
pandas python 分組統計的方法
阿新 • • 發佈:2019-01-11
首先,看看本文所面向的應用場景:我們有一個數據集df,現在想統計資料中某一列每個元素的出現次數。這個在我們前面文章《如何畫直方圖》中已經介紹了方法,利用value_counts()就可以實現(具體回看文章)
但是,現在,我們考慮另外一個場景,我們假如要想統計其中兩列元素出現次數呢?舉個栗子:
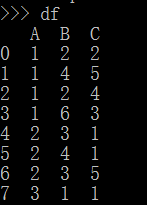
在df資料集中,如果我們想統計A、B兩列的元素的出現情況,也就是說,得到如下表。
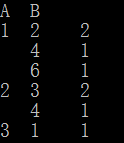
從上面的最後一列可以看到,在A、B兩列中,1 2 出現了2次,1 4 出現1次 ,1 6出現1次,2 3出現了2次, 2 4 出現1次, 3 1出現了1次
具體實現的程式碼:
import pandas as pd df=pd.DataFrame([[1,2,2],[1,4,5],[1,2,4],[1,6,3],[2,3,1],[2,4,1],[2,3,5],[3,1,1]],columns=['A','B','C'])
gp=df.groupby(by=['A','B'])
gp.size()所以,如果想統計更多列,只要在groupby()中的by引數新增就可以,例如統計3列。
gp=df.groupby(by=['A','B','C'])由gp.size()得到的是可以mulitiindex Series。
下面,要轉化成DataFrame的結構。
newdf=gp.size()
newdf.reset_index(name='times')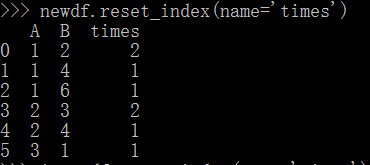
其中name中引數就是我們可以為最後一列新增新的名字,例如這裡的“times”
這個時候newdf已經是DataFrame的型別了。