
推薦系統實踐學習筆記(一)
寫在前面:這幾天學習了一下《推薦系統實踐》這本書,出於兼顧學生讀者和工程師讀者的考慮,作者在理論上講得不算太深,但是非常系統、全面。由於看得比較快,其中的方法沒有來得及一一實現,打算寫幾篇部落格記錄一下,便於日後有空時翻看實踐。
個性化推薦系統的應用
相信個性化推薦系統對每一個經常使用網際網路的人來說都不陌生,購物時有個性化商品推薦、聽歌/看電影時有猜你喜歡的歌曲/電影推薦、逛論壇時有你想看的個性化熱帖推薦……隨著資訊科技的飛速發展,人們逐漸走進了資訊過載的時代,從大量的資訊中找出自己感興趣的東西成了一件困難的事情。一個好的推薦系統,可以在使用者面前展示他感興趣的東西,為商家推廣產品,為平臺(網站或手機應用)帶來流量……可以說是實現了三方的共贏。
那麼問題來了,推薦系統向用戶推薦物品的依據有哪些呢?其中哪一種又是最優的?如何評價一個推薦系統是好是壞呢?
推薦系統評測
實驗方法
在推薦系統中,主要有三種評測推薦效果的實驗方法:離線實驗,使用者調查和線上實驗。
離線實驗
離線實驗通過日誌系統獲得使用者行為資料,生成資料集,將資料集劃分成訓練集和測試集,在訓練集上訓練模型,測試集上進行預測,最後對預測結果進行評測。
離線實驗的優點是,不需要使用者的實時參與,可以快速地進行大量不同演算法的測試;它的主要缺點是無法獲得點選率、轉化率等很多商業上關注的指標,離線實驗的指標和商業指標還存在著差距,比如高預測準確率不等於高使用者滿意度。
使用者調查
使用者調查是推薦系統評測的一個重要工具,很多離線時沒有辦法評測的與使用者主觀感受有關的指標都可以通過使用者調查獲得。選擇測試使用者時,需要儘量保持測試使用者的分佈與真實使用者的分佈相同,同時要儘量保證是雙盲實驗(實驗人員和使用者事先不知道測試的目標),避免實驗結果受主觀成分的影響。
使用者調查的優點是可以獲得體現使用者主管感受的指標,彌補離線實驗的不足,同時相對線上實驗風險較低;它的主要缺點是招募測試使用者代價大,因此會使測試結果的統計意義不足,此外,在很多時候設計雙盲實驗非常困難,而且使用者在測試環境下的行為和真實環境下可能有所不同。
線上實驗
在完成離線實驗和必要的使用者調查後,可以將推薦系統上線做AB測試,AB測試是一種常用的線上評測演算法的實驗方法,它通過一定的規則將使用者隨機分成幾組,並對不同組的使用者採用不同的演算法,然後通過統計不同組使用者的各種不同的評測指標比較不同演算法。
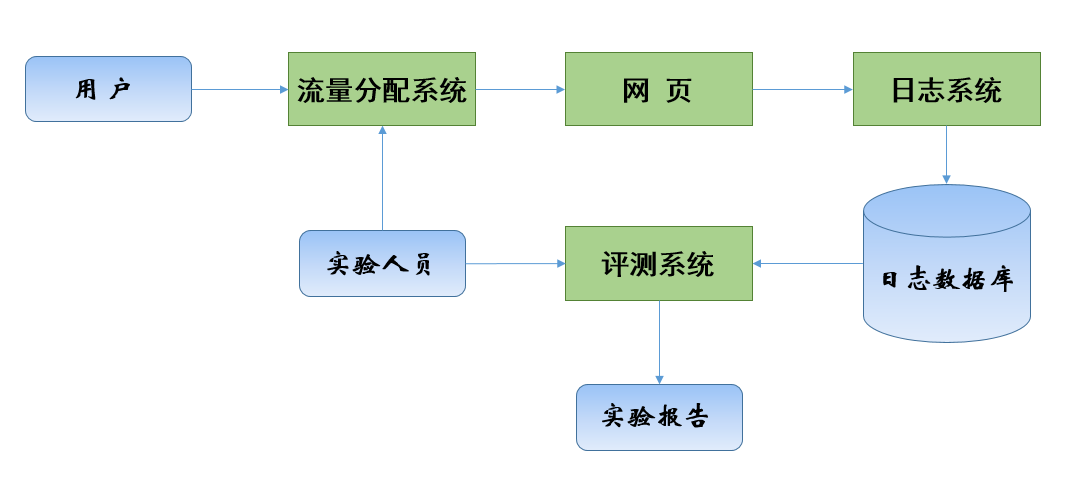
上圖是一個簡單的AB評測系統:使用者進入網站後,流量分配系統(由後臺實驗人員配置)決定使用者是否需要被進行AB測試,然後使用者瀏覽網頁,瀏覽網頁時的行為都會被通過日誌系統發回後臺資料庫,實驗人員在後臺統計日誌資料庫中的資料,通過評測系統生成不同分組使用者的實驗報告,並比較和評測實驗結果。
總結
一般來說,一個新的推薦演算法最終上線前,需要完成3個實驗:
首先,需要通過離線實驗證明它在很多離線指標上優於現有的演算法;然後,需要通過使用者調查確定它的使用者滿意度不低於現有演算法;最後通過線上測試確定它在我們關心的指標上優於現有的演算法。
評測指標
使用者滿意度
使用者滿意度是評測推薦系統的最重要指標,它可以通過使用者調查獲得,設計問卷時要注意考慮到使用者在各方面的感受。對於線上系統,使用者滿意度主要由對使用者行為的統計得到:設定使用者反饋按鈕,或者用點選率、使用者停留時間和轉化率等指標度量使用者的滿意度。
預測準確度
預測準確度度量了一個推薦系統預測使用者行為的能力,是最重要的推薦系統離線評測指標。對於不同研究方向的離線推薦演算法,預測準確度的指標也不相同,主要有兩種:
1、評分預測
評分預測的預測準確度一般通過均方根誤差(RMSE)和平均絕對誤差(MAE)計算,對於測試集中的一個使用者u和物品i,令rui是使用者u對物品i的實際評分,而r’ui是推薦演算法給出的預測,那麼RMSE和MAE的定義分別為:
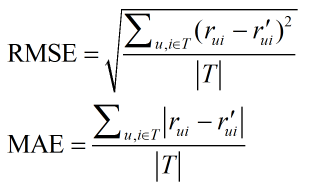
python程式碼如下:
def RMSE(records):
return math.sqrt(sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records])/float(len(records)))
def MAE(records):
return sum([abs(rui-pui) for u,i,rui,pui in records])/float(len(records))2、個性化(TopN)推薦列表
TopN推薦列表的預測準確率一般通過準確率和召回率度量:
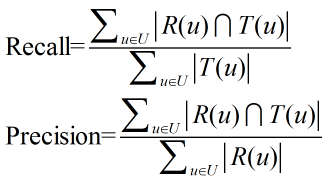
其中R(u)是推薦列表,T(u)是使用者在測試集上的行為列表。
通常來說,TopN推薦比評分預測更符合實際應用。
覆蓋率
覆蓋率描述一個推薦系統對物品長尾的發掘能力。覆蓋率有不同的定義方法,最簡單的定義為推薦系統能夠推薦出來的物品佔總物品集合的比例:
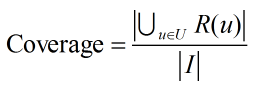
其中R(u)為使用者u的推薦列表。
個性化的推薦系統應當不僅僅能夠向用戶推薦那些熱門的物品,同時可以發掘適合使用者的非熱門物品,一個好的推薦系統不僅需要有比較高的使用者滿意度,也要有較高的覆蓋率。
但是上面的定義過於粗略,為了更細緻地描述推薦系統發掘長尾的能力,需要統計推薦列表中不同物品出現次數的分佈。如果所有物品都出現在推薦列表中,且出現次數相差不大,那麼推薦系統發現長尾的能力就很好。資訊熵和Gini係數也可以用來定義覆蓋率:
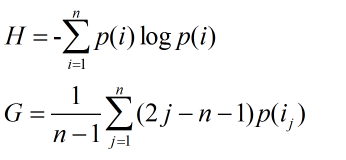
其中p(i)是物品i的流行度除以所有物品流行度之和,ij是按照物品i流行度p()從小到大排序的物品列表中第j個物品。
多樣性
多樣性描述了推薦列表中物品兩兩之間的不相似性,假設s(i,j)定義了物品i和j之間的相似度,那麼使用者u的推薦列表R(u)的多樣性定義如下:
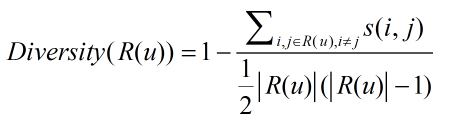
而推薦系統的整體多樣性可以定義為所有使用者推薦列表多樣性的平均值。
其它評測指標還有新穎性、驚喜度、信任度、實時性、健壯性等,在這裡就不一一列舉。
使用者行為資料
使用者行為資料在網站上最簡單的存在形式就是日誌,日誌中記錄了使用者的各種行為,比如網頁瀏覽、點選、購買、評論、評分等等。
使用者行為在個性化推薦系統中一般分為顯性反饋行為和隱性反饋行為。顯性反饋行為包括使用者明確表示對物品的喜好的行為,比如給物品評分,而隱性反饋行為是指那些不能明確反應使用者喜好的行為,比如頁面瀏覽行為。隱性反饋資料比顯性反饋不明確,但其資料量更龐大。
此外,使用者活躍度和物品流行度的分佈都服從長尾分佈,隨著使用者活躍度(物品流行度)的下降,使用者數量(物品數量)逐漸下降,但不會迅速墜落到零,而是極其緩慢地貼近於橫軸,粗看上去幾乎與橫軸平行延伸。
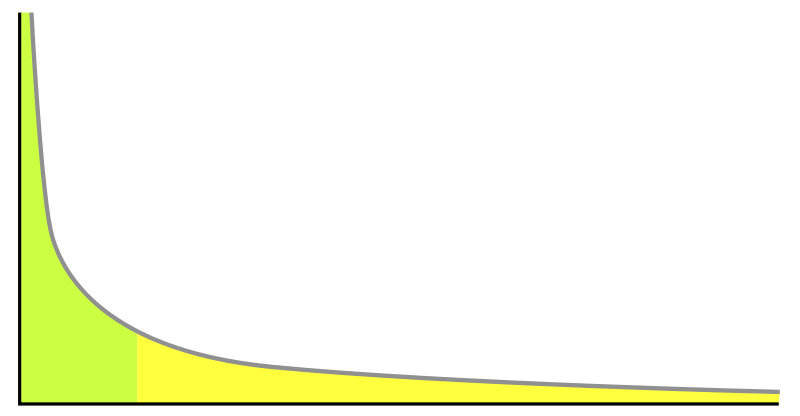
僅僅基於使用者行為資料設計的推薦演算法一般稱為協同過濾演算法,比如基於領域的演算法、隱語義模型、基於圖的演算法等等,下面對這幾種方法分別進行介紹。
基於鄰域的演算法
基於鄰域的演算法是推薦系統中最基本的演算法,分為兩大類,一類是基於使用者的協同過濾演算法,一類是基於內容的協同過濾演算法。
基於使用者的協同過濾演算法(UserCF)
計算使用者相似度
基於使用者的協同過濾演算法通過找到和目標使用者興趣相似的使用者集合,找到這個集合中的使用者喜歡的,且目標使用者沒有聽說過的物品推薦給目標使用者。
通過餘弦相似度計算兩個使用者的興趣相似度:
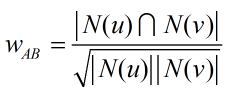
如果對兩兩使用者都利用餘弦相似度計算,在使用者數很大時消耗的時間將會非常多,因此可以首先篩選出興趣物品集合交集不為零的使用者對,然後再對這些情況除以分母計算興趣相似度。
利用UserCF篩選使用者感興趣的物品
得到使用者之間的興趣相似度後,UserCF演算法會給使用者推薦和他興趣最相似的K個使用者喜歡的物品,下面的公式度量了UserCF中使用者u對物品i的感興趣程度:
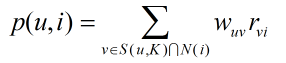
其中S(u,k)包含和使用者u興趣最接近的K個使用者,wuv是使用者u和使用者v的興趣相似度,N(i)是對物品i有過行為的使用者合集,rvi代表使用者v對物品i的興趣,使用單一行為的隱反饋資料時,所有的rvi=1。K值需要通過離線實驗,選擇在預測資料集上預測效果最好時所對應的值。
相似度計算改進
對一件冷門物品有過相同行為比對一件熱門物品有過相同行為更能說明兩個使用者興趣相似,比如,同時購買《資料探勘導論》的使用者顯然比同時購買《新華字典》的使用者喜好更相近。因此,需要對相似度公式進行如下的改進:
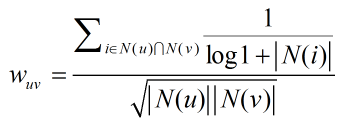
該公式通過1/log1+|N(i)|懲罰了使用者u和使用者v共同興趣列表中的熱門物品i,實驗表明,改進的UserCF演算法的各預測指標都有所提升。
基於物品的協同過濾演算法(ItemCF)
計算物品相似度
基於物品的協同過濾演算法是向用戶推薦與他們過去喜歡過的物品相似的物品。那麼首先需要計算物品之間的相似度,可以由下面的公式計算:
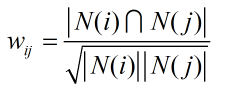
|N(i)|和|N(j)|分別是喜歡物品i和物品j的使用者數,分母之所以這樣設計,是為了減輕熱門物品會和很多物品相似的可能性。
和UserCF演算法類似,ItemCF演算法在計算物品相似度時為了避免兩兩物品之間都需要進行計算,首先建立使用者-物品倒排表,對於每個使用者,將他物品列表中的物品兩兩在共現矩陣中加1,最後將矩陣歸一化就可以得到物品之間的餘弦相似度。
利用ItemCF篩選使用者感興趣的物品
得到物品之間的相似度之後,ItemCF通過以下公式計算使用者u對一個物品j的興趣:
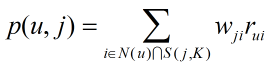
其中S(j,K)包含和物品i最接近的K個物品,wji是物品i和物品j的相似度,N(u)是使用者喜歡的物品合集,rui代表使用者u對物品i的興趣,使用單一行為的隱反饋資料時,所有的rui=1。
相似度計算改進
試想這樣一種情況:如果有一個使用者從網上購買了數十萬本書準備開書店,這數十萬本可能覆蓋眾多領域的書兩兩之間就產生了相似性,然而使用者購買這些書並非出於自己興趣,因此John S.Breese提出應當懲罰活躍使用者對物品相似度的貢獻,將計算公式改進為:
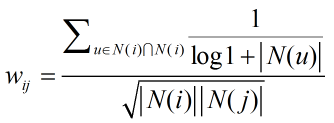
同時,對於某些過於活躍的使用者,為了避免相似度矩陣過於稠密,通常直接忽略他們的興趣列表,不納入相似度計算的資料集。
物品相似度的歸一化
如果將ItemCF的相似度矩陣按最大值歸一化,可以提高推薦的準確率、覆蓋率和多樣性。原因是,物品往往歸屬於不同的類,類物品之間的相似度往往比不同類物品之間的相似度要高,類物品之間的相似度都變成1,推薦時的多樣性和覆蓋率就更好了。歸一化公式如下:
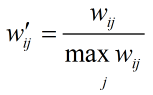
UserCF和ItemCF的綜合比較
- UserCF適用於使用者較少的場合,因為使用者很多時計算相似度矩陣的代價會很大,需要計算物品相似度矩陣的ItemCF則適用於物品數明顯小於使用者數的場合。
- UserCF的推薦更社會化,反映了使用者所在的小型興趣群體中物品的熱門程度,ItemCF的推薦更加個性化,反映了使用者自己的興趣傳承。
- 當用戶有新行為時,UserCF演算法中推薦結果不一定立即變化,而ItemCF中一定會導致推薦結果的實時變化。
- UserCF適用於新聞推薦,主要是由於在新聞網站使用者的興趣比較粗粒度且偏向於熱門,同時,新聞的時效性很強,維護物品相似度矩陣代價太大。
- ItemCF適用於圖書、電影、音樂和電子商務中的推薦,因為在這些網站中使用者的興趣比較固定,個性化推薦的任務是幫助使用者發現和他研究鄰域相關的物品。
隱語義模型(LFM)
基於興趣分類方法的核心思想是通過隱含特徵聯絡使用者興趣和物品,判斷使用者對哪些類的物品感興趣,再將屬於這些類的物品推薦給使用者。那麼,如何給物品分類,分類的粒度如何確定?如何確定使用者對哪些類的物品感興趣,以及感興趣的程度?又如何確定物品在一個類中的權重呢?
隱語義分析技術基於使用者行為統計進行自動聚類,較好地解決了以上幾個問題。
LFM是隱語義分析技術中的一種模型,通過以下公式計算使用者u對物品i的興趣:
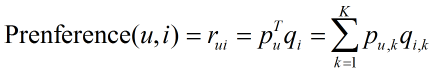
其中pu,k度量了使用者u的興趣和第k個隱類的關係,qi,k度量了第k個隱類和物品i之間的關係。計算這兩個引數,需要一個訓練集,對於每個使用者u,訓練集裡都包含了使用者u喜歡和不感興趣的物品,通過學習這個資料集,就可以獲得模型引數。
訓練集取樣
在隱性反饋資料集中,只有正樣本,沒有負樣本。那麼就需要在使用者沒有行為的物品中進行負樣本的採用,經過實驗,發現對負樣本的取樣應該遵循以下原則:對於每個使用者,要保證正負樣本的平衡,對每個使用者取樣負樣本時,選取熱門但使用者沒有行為的物品。
取樣完成後可以得到一個使用者-物品集K={(u,i)},如果(u,i)是正樣本,則rui=1,否則rui=0。
優化損失函式
對於取樣完成的訓練集,需要優化如下損失函式來找到最合適的引數p和q:
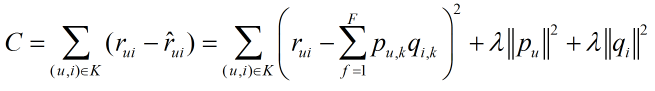
最小化損失函式採用的是隨機梯度下降法。
基於圖的模型
基於圖的模型首先需要將使用者行為表示成二分圖模型,令G(V,E)表示使用者物品二分圖,其中V由使用者頂點合集VU和物品頂點合集VI組成,E為連線使用者節點和物品節點的邊的集合,使用者節點和物品節點相連說明該使用者對相連的物品產生過行為。
度量頂點之間相關性的方法有很多,主要有:兩個頂點之間的路徑數,兩個頂點之間路徑的長度,兩個頂點之間的路徑經過的頂點。
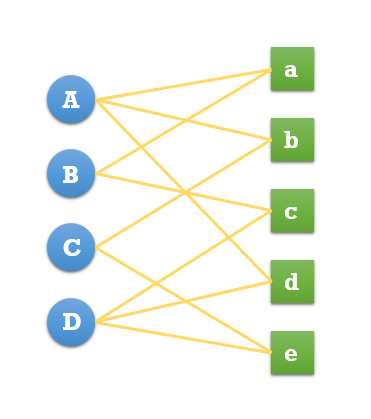
基於隨機遊走的PersonalRank演算法
瞭解了二分圖模型的基本概念,下面介紹一種計算圖中頂點之間相關性的方法。
假設要給使用者u進行個性化推薦,可以從使用者u對應的節點vu開始在使用者物品二分圖上進行隨機遊走,遊走到任何一個節點時,首先按照概率決定是繼續遊走還是停止這次遊走並從vu節點重新開始遊走。如果決定繼續遊走,那麼就從當前節點指向的節點中按照均勻分佈隨機選擇一個節點作為遊走下次經過的節點。這樣,經過很多次隨機遊走後,每個物品節點被訪問到的概率會收斂到一個數。最終的推薦列表中物品的權重就是物品節點的訪問概率。
這種方法可以表示成如下公式:
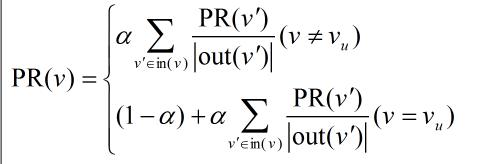
PersonalRank演算法可以通過隨機遊走進行比較好的理論解釋,但該演算法在時間複雜度上有明顯的缺點,可以通過將PR轉化成矩陣的方法進行改進。
總結
首先感嘆一下,寫完這篇部落格真心不輕鬆啊,這還僅僅是《推薦系統實踐》前兩章的內容。不過,寫部落格的過程等於是又把書看了一遍,的確起到很好的鞏固作用。接下來,我會用幾個資料集將這篇博文中提到的推薦演算法實現、測試一下(加深對公式的理解),後續也會繼續更新後幾章的內容,對機器學習基礎演算法的學習同樣不能落下……不說了看書去啦>_<
相關推薦
推薦系統實踐學習筆記(一)
寫在前面:這幾天學習了一下《推薦系統實踐》這本書,出於兼顧學生讀者和工程師讀者的考慮,作者在理論上講得不算太深,但是非常系統、全面。由於看得比較快,其中的方法沒有來得及一一實現,打算寫幾篇部落格記錄一下,便於日後有空時翻看實踐。 個性化推薦系統的應用 相
推薦系統實踐讀書筆記(一):好的推薦系統
設計一個推薦系統之前,一定要了解什麼樣的推薦系統才是好的推薦系統至關重要。那麼一個優秀的推薦系統具有哪些特徵呢?(量化或者概念性的特徵) 通過以下三個步驟回答一個優秀的推薦系統是什麼樣的 1)什麼是推薦系統、推薦系統的主要任務、推薦系統和分類目錄以及搜尋引擎的區別 2)不同領域分門別類的介紹
《深入理解計算機系統》學習筆記(一)
一、資訊就是位 + 上下文 作者使用的標題是:資訊就是位 + 上下文,那麼問題來了:什麼是位?什麼是上下文? 計算機系統是由硬體和系統軟體組成的,它們共同工作來執行應用程式。所有計算機系統都有相似的硬體和軟體元件,它們執行著相似的功能。 從某種意義上來說,本書的目的就是要幫助你
專案實踐學習筆記(一)
讀library的標頭檔案: process corner; operate condition; timing information; power information; pad attributes; wire loads; cell(包括combinat
1.13《推薦系統實踐》筆記(上)
兩天一口氣看完《推薦系統實踐》,非常的爽,收穫非常的大。作者不僅是技術性介紹,更是結合自己的商業理解。加上作者長時間的競賽工作第一手經驗,本書價值非常大!!! 《推薦系統實踐》筆記 作者:項亮 出版社: 人民郵電出版社 圖靈原創 筆記作者:jinwan
《深入理解計算機系統》| 學習筆記(一)
一、資訊就是位 + 上下文 作者使用的標題是:資訊就是位 + 上下文,那麼問題來了:什麼是位?什麼是上下文? 計算機系統是由硬體和系統軟體組成的,它們共同工作來執行應用程式。所有計算機系統都有相似的硬體和軟體元件,它們執行著相似的功能。 從某種意義上來說,本書的目的
基於HTK的連續語音識別系統搭建學習筆記(一)
該系統能夠識別連續說出的數字串和若干組姓名。建模是針對子詞(sub-word, eg. 音素),具有一定的可擴充性。當加入一個新名字時,只需修改發音字典和任務語法即可。模型為連續混合高斯輸出,運用語音決策樹聚類形成的繫結狀態式三音素。 1.資料準備 需要錄製訓練資料和測試
系統分析與設計學習筆記(一)
學習 掌握 應該 溝通 基本 最終 表示 對象 毫無 為什麽要學習這門課程? “擁有一把錘子未必能成為建築師”。 這門課程學習的是面向對象分析和設計的核心技能的重要工具。對於使用面向對象技術和語言來,創建設計良好、健壯且可維護的軟件來說,這門課程所
分布式系統學習筆記(一)
常見 算法 特征 最大 普通 部分 AR 復制 完美 1.分布式架構的發展歷史 1.1 1946 年情人節(2.14) , 世界上第一臺電子數字計算機誕生在美國賓夕法尼亞大學大學,它的名字是:ENIAC; 這臺計算機占地 170 平米、重達 30 噸,每秒可進行 5
Linux視訊學習筆記(一)--系統分割槽
宣告:本系列文章是博主根據 “兄弟連新版Linux視訊教程”做的筆記和視訊截圖,只為學習和教學使用,不適用任何商業用途。 PS:如果對Linux感興趣,建議去看《細說Linux》,沈超老師和李明老師的教學風格我很喜歡:) 視訊2.1-VMWare虛擬機器安裝與使用
linux學習筆記(一)——使用easyBCD或easyUEFI引導從硬碟安裝Ubuntu系統
Table of Contents 一. 使用easyBCD引導 二. 使用easyUEFI新增引導安裝系統 windows系統安裝ubuntu會出現引導問題,windows系統不希望有其他系統和windows系統共存。所以我們得自己作一個引導。接下來主要介紹兩種引導,easyB
在Windows系統上安裝Jenkins ---- Jenkins自動化部署學習筆記(一)
之前一直想著學習一下Jenkins自動化部署,最近剛好有點時間,就利用這點時間來學習一下Jenkins自動化部署,做個筆記,既可以鞏固自己的學習,也可以幫助更多的人瞭解Jenkins自動化部署。 先從簡單的開始,我們先用Windows系統來安裝Jenkins,當然以後肯定會在
【TensorFlow學習筆記(一)】利用Anaconda安裝TensorFlow(windows系統)
1.安裝Anaconda Anaconda官網 由於檔案很大,所以下載速度會很慢,可以採用映象下載 下載完之後,如果你的電腦系統時win8+,一定要以管理員身份執行安裝包。 有一個地方需要注意下: 第一個勾是是否把Anaconda加入環境變數,這涉及到
作業系統學習筆記(一) 分割槽表、系統引導與檔案系統
作為初學者,可能很難分清分割槽表和檔案系統之間的關係,畢竟在很多時候,磁碟分割槽操作都籠統的稱為“分割槽”,而檔案系統則被簡稱做“格式化”,當然筆者也算,不過,對於作業系統有興趣的人,分割槽表和檔案系統註定是個繞不過去的坑。在作業系統的幾大重要知識點(程序管理,記憶體管理等)
機器學習筆記(一)——基於單層決策樹的AdaBoost演算法實踐
基於單層決策樹的AdaBoost演算法實踐 最近一直在學習周志華老師的西瓜書,也就是《機器學習》,在第八章整合學習中學習了一個整合學習演算法,即AdaBoost演算法。AdaBoost是一種迭代演算法,其核心思想
Linux系統SPI驅動學習筆記(一)
SPI是"Serial Peripheral Interface" 的縮寫,是一種四線制的同步序列通訊介面,用來連線微控制器、感測器、儲存裝置,SPI裝置分為主裝置和從裝置兩種,用於通訊和控制的四根線分別是: CS 片選訊號SCK 時鐘訊號MISO 主裝置的
深入理解計算機系統學習筆記(一)
程式的編譯過程 為了說明程式的編譯過程,我們用經典的hello world程式作為例子 #include <stdio.h> int main(int argc, char const *argv[]) { printf("hell
[計算機基礎]計算機系統學習筆記(一)
1,ASCII嗎 ASCII碼的含義就是用一個唯一的位元組大小的整數值來表示每個字元。 ASCII碼對照表 例如:文字檔案 sss qhd 以上文字檔案對應的二進位制檔案是: 00000000h: 73 73 73 0D 0A 71 64 63
作業系統學習筆記(一)--批處理、多道程式系統、分時作業系統、實時作業系統和作業系統操作
最近開始學習作業系統原理這門課程,特將學習筆記整理成技術部落格的形式發表,希望能給大家的作業系統學習帶來幫助。同時盼望大家能對文章評論,大家一起多多交流,共同進步! 本篇文章大致內容為: 批處理系統(Batch OS) 多道程式系統(Multiprogra
ROS學習筆記(一):ROS 系統的概述
ROS (Robot Operating System, 機器人作業系統) 提供一系列程式庫和工具以幫助軟體開發者建立機器人應用軟體。它提供了硬體抽象、裝置驅動、函式庫、視覺化工具、訊息傳遞和軟體包管理等諸多功能。 ROS的前身是斯坦福人工智慧實驗室為了支援斯