
Sklearn學習之路(2)——圍繞評估器轉換器展開討論
1. 寫在前面
在上一講中,我們對於Sklearn框架有了一個較為直觀的認識,但是對於其中的細節部分,可能還是不知甚解。這次,我們將會詳細的介紹其中的一些知識,包括:Sklearn版本注意事項、最基本的評估器與轉換器、fit、transform與fit_transform的區別、pipeline使用,tfidf與CountVectorizer方法等。
2. Sklearn版本注意事項
在網上很多Sklearn的例子,但是很多時候copy下來又執行不了,其實很多時候是因為Sklearn版本不同。機器學習是一個非常活躍的領域,而Sklearn又是一個非常活躍的框架,版本更新迭代速度很快,而且修改比較多,很多時候上一個版本的函式與方法,在下一個版本中就已經不能使用了。大家需要自己去Sklearn官網裡檢視最新的API。另外一點,好在Pycharm裡會提醒,在接下來的版本中可能移除的方法,讓你及時調整程式碼。因此如果出現了網上的示例不能執行的情況,有可能是版本已經更新了。
3. 評估器與轉換器
說到評估器與轉換器,大家可能沒有一個直觀的認識。事實上,基本上大部分的分類器都屬於評估器,這點你可以從分類器的包名可以看到:

這裡面類彙總,第一個為基礎評估器,第二個為基礎分類器,最後一個為基礎轉換器。基本上所有的評估器與轉換器都有三個基本方法,fit,transform,fit_transform。為什麼著重講這個,因為在pipeline中,它的最後一部分為評估器,也就是說最後一步一定是個分類器,而前面的預處理、降維、正則化等都是轉換器。這點我們會在後面講到。
4. fit、transform與fit_transform的區別
其實程式設計師最應去的一個地方就是Stackoverflow,那裡有最權威、最清楚的Bug除錯解決方案。雖然大部分都是英語,但是英語解釋的比較確切。
fit原義指的是安裝、使適合的意思,其實有點train的含義但是和train不同的是,它並不是一個訓練的過程,而是一個適配的過程,過程都是定死的,最後只是得到了一個統一的轉換的規則模型。
transform則指的是轉換.。從可利用資訊的角度來說,轉換分為無資訊轉換和有資訊轉換。無資訊轉換是指不利用任何其他資訊進行轉換,比如指數、對數函式轉換等。有資訊轉換從是否利用目標值向量又可分為無監督轉換和有監督轉換。無監督轉換指只利用特徵的統計資訊的轉換,統計資訊包括均值、標準差、邊界等等,比如標準化、PCA法降維等。有監督轉換指既利用了特徵資訊又利用了目標值資訊的轉換,比如通過模型選擇特徵、LDA法降維等。
而fit_transform方法則是把上述2個過程統一起來,對模型先訓練,然後根據輸入的訓練資料返回一個轉換矩陣。這個過程通常只存在訓練過程中。在Pipeline中尤為明顯。
5. pipeline的使用
給出一幅圖,就可以大致瞭解pipeline的執行方式與流程:
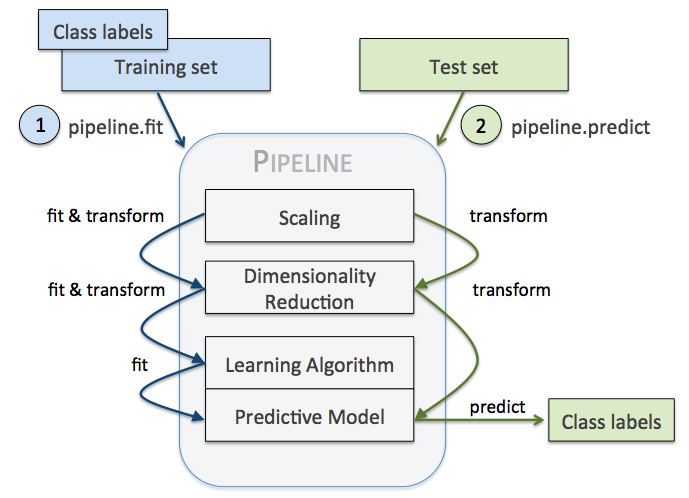
這裡我們可以看到pipeline的最後一步一定是一個分類器,而開始部分可以是一個規約化,中間可以是降維、可以是特徵選取等等一套流程。當然,這裡用的都是包裡自帶的評估器與分類器,如果想自己寫其中的一個過程然後新增到整個pipeline中,還需要繼承基類(第3節講到)後才能新增進去。
具體的使用樣例如下:
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr = Pipeline([('sc', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression(random_state=1))
])
pipe_lr.fit(X_train, y_train)
print('Test accuracy: %.3f' % pipe_lr.score(X_test, y_test))
# Test accuracy: 0.9476. CountVectorizer()與TfidfTransformer()
在第三節中,我們講到了評估器與轉換器,這2個都是有上面那3個方法,評估器可能還會多一個predict預測這個方法。主要是用來分類的。
同樣的,評估器裡的演算法多為機器學習演算法,而轉換器裡的演算法多為轉換演算法。像TFIDF演算法就是轉換器,它只不過是把一個文件列表轉換為一個TFIDF矩陣,但是如何轉換是有一個模型的,這個模型這個被訓練語料fit後的模型,它同樣可以被用來轉換(transform)測試語料,例如下面這程式碼:
#初始化一個ftidf物件
tfidf=TfidfTransformer();
from sklearn.feature_extraction.text import CountVectorizer
#初始化一個統計詞頻物件
count_vect = CountVectorizer()
#返回的是一個稀疏矩陣
train_data = count_vect.fit_transform(train_data)
#通過稀疏矩陣獲得tfidf矩陣
train_result=tfidf.fit_transform(train_data);
#使用同樣的統計詞頻模型來生成訓練語料的統計詞頻矩陣。
test_data = count_vect.transform(test_data)
#使用同樣的模型對測試語料轉換,可以得到和測試語料同樣的TFIDF矩陣。
test_result=tfidf.transform(test_data);這裡我們在使用tfidf轉換器的同時需要使用一個統計詞頻轉換器,因為統計詞頻轉換器可以把文章列表轉換為一個詞頻的矩陣,如下表:
| 文件順序 | 單詞1 | 單詞2 | ··· |
|---|---|---|---|
| 1 | 1 | 2 | ··· |
| 2 | 0 | 2 | ··· |
| ··· | ··· | ··· | ··· |
但是其實它真實儲存的時候是以稀疏矩陣儲存,也就是隻儲存非0的單元。這樣做其實有2點好處。
- 節省空間,因為統計詞頻顯然是一個稀疏的矩陣,詞表為列數,而一個文件含有的單詞數非常少。因此只儲存非0的單元節省空間。
- 利於擴充套件,我們的詞表使用的訓練集訓練的,而如果使用同一轉換器來轉換測試集的時候,即使原有詞表中未包含測試集內的單詞,也很容易擴充套件,只需要在稀疏矩陣後新增一個矩陣單元即可。例如:
(0, 18375) 1
(0, 19325) 1
(0, 39321) 1
(0, 45163) 1
(0, 110448) 1
(0, 22986) 1
(0, 115259) 1
(0, 31639) 1
上邊是第一行的稀疏矩陣,最大的值為115259,也就是說最大的列假設為115259列,如果測試集中出現了一個單詞,這個單詞在前115259個詞都沒出現過,這時候,只需要:
(1,115260) 1
即可,非常容易擴充套件。
這時候,才能使用tfidf轉換器,把這個轉換成相應的tfidf值,因為只有這樣做過了,tfidf轉換器才能方便的轉換。因為這時候,無論是一篇文章的詞總數,還是文件總數,還是出現目標詞的文件數都非常容易的統計出,這樣對於TFIDF公式:
其實最後的+1不一定放上去,主要是為了防止查詢原語料中不存在的詞時,分母不為0。
使用tfidf轉換器後,整個稀疏矩陣就成這樣子了:
(0, 31639) 0.350232605058
(0, 115259) 0.287191449938
(0, 22986) 0.325286181826
(0, 110448) 0.38664944433
(0, 45163) 0.399257482535
(0, 39321) 0.308066927057
(0, 19325) 0.350232605058
(0, 18375) 0.403205473668
大家可以看到,與詞頻統計的稀疏矩陣的非0點座標是一致的不同的就是其中的值。
7. 小結
我們這次對於sklearn有了一個更加明確的認識,在此基礎上已經可以做一些特定的實驗了。但是如何進行特徵選擇和最終的實驗評估報告還並未說明,這幾部分將在以後的文章中更新。
相關推薦
Sklearn學習之路(2)——圍繞評估器轉換器展開討論
1. 寫在前面 在上一講中,我們對於Sklearn框架有了一個較為直觀的認識,但是對於其中的細節部分,可能還是不知甚解。這次,我們將會詳細的介紹其中的一些知識,包括:Sklearn版本注意事項、最基本的評估器與轉換器、fit、transform與fit_tra
USB小白學習之路(2)端點IN/OUT互換
speed 9.png 現在 script des 裏的 宋體 dir info 端點2(out)和端點6(in)的out_in互換 註:這裏的out和in都是以host為標準說的,out是host的out,在設備(Cy7c68013)這裏其實是輸入端口;in是host的i
Python學習之路(2)——Python種類介紹
VM 種類 廣泛 分享 java字節碼 流程 字節碼 基礎上 python Python的種類 Cpython Python的官方版本,使用C語言實現,使用最為廣泛,CPython實現會將源文件(py文件)轉換成字節碼文件(pyc文件),然後運行在Python虛擬
Panda的學習之路(2)——pandas選擇數據
定義 對比 pan panda pri 學習之路 進行 strong 比較 首先定義panda dates=pd.date_range(‘20130101‘,periods=6) # print(dates) df=pd.DataFrame(np.arange(24).r
LTE學習之路(2)——概述
【LTE的設計目標】 頻寬靈活配置:支援1.4MHz, 3MHz, 5MHz, 10Mhz, 15Mhz, 20MHz 峰值速率(20MHz頻寬):下行100Mbps,上行50Mbps 控制面延時小於100ms,使用者面延時小於5ms 能為速度>350km/h的
ESP8266 WIFI模組學習之路(2)——模組與微控制器連線進行遠端操作
上一個部落格:ESP8266 WIFI模組學習之路(1)是關於對串列埠連線的,簡單驗證ESP8266是怎麼樣連線及其功能驗證,下面將通過微控制器連線,和手機進行遠端操作。 ESP8266和微控制器的連線,我這裡的微控制器型號為:STC12C5A60S2 ESP8266
Android學習之路(2)--UI設計實驗——手機資訊頁面
UI設計實驗——手機資訊頁面 實驗目的 1.掌握相對佈局、線性佈局的使用 2.掌握樣式的使用 3.掌握如何對程式進行國際化 實驗環境 裝有Android開發環境的計算機 實驗任務 任務:手機資訊頁面 實驗目的介面 執行效果介面
Common lisp 學習之路(2)
相關快捷鍵 C-x C-f 建立檔案 C-c C-c 編譯函式 C-c C-z(C-x b) 進入命令列 C-c C-s 儲存檔案 M-x slime 開啟一個命令列 相關命令之理解: (list :a 1 :b 2 :c 3)其中list相當與宣告一種資料結構,:a相當於
es6學習之路(2):作用域,不存在變數提升,避免暫時性死區,與全域性物件的屬性脫鉤
1、ES6 新增了let命令,用來宣告變數。它的用法類似於var. const宣告一個只讀的常量。一旦宣告,常量的值就不能改變.const宣告的變數不得改變值,這意味著, const 一旦宣告變數,就必須立即初始化,不能留到以後賦值。 這2個都是在所在
Sklearn學習之路(1)——從20newsgroups開始講起
1. Sklearn 簡介 Sklearn是一個機器學習的python庫,裡面包含了幾乎所有常見的機器學習與資料探勘的各種演算法。 具體的,它常見的包括資料預處理(preprocessing)(正則化,歸一化等),特徵提取(feature_extractio
ABP框架(asp.net core 2.X+Vue)模板專案學習之路(一)
前言: 第一次接觸ABP的專案是在2018年6月份,但是當時沒有深入具體的研究,而今天因為工作的需要,需要學習、瞭解這個框架,在時隔半年之後,今天重新下載了這個專案,雖然在園子裡有很多前輩們寫的這類的文章,但是我還是會在部落格園中記錄一下學習的過程,一是希
react學習之路(2.2)-----資料傳遞(props(子傳父級),context)
react學習之路,資料傳遞(props,context); 再講props子父級之前,先學習一下context這個非常NB的資料接收容器,如何正確的使用,接下來為大家介紹, 用它之前,我們必須要知道有個叫prop-types的東西,從英文我們就知道意思就是叫我們定義資料型
Struts2 學習之路(二):2.2 完成簡單的統計使用者線上人數小功能
實時更新使用者線上人數(通過將使用者人數資料放入application的域屬性裡實現) 使用者登入後,顯示使用者名稱和當前線上人數+1 使用者登出後,當前線上人數-1 程式碼 1.前臺請求頁面
組合語言學習之路(7)------------輸入10進位制數,將其轉換為2進位制數,存放在ax中,再將其轉換為ASCII碼並輸出
data segment inf1 db "please input a number(1-361):$" ibuf db 7,0,6 dup(0) obuf db 6 dup(0) data ends c
AI學習之路(10): 張量的常量2
tf.fill(dims, value, name=None)建立一個張量填充指定的常數。引數:dims: 整數型別的列表物件,或者一維張量,表示行列形式。value: 填充的常量(0維張量)返回值:填充指定的張量常量。例子:#python 3.5.3 蔡軍生 #htt
Struts2 學習之路(二):2.4 Struts2(2.5.14.1版本)中的萬用字元匹配問題
struts.xml 配置檔案中萬用字元的匹配 可以匹配action節點中的class屬性,method屬性,result子節點的name屬性,甚至是result子節點的路徑內容 因為2.5.x版本
hadoop學習之路(一)---叢集環境搭建(2.7.3版本)
三:下載解壓 hadoop 到某個目錄(例如 /usr/loacl/hadoop) 四:賬號建立: 即為hadoop叢集專門設定一個使用者組及使用者,這部分比較簡單,參考示例如下: groupadd hadoop //設定h
python學習之路(四)
[1] size class dex epc uri msu 語句 這就是 繼續昨天的學習,學到了數組。 首先有兩個數組,name1和name2.我們可以將兩個數組合並 name1=[1,2,3,4] name2=[5,6,7,8] names=name1.extend(
Linux學習之路(四)幫助命令
查看系統 lin 查看 inux 舉例 config pro nbsp 雜項 幫助命令man .man 命令 #獲取指定命令的幫助 .man ls #查看ls的幫助 man的級別 1 查看命令的幫助 2 查看可被內核調用的函數的幫助 3 查看函數的
python學習之路(三)使用socketserver進行ftp斷點續傳
def += __init__ con 不存在 不為 local 接收 class 最近學習python到socketserver,本著想試一下水的深淺,采用Python3.6. 目錄結構如下: receive_file和file為下載或上傳文件存放目錄,ftp_clie