
Idea基於maven,java語言的spark環境搭建
環境介紹:IntelliJ IDEA開發軟體,hadoop01-hadoop04的叢集(如果不進行spark叢集測試可不安裝),其中spark安裝目錄為/opt/moudles/spark-1.6.1/
準備工作
首先在叢集中的hdfs中新增a.txt檔案,將來需在專案中進行單詞統計

構建Maven專案
點選File->New->Project…
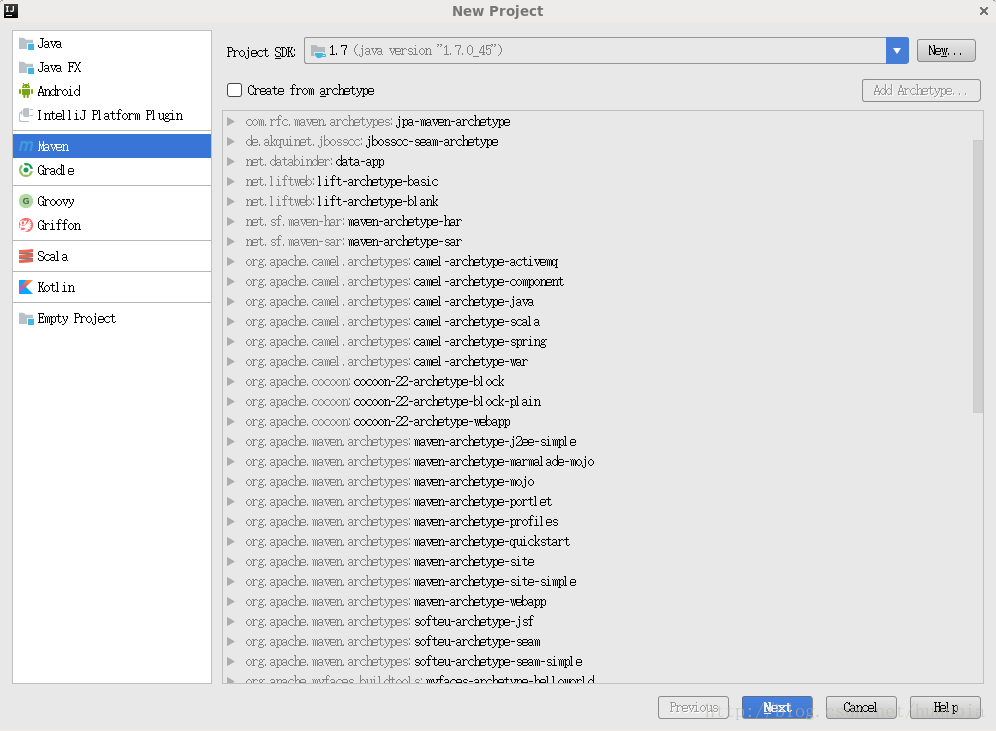
點選Next,其中GroupId和ArtifactId可隨意命名
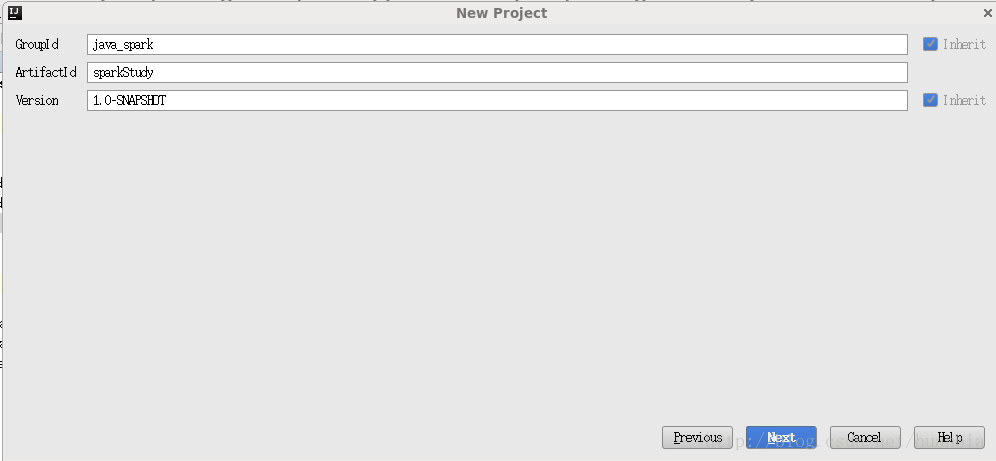
點選Next
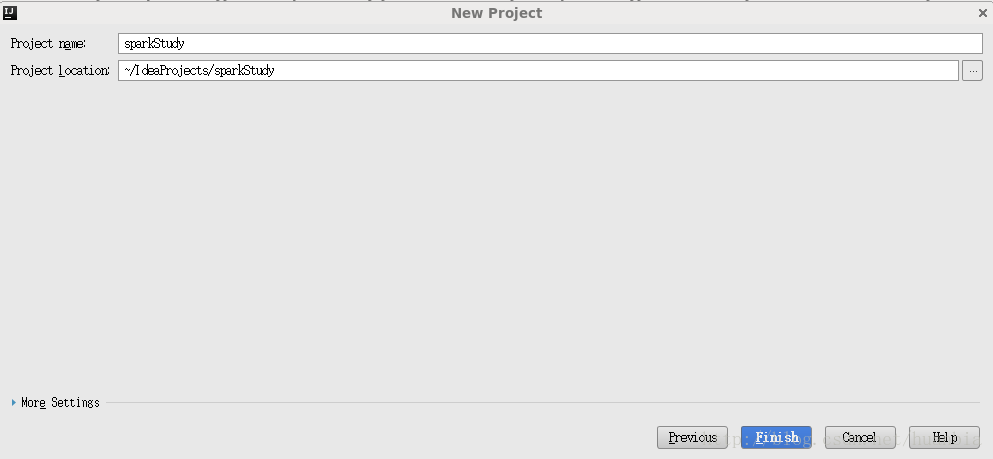
點選Finish,出現如下介面:

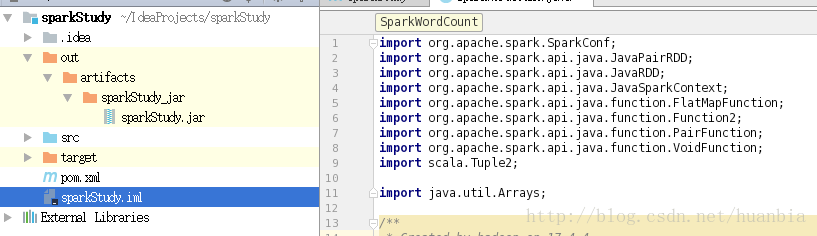
書寫wordCount程式碼
請在pom.xml中的version標籤後追加如下配置
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
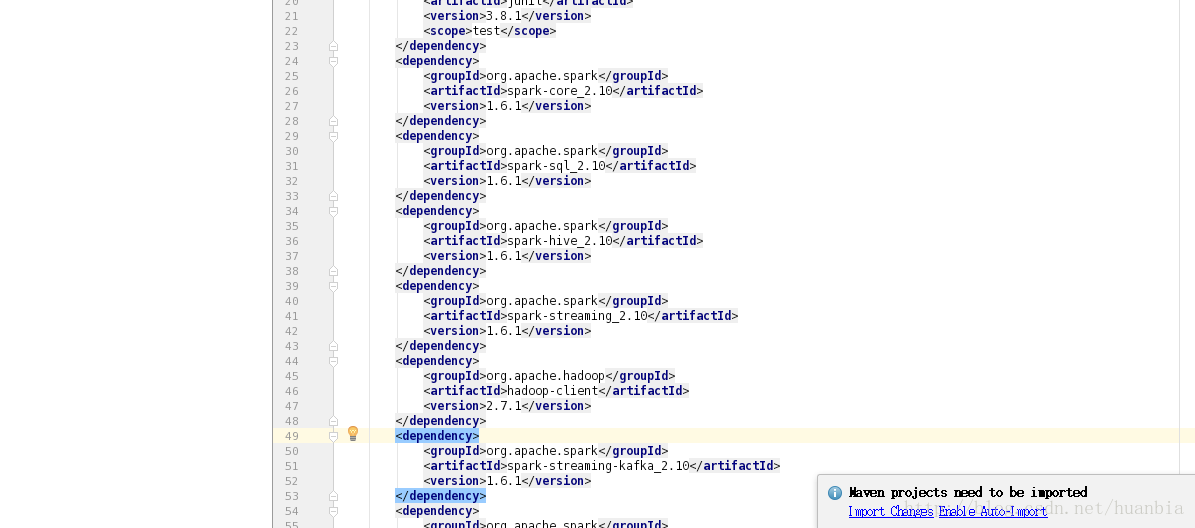
<version>3.8.1</version 點選右下角的Import Changes匯入相應的包
點選File->Project Structure…->Moudules,將src和main都選為Sources檔案
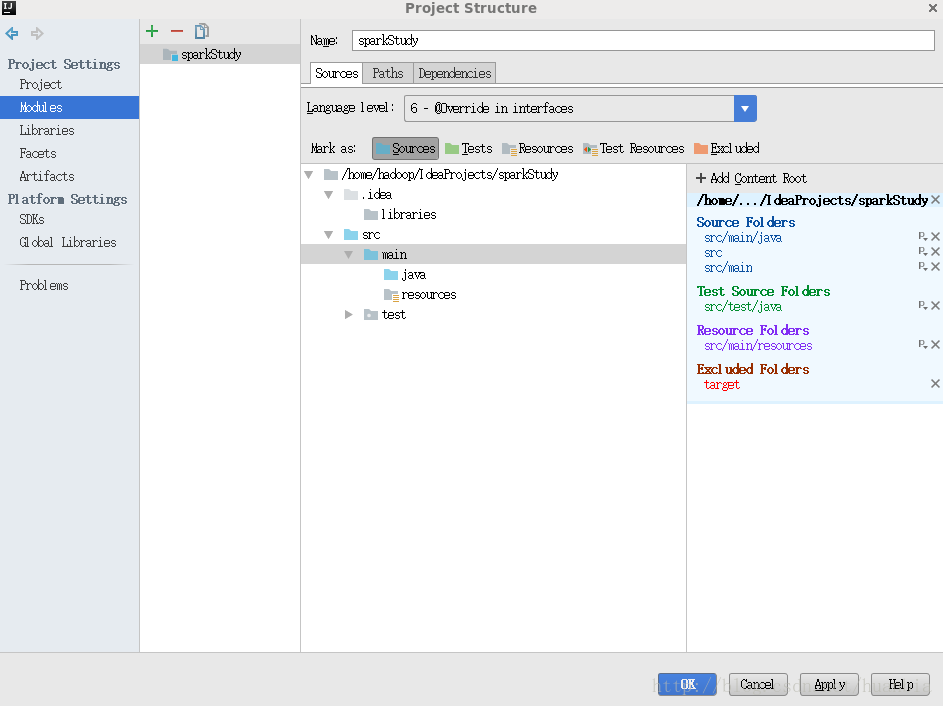
在java資料夾下建立SparkWordCount java檔案
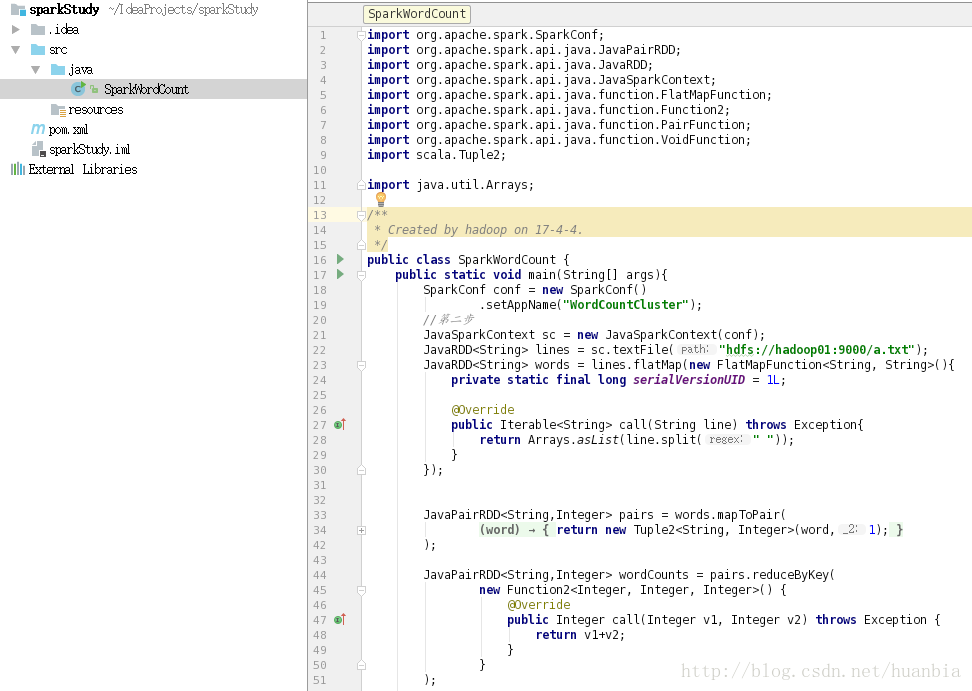
該檔案程式碼為:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by hadoop on 17-4-4.
*/
public class SparkWordCount {
public static void main(String[] args){
SparkConf conf = new SparkConf()
.setAppName("WordCountCluster");
//第二步
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://hadoop01:9000/a.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>(){
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception{
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String,Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
}
);
JavaPairRDD<String,Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
);
wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1+" : "+ wordCount._2 );
}
});
sc.close();
}
}生成jar包
點選File->Project Structure…->Artifacts,點選+號
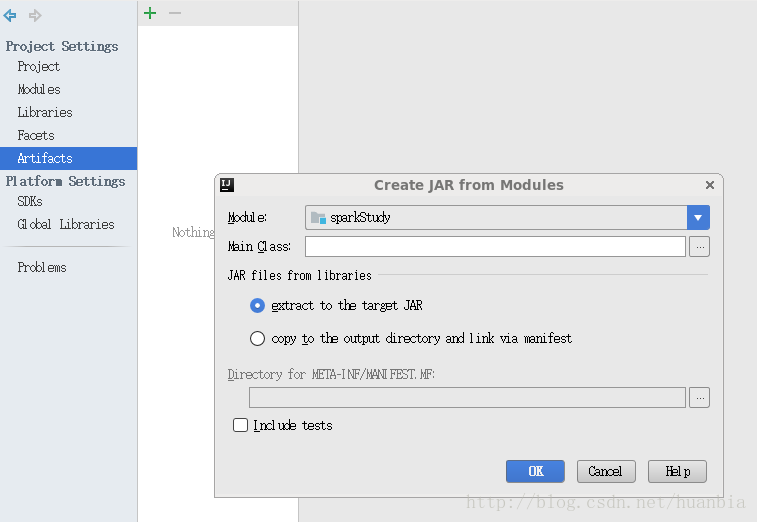
選擇Main Class
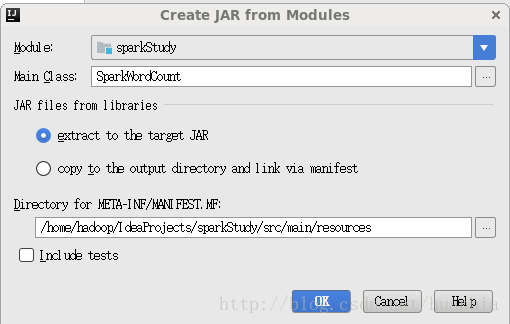
點選ok
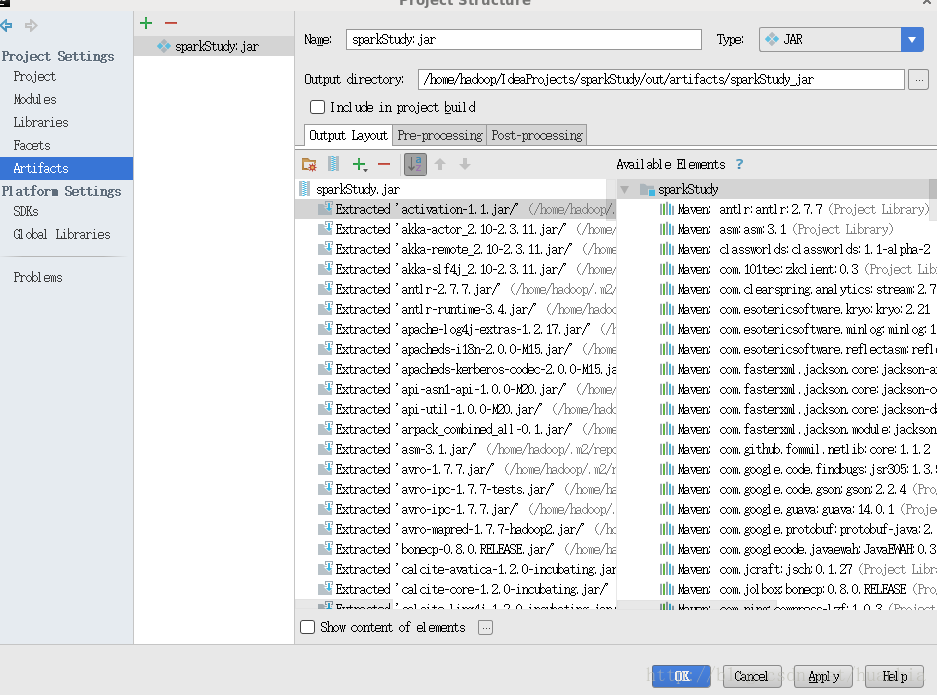
由於叢集中已包含spark相關jar包,將那些依賴jar包刪除

點選apply,ok。然後點選選單欄中的Build->Build Artifacts…->Build,將會在out目錄中生成相應的jar包
jar包上傳到叢集並執行
本文使用scp將jar包上傳到叢集,如果在windows下可使用filezilla或xftp軟體來上傳

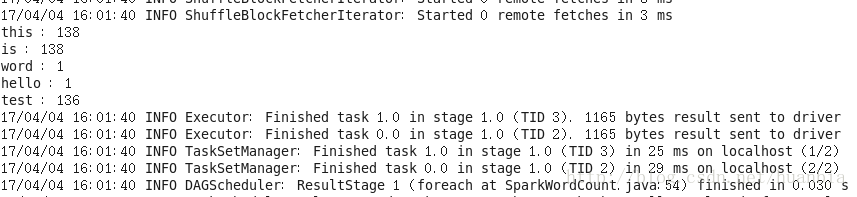
在叢集上輸入如下命令來執行:
/opt/moudles/spark-1.6.1/bin/spark-submit --class SparkWordCount sparkStudy.jar --master=spark://192.168.20.171:7077最終結果為:
相關推薦
Idea基於maven,java語言的spark環境搭建
環境介紹:IntelliJ IDEA開發軟體,hadoop01-hadoop04的叢集(如果不進行spark叢集測試可不安裝),其中spark安裝目錄為/opt/moudles/spark-1.6.1/ 準備工作 首先在叢集中的hdfs中新增a.
Java語言開發環境搭建
jdk 配置 ips 添加 -- eclipse 64bit ava 需要 一、.配置環境變量: 1.計算機屬性-->高級系統設置-->環境變量,在系統變量中新建JAVA_HOME變量,變量值即為JDK的安裝路徑,比如D:\JDK_9.0.1\jdk-9.0
基於maven來Spring MVC的環境搭建遇到“坑”
nbsp 操作 應該 sdn 8.0 環境 art href 環境搭建 1、註解配置路徑問題; 在web.xml中配置spring mvc 路徑時, 應該配置如下:classpath:classpath:spring-* 2、jdk版本和Spring MVC版本不一致問
java day1 (java 語言開發環境搭建)
命令提示符(cmd) 啟動: Win+R ,輸入 cmd 回車 切換碟
黑馬程式設計師——Java語言介紹+環境搭建+經典Hello World
-----------android培訓、java培訓、java學習型技術部落格、期待與您交流!------------ 一、Java語言的概述: 1、Java是SUN(Stanford University Network,斯坦福大學網路公司)在1995年
Appium移動自動化測試之—基於java的iOS環境搭建
res .sh 變更 order edev curl 軟件包 comm 簡單的 本文僅供參考,同時感謝幫助我搭建環境的同事 操作系統的名稱:Mac OS X操作系統的版本:10.12.6 接下來我們開始踏上搭建Appium+java+ios之路,本文只說個大概,畢竟本機已經
Java Web 學習筆記 第一章,java語言簡介
com 分布式 ron java瀏覽器 family javadoc 全球 intellij jvm 第一章 java語言簡介 一、什麽是java? Java 編程語言:簡單、完全面向對象、分布式、解釋性、健壯、安全與系統無關、可移植、高性能、多線程和動態的編程語言。
使用IDEA基於Maven搭建多模塊聚合工程(springmvc+spring+mybatis整合)
utf-8 組件 json處理 con mon 博客 quick 作者 處理工具 文章有不當之處,歡迎指正,如果喜歡微信閱讀,你也可以關註我的微信公眾號:好好學java,獲取優質學習資源。 終於有時間搞java了,今天使用IDEA基於maven搭建了多模塊聚合工程,經過了
eclipse導入基於maven的java項目後沒有Java標誌和沒有maven Dependencies有解決辦法
con ets 其他 facet spa entry png 基於 pre 沒有java標誌,不識別為Java項目,右鍵項目-->Properties-->Project Facets-->勾選Java 確定就可以了。 沒有maven Dep
idea部署Maven入門(一)——環境變數的配置和下載
介紹: 1 Maven是用來管理jar包的一種工具, 2 Maven主要是構建java專案和java web專案 &
java語言path環境變數的作用及配置方式
path環境變數配置目的:讓javac和java命令在任何路徑下都可以執行 第一種配置方式: 找到jdk安裝目錄下的bin目錄進行復制——點選計算機——選擇屬性——選擇高階——環境變數——path行處進行貼上(;結束) administrater使用者變數只針對administrater使用
基於Docker的Spark環境搭建理論部分
1.映象製作方案 我們要使用Docker來搭建hadoop,spark,hive及mysql叢集,首先使用Dockerfile製作映象,把相關的軟體拷貝到約定好的目錄下,把配置檔案在外面先配置好,再使用docker and / docker run,拷貝移動到hadoop,spark
判斷物件當中有沒有某一個屬性(AS,JS,Java語言比較)
1、AS 首先說說AS裡面如何判斷,AS現在很少用這個語言了,當時我們公司的專案當中還有,所以就拿出來一塊比較一下,程式碼如下: //利用Object屬性判斷 if("name" in obj){ Alert.show("當前物件包含屬性/方法 name!"); }els
IDEA 基於Maven的springboot+jsp搭建web專案完整流程
話不多說直接上乾貨(本文章適合新手快速上手)。 一丶新建maven spring boot 專案 next 下一步 選擇 web 建立完的目錄如下,新建一個webapp資料夾然後建一個pages包用來放jsp檔案 配置pox.xml <
徐鬆亮軟體應用教學-基於Visual Studio Code的C語言開發環境搭建
工欲善其事,必先利其器。後續,本博主要帶領大家,會做多種資料演算法和資料結構的實現,比如說記憶體管理,排序,三次樣條,二叉樹,九宮格,蟻群演算法。。。這些主要用C語言來實現。雖然其他語言有現成的庫,但因為本人主要擅長的是做嵌入式產品開發,目前大多數嵌入式晶片資源仍然有
基於Maven的Java構建---------Java打包
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XML
小白學JAVA,與你們感同身受,JAVA---day8:開發環境。魯迅的一句話:總之歲月漫長,然而值得等待。
魯迅的一句話:總之歲月漫長,然而值得等待。 /* 開發環境: Eclipse Myeclipse ==與equals的比較: 共同點:都可以做比較,返回值都是boolean。 區別: 1.=
從原始碼到機器程式碼,Java語言中發生了什麼?
在上一篇文章中,我們討論了無論程式碼是用什麼語言編寫的,它最終都毫無例外地執行在機器程式碼中。那麼Java語言中發生了什麼,從原始碼到機器程式碼?這就是我們今天要討論的。 如下圖所示,編譯器可以分為前端編譯器、JIT編譯器和AOT編譯器。我們一個接一個地談吧。 前端編譯器:原始碼到位元
推薦幾個IDEA插件,Java開發者擼碼利器。
ado 自定義顏色 app 好的 tlist 有意 sql文件 語句 http 這裏只是推薦一下好用的插件,具體的使用方法不一一詳細介紹。JRebel for IntelliJ 一款熱部署插件,只要不是修改了項目的配置文件,用它都可以實現熱部署。收費的,破解比較麻煩。不過功
JDK中的,Java的執行環境元件——JRE
JRE:Java Runtime Evironment,只要有這個元件就可以執行java應用程式。 JRE有兩種: