
cs229 斯坦福機器學習筆記(一)-- 入門與LR模型
房價 com 還要 實現 最大 title pid 分布 fcm 版權聲明:本文為博主原創文章,轉載請註明出處。
《機器學習》學習筆記(一):線性回歸、邏輯回歸
ros XA andrew ID learn 給定 編程練習 size func 《機器學習》學習筆記(一):線性回歸、邏輯回歸 本筆記主要記錄學習《機器學習》的總結體會。如有理解不到位的地方,歡迎大家指出,我會努力改正。 在學習《機器學習》時,我主要是