
linux驅動開發總結(一)
基礎性總結
1, linux驅動一般分為3大類:
* 字元裝置
* 塊裝置
* 網路裝置
2, 開發環境構建:
* 交叉工具鏈構建
* NFS和tftp伺服器安裝
3, 驅動開發中設計到的硬體:
* 數位電路知識
* ARM硬體知識
* 熟練使用萬用表和示波器
* 看懂晶片手冊和原理圖
4, linux核心原始碼目錄結構:
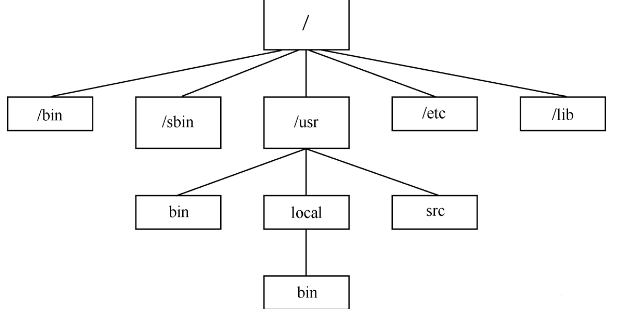
* arch/: arch子目錄包括了所有和體系結構相關的核心程式碼。它的每一個子目錄都代表一種支援的體系結構,例如i386就是關於intel cpu及與之相相容體系結構的子目錄。
* block/: 部分塊裝置驅動程式;
* crypto: 常用加密和雜湊演算法(如AES、SHA等),還有一些壓縮和CRC校驗演算法;
* documentation/: 文件目錄,沒有核心程式碼,只是一套有用的文件;
* drivers/: 放置系統所有的裝置驅動程式;每種驅動程式又各佔用一個子目錄:如,/block 下為塊裝置驅動程式,比如ide(ide.c)。如果你希望檢視所有可能包含檔案系統的裝置是如何初始化的,你可以看 drivers/block/genhd.c中的device_setup()。
* fs/: 所有的檔案系統程式碼和各種型別的檔案操作程式碼,它的每一個子目錄支援一個檔案系統, 例如fat和ext2;
* include/: include子目錄包括編譯核心所需要的大部分標頭檔案。與平臺無關的標頭檔案在 include/linux子目錄下,與 intel cpu相關的標頭檔案在include/asm-i386子目錄下,而include/scsi目錄則是有關scsi裝置的標頭檔案目錄;
* init/: 這個目錄包含核心的初始化程式碼(注:不是系統的引導程式碼),包含兩個檔案main.c和Version.c,這是研究核心如何工作的好的起點之一;
* ipc/: 這個目錄包含核心的程序間通訊的程式碼;
* kernel/: 主要的核心程式碼,此目錄下的檔案實現了大多數linux系統的核心函式,其中最重要的檔案當屬sched.c;同樣,和體系結構相關的程式碼在arch/i386/kernel下;
* lib/: 放置核心的庫程式碼;
* mm/:這個目錄包括所有獨立於 cpu 體系結構的記憶體管理程式碼,如頁式儲存管理記憶體的分配和釋放等;而和體系結構相關的記憶體管理程式碼則位於arch/i386/mm/下;
* net/: 核心與網路相關的程式碼;
* scripts/: 描述檔案,指令碼,用於對核心的配置;
* security: 主要是一個SELinux的模組;
* sound: 常用音訊裝置的驅動程式等;
* usr: 實現了用於打包和壓縮的cpio;
5, 核心的五個子系統:
* 程序除錯(SCHED)
* 記憶體管理(MM)
* 虛擬檔案系統(VFS)
* 網路介面(NET)
* 程序間通訊(IPC)
6, linux核心的編譯:
* 配置核心:make menuconfig,使用後會生成一個.confiig配置檔案,記錄哪些部分被編譯入核心,哪些部分被編譯成核心模組。
* 編譯核心和模組的方法:make zImage
Make modules
* 執行完上述命令後,在arch/arm/boot/目錄下得到壓縮的核心映像zImage,在核心各對應目錄得到選中的核心模組。
7, 在linux核心中增加程式
(直接編譯進核心)要完成以下3項工作:
* 將編寫的原始碼拷入linux核心原始碼相應目錄
* 在目錄的Kconifg檔案中增加關於新原始碼對應專案的編譯配置選項
* 在目錄的Makefile檔案中增加對新原始碼的編譯條目
8, linux下C程式設計的特點:
核心下的Documentation/CodingStyle描述了linux核心對編碼風格的要求。具體要求不一一列舉,以下是要注意的:
* 程式碼中空格的應用
* 當前函式名:
GNU C預定義了兩個標誌符儲存當前函式的名字,__FUNCTION__儲存函式在原始碼中的名字,__PRETTY_FUNCTION__儲存帶語言特色的名字。
由於C99已經支援__func__巨集,在linux程式設計中應該不要使用__FUNCTION__,應該使用__func__。
*內建函式:不屬於庫函式的其他內建函式的命名通常以__builtin開始。
9,核心模組
核心模組主要由如下幾部分組成:
(1) 模組載入函式
(2) 模組解除安裝函式
(3) 模組許可證宣告(常用的有Dual BSD/GPL,GPL,等)
(4) 模組引數(可選)它指的是模組被載入的時候可以傳遞給它的值,它本身對應模組內部的全域性變數。例如P88頁中講到的一個帶模組引數的例子:
insmod book.ko book_name=”GOOD BOOK” num=5000
(5) 模組匯出符號(可選)匯出的符號可以被其他模組使用,在使用之前只需宣告一下。
(6) 模組作者等宣告資訊(可選)
以下是一個典型的核心模組:
/*
* A kernel module: book
* This example is to introduce module params
*
* The initial developer of the original code is Baohua Song
* <[email protected]>. All Rights Reserved.
*/
#include <linux/init.h>
#include <linux/module.h>
static char *book_name = “dissecting Linux Device Driver”;
static int num = 4000;
static int book_init(void)
{
printk(KERN_INFO “ book name:%s\n”,book_name);
printk(KERN_INFO “ book num:%d\n”,num);
return 0;
}
static void book_exit(void)
{
printk(KERN_INFO “ Book module exit\n “);
}
module_init(book_init);
module_exit(book_exit);
module_param(num, int, S_IRUGO);
module_param(book_name, charp, S_IRUGO);
MODULE_AUTHOR(“Song Baohua, [email protected]”);
MODULE_LICENSE(“Dual BSD/GPL”);
MODULE_DESCRIPTION(“A simple Module for testing module params”);
MODULE_VERSION(“V1.0”);注意:標有__init的函式在連結的時候都放在.init.text段,在.initcall.init中還儲存了一份函式指標,初始化的時候核心會通過這些函式指標呼叫__init函式,在初始化完成後釋放init區段。
模組編譯常用模版:
KVERS = $(shell uname -r)
# Kernel modules
obj-m += book.o
# Specify flags for the module compilation.
#EXTRA_CFLAGS=-g -O0
build: kernel_modules
kernel_modules:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) modules
clean:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean注意要指明核心版本,並且核心版本要匹配——編譯模組使用的核心版本要和模組欲載入到的那個核心版本要一致。
模組中經常使用的命令:
insmod,lsmod,rmmod
系統呼叫:
int open(const char *pathname,int flags,mode_t mode);
flag表示檔案開啟標誌,如:O_RDONLY
mode表示檔案訪問許可權,如:S_IRUSR(使用者可讀),S_IRWXG(組可以讀、寫、執行)
10,linux檔案系統與裝置驅動的關係
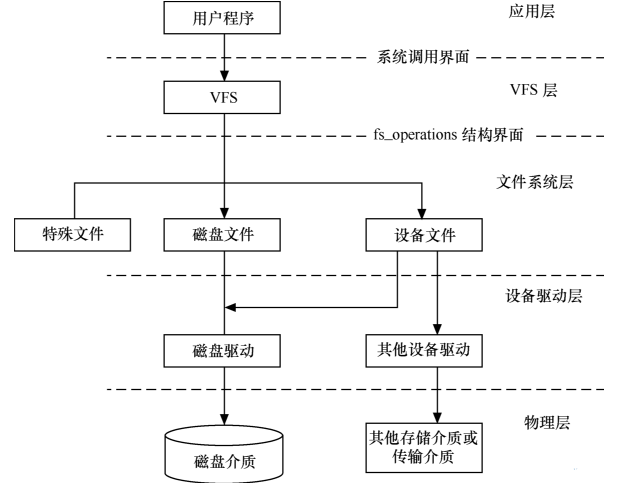
應用程式和VFS之間的介面是系統呼叫,而VFS與磁碟檔案系統以及普通裝置之間的介面是file_operation結構體成員函式。
兩個重要的函式:
(1)struct file結構體定義在/linux/include/linux/fs.h(Linux 2.6.11核心)中定義。檔案結構體代表一個開啟的檔案,系統中每個開啟的檔案在核心空間都有一個關聯的struct file。它由核心在開啟檔案時建立,並傳遞給在檔案上進行操作的任何函式。在檔案的所有例項都關閉後,核心釋放這個資料結構。在核心建立和驅動原始碼中,struct file的指標通常被命名為file或filp。
在驅動開發中,檔案讀/寫模式mode、標誌f_flags都是裝置驅動關心的內容,而私有資料指標private_data在驅動中被廣泛使用,大多被指向裝置驅動自定義的用於描述裝置的結構體。驅動程式中常用如下類似的程式碼來檢測使用者開啟檔案的讀寫方式:
if (file->f_mode & FMODE_WRITE) //使用者要求可寫
{
}
if (file->f_mode & FMODE_READ) //使用者要求可讀
{
}下面的程式碼可用於判斷以阻塞還是非阻塞方式開啟裝置檔案:
if (file->f_flags & O_NONBLOCK) //非阻塞
pr_debug("open:non-blocking\n");
else //阻塞
pr_debug("open:blocking\n");(2)struct inode結構體定義在linux/fs.h中
11,devfs、sysfs、udev三者的關係:
(1)devfs
linux下有專門的檔案系統用來對裝置進行管理,devfs和sysfs就是其中兩種。在2.4核心4一直使用的是devfs,devfs掛載於/dev目錄下,提供了一種類似於檔案的方法來管理位於/dev目錄下的所有裝置,我們知道/dev目錄下的每一個檔案都對應的是一個裝置,至於當前該裝置存在與否先且不論,而且這些特殊檔案是位於根檔案系統上的,在製作檔案系統的時候我們就已經建立了這些裝置檔案,因此通過操作這些特殊檔案,可以實現與核心進行互動。但是devfs檔案系統有一些缺點,例如:不確定的裝置對映,有時一個裝置對映的裝置檔案可能不同,例如我的U盤可能對應sda有可能對應sdb;沒有足夠的主/次裝置號,當裝置過多的時候,顯然這會成為一個問題;/dev目錄下檔案太多而且不能表示當前系統上的實際裝置;命名不夠靈活,不能任意指定等等。
(2)sysfs
正因為上述這些問題的存在,在linux2.6核心以後,引入了一個新的檔案系統sysfs,它掛載於/sys目錄下,跟devfs一樣它也是一個虛擬檔案系統,也是用來對系統的裝置進行管理的,它把實際連線到系統上的裝置和匯流排組織成一個分級的檔案,使用者空間的程式同樣可以利用這些資訊以實現和核心的互動,該檔案系統是當前系統上實際裝置樹的一個直觀反應,它是通過kobject子系統來建立這個資訊的,當一個kobject被建立的時候,對應的檔案和目錄也就被建立了,位於/sys下的相關目錄下,既然每個裝置在sysfs中都有唯一對應的目錄,那麼也就可以被使用者空間讀寫了。使用者空間的工具udev就是利用了sysfs提供的資訊來實現所有devfs的功能的,但不同的是udev執行在使用者空間中,而devfs卻執行在核心空間,而且udev不存在devfs那些先天的缺陷。
(3)udev
udev是一種工具,它能夠根據系統中的硬體裝置的狀況動態更新裝置檔案,包括裝置檔案的建立,刪除等。裝置檔案通常放在/dev目錄下,使用udev後,在/dev下面只包含系統中真實存在的裝置。它於硬體平臺無關的,位於使用者空間,需要核心sysfs和tmpfs的支援,sysfs為udev提供裝置入口和uevent通道,tmpfs為udev裝置檔案提供存放空間。
12,linux裝置模型:
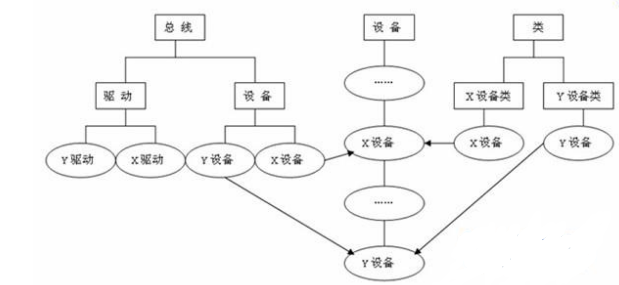
在linux核心中,分別使用bus_type,device_driver,device來描述匯流排、驅動和裝置,這3個結構體定義於include/linux/device.h標頭檔案中。驅動和裝置正是通過bus_type中的match()函式來配對的。
13, 重要結構體解析
(1)cdev結構體
在linux2.6核心中,使用cdev結構體描述一個字元裝置,定義如下:
struct cdev{
struct kobject kobj;//內嵌的kobject物件
struct module *owner;//所屬模組
struct file_operations *ops;//檔案操作結構體
struct list_head list;
dev_t dev;//裝置號,長度為32位,其中高12為主裝置號,低20位為此裝置號
unsigned int count;
};(2)file_operations結構體
結構體file_operations在標頭檔案linux/fs.h中定義,用來儲存驅動核心模組提供的對裝置進行各種操作的函式的指標。這些函式實際會在應用程式進行linux的open(),write(),read(),close()等系統呼叫時最終被呼叫。該結構體的每個域都對應著驅動核心模組用來處理某個被請求的事務的函式地址。原始碼(2.6.28.7)如下:
struct file_operations{
struct module*owner;
loff_t (*llseek)(struct file*,loff_t,int);
ssize_t (*read)(struct file*,char__user*,size_t,loff_t*);
ssize_t (*write)(struct file*,constchar__user*,size_t,loff_t*);
ssize_t (*aio_read)(struct kiocb*,cons tstruct iovec*,unsigned long,loff_t);
ssize_t (*aio_write)(struct kiocb*,const struct iovec*,unsigned long,loff_t);
int (*readdir)(struct file*,void*,filldir_t);
unsigned int (*poll)(struct file*,struct poll_table_struct*);
int (*ioctl)(struc inode*,struct file*,unsigned int,unsigned long);
long (*unlocked_ioctl)(struct file*,unsigned int,unsigned long);
long (*compat_ioctl)(struct file*,unsigned int,unsigned long);
int (*mmap)(struct file*,struct vm_area_struct*);
int (*open)(struct inode*,struct file*);
int (*flush)(struct file*,fl_owner_t id);
int (*release)(struct inode*,struct file*);
int (*fsync)(struct file*,struct dentry*,int datasync);
int (*aio_fsync)(struct kiocb*,int datasync);
in (*fasync)(int,struct file*,int);
int (*lock)(struct file*,int,struct file_lock*);
ssize_t (*sendpage)(struct file*,struct page*,int,size_t,loff_t*,int);
unsigned long (*get_unmapped_area)(struct file*,unsigned long,unsigned long,unsigned long,unsigned long);
in t(*check_flags)(int);
int (*dir_notify)(structfile*filp,unsignedlongarg);
int (*flock)(structfile*,int,structfile_lock*);
ssize_t (*splice_write)(struct pipe_inode_info*,struct file*,loff_t*,size_t,unsig ned int);
ssize_t (*splice_read)(struct file*,loff_t*,struct pipe_inode_info*,size_t,unsigned int);
int(*setlease)(struct file*,long,struct file_lock**);
}; 解析:
struct module*owner;
/*第一個file_operations成員根本不是一個操作;它是一個指向擁有這個結構的模組的指標.
這個成員用來在它的操作還在被使用時阻止模組被解除安裝.幾乎所有時間中,它被簡單初始化為
THIS_MODULE,一個在中定義的巨集.這個巨集比較複雜,在進行簡單學習操作的時候,一般初始化為THIS_MODULE。*/
loff_t (*llseek)(struct file*filp,loff_tp,int orig);
/*(指標引數filp為進行讀取資訊的目標檔案結構體指標;引數p為檔案定位的目標偏移量;引數orig為對檔案定位
的起始地址,這個值可以為檔案開頭(SEEK_SET,0,當前位置(SEEK_CUR,1),檔案末尾(SEEK_END,2))
llseek方法用作改變檔案中的當前讀/寫位置,並且新位置作為(正的)返回值.
loff_t引數是一個"longoffset",並且就算在32位平臺上也至少64位寬.錯誤由一個負返回值指示.
如果這個函式指標是NULL,seek呼叫會以潛在地無法預知的方式修改file結構中的位置計數器(在"file結構"一節中描述).*/
ssize_t (*read)(struct file *filp,char__user *buffer,size_t size,loff_t *p);
/*(指標引數filp為進行讀取資訊的目標檔案,指標引數buffer為對應放置資訊的緩衝區(即使用者空間記憶體地址),
引數size為要讀取的資訊長度,引數p為讀的位置相對於檔案開頭的偏移,在讀取資訊後,這個指標一般都會移動,移動的值為要讀取資訊的長度值)
這個函式用來從裝置中獲取資料.在這個位置的一個空指標導致read系統呼叫以-EINVAL("Invalidargument")失敗.
一個非負返回值代表了成功讀取的位元組數(返回值是一個"signedsize"型別,常常是目標平臺本地的整數型別).*/
ssize_t (*aio_read)(struct kiocb*,char__user *buffer,size_t size,loff_t p);
/*可以看出,這個函式的第一、三個引數和本結構體中的read()函式的第一、三個引數是不同的,
非同步讀寫的第三個引數直接傳遞值,而同步讀寫的第三個引數傳遞的是指標,因為AIO從來不需要改變檔案的位置。
非同步讀寫的第一個引數為指向kiocb結構體的指標,而同步讀寫的第一引數為指向file結構體的指標,每一個I/O請求都對應一個kiocb結構體);
初始化一個非同步讀--可能在函式返回前不結束的讀操作.如果這個方法是NULL,所有的操作會由read代替進行(同步地).
(有關linux非同步I/O,可以參考有關的資料,《linux裝置驅動開發詳解》中給出了詳細的解答)*/
ssize_t (*write)(struct file*filp,const char__user *buffer,size_t count,loff_t *ppos);
/*(引數filp為目標檔案結構體指標,buffer為要寫入檔案的資訊緩衝區,count為要寫入資訊的長度,
ppos為當前的偏移位置,這個值通常是用來判斷寫檔案是否越界)
傳送資料給裝置.如果NULL,-EINVAL返回給呼叫write系統呼叫的程式.如果非負,返回值代表成功寫的位元組數.
(注:這個操作和上面的對檔案進行讀的操作均為阻塞操作)*/
ssize_t (*aio_write)(struct kiocb*,const char__user *buffer,size_t count,loff_t *ppos);
/*初始化裝置上的一個非同步寫.引數型別同aio_read()函式;*/
int (*readdir)(struct file*filp,void*,filldir_t);
/*對於裝置檔案這個成員應當為NULL;它用來讀取目錄,並且僅對檔案系統有用.*/
unsigned int(*poll)(struct file*,struct poll_table_struct*);
/*(這是一個裝置驅動中的輪詢函式,第一個引數為file結構指標,第二個為輪詢表指標)
這個函式返回裝置資源的可獲取狀態,即POLLIN,POLLOUT,POLLPRI,POLLERR,POLLNVAL等巨集的位“或”結果。
每個巨集都表明裝置的一種狀態,如:POLLIN(定義為0x0001)意味著裝置可以無阻塞的讀,POLLOUT(定義為0x0004)意味著裝置可以無阻塞的寫。
(poll方法是3個系統呼叫的後端:poll,epoll,和select,都用作查詢對一個或多個檔案描述符的讀或寫是否會阻塞.
poll方法應當返回一個位掩碼指示是否非阻塞的讀或寫是可能的,並且,可能地,提供給核心資訊用來使呼叫程序睡眠直到I/O變為可能.
如果一個驅動的poll方法為NULL,裝置假定為不阻塞地可讀可寫.
(這裡通常將裝置看作一個檔案進行相關的操作,而輪詢操作的取值直接關係到裝置的響應情況,可以是阻塞操作結果,同時也可以是非阻塞操作結果)*/
int (*ioctl)(struct inode*inode,struct file*filp,unsigned int cmd,unsigned long arg);
/*(inode和filp指標是對應應用程式傳遞的檔案描述符fd的值,和傳遞給open方法的相同引數.
cmd引數從使用者那裡不改變地傳下來,並且可選的引數arg引數以一個unsignedlong的形式傳遞,不管它是否由使用者給定為一個整數或一個指標.
如果呼叫程式不傳遞第3個引數,被驅動操作收到的arg值是無定義的.
因為型別檢查在這個額外引數上被關閉,編譯器不能警告你如果一個無效的引數被傳遞給ioctl,並且任何關聯的錯誤將難以查詢.)
ioctl系統呼叫提供了發出裝置特定命令的方法(例如格式化軟盤的一個磁軌,這不是讀也不是寫).另外,幾個ioctl命令被核心識別而不必引用fops表.
如果裝置不提供ioctl方法,對於任何未事先定義的請求(-ENOTTY,"裝置無這樣的ioctl"),系統呼叫返回一個錯誤.*/
int(*mmap)(struct file*,struct vm_area_struct*);
/*mmap用來請求將裝置記憶體對映到程序的地址空間.如果這個方法是NULL,mmap系統呼叫返回-ENODEV.
(如果想對這個函式有個徹底的瞭解,那麼請看有關“程序地址空間”介紹的書籍)*/
int(*open)(struct inode *inode,struct file *filp);
/*(inode為檔案節點,這個節點只有一個,無論使用者開啟多少個檔案,都只是對應著一個inode結構;
但是filp就不同,只要開啟一個檔案,就對應著一個file結構體,file結構體通常用來追蹤檔案在執行時的狀態資訊)
儘管這常常是對裝置檔案進行的第一個操作,不要求驅動宣告一個對應的方法.如果這個項是NULL,裝置開啟一直成功,但是你的驅動不會得到通知.
與open()函式對應的是release()函式。*/
int(*flush)(struct file*);
/*flush操作在程序關閉它的裝置檔案描述符的拷貝時呼叫;它應當執行(並且等待)裝置的任何未完成的操作.
這個必須不要和使用者查詢請求的fsync操作混淆了.當前,flush在很少驅動中使用;
SCSI磁帶驅動使用它,例如,為確保所有寫的資料在裝置關閉前寫到磁帶上.如果flush為NULL,核心簡單地忽略使用者應用程式的請求.*/
int(*release)(struct inode*,struct file*);
/*release()函式當最後一個開啟裝置的使用者程序執行close()系統呼叫的時候,核心將呼叫驅動程式release()函式:
void release(struct inode inode,struct file *file),release函式的主要任務是清理未結束的輸入輸出操作,釋放資源,使用者自定義排他標誌的復位等。
在檔案結構被釋放時引用這個操作.如同open,release可以為NULL.*/
int (*synch)(struct file*,struct dentry*,intdatasync);
//重新整理待處理的資料,允許程序把所有的髒緩衝區重新整理到磁碟。
int(*aio_fsync)(struct kiocb*,int);
/*這是fsync方法的非同步版本.所謂的fsync方法是一個系統呼叫函式。系統呼叫fsync
把檔案所指定的檔案的所有髒緩衝區寫到磁碟中(如果需要,還包括存有索引節點的緩衝區)。
相應的服務例程獲得檔案物件的地址,並隨後呼叫fsync方法。通常這個方法以呼叫函式__writeback_single_inode()結束,
這個函式把與被選中的索引節點相關的髒頁和索引節點本身都寫回磁碟。*/
int(*fasync)(int,struct file*,int);
//這個函式是系統支援非同步通知的裝置驅動,下面是這個函式的模板:
static int***_fasync(intfd,structfile*filp,intmode)
{
struct***_dev*dev=filp->private_data;
returnfasync_helper(fd,filp,mode,&dev->async_queue);//第四個引數為fasync_struct結構體指標的指標。
//這個函式是用來處理FASYNC標誌的函式。(FASYNC:表示相容BSD的fcntl同步操作)當這個標誌改變時,驅動程式中的fasync()函式將得到執行。
}
/*此操作用來通知裝置它的FASYNC標誌的改變.非同步通知是一個高階的主題,在第6章中描述.
這個成員可以是NULL如果驅動不支援非同步通知.*/
int (*lock)(struct file*,int,struct file_lock*);
//lock方法用來實現檔案加鎖;加鎖對常規檔案是必不可少的特性,但是裝置驅動幾乎從不實現它.
ssize_t (*readv)(structfile*,const struct iovec*,unsigned long,loff_t*);
ssize_t (*writev)(struct file*,const struct iovec*,unsigned long,loff_t*);
/*這些方法實現發散/匯聚讀和寫操作.應用程式偶爾需要做一個包含多個記憶體區的單個讀或寫操作;
這些系統呼叫允許它們這樣做而不必對資料進行額外拷貝.如果這些函式指標為NULL,read和write方法被呼叫(可能多於一次).*/
ssize_t (*sendfile)(struct file*,loff_t*,size_t,read_actor_t,void*);
/*這個方法實現sendfile系統呼叫的讀,使用最少的拷貝從一個檔案描述符搬移資料到另一個.
例如,它被一個需要傳送檔案內容到一個網路連線的web伺服器使用.裝置驅動常常使sendfile為NULL.*/
ssize_t (*sendpage)(structfile*,structpage*,int,size_t,loff_t*,int);
/*sendpage是sendfile的另一半;它由核心呼叫來發送資料,一次一頁,到對應的檔案.裝置驅動實際上不實現sendpage.*/
unsigned long(*get_unmapped_area)(struct file*,unsigned long,unsignedlong,unsigned long,unsigned long);
/*這個方法的目的是在程序的地址空間找一個合適的位置來對映在底層裝置上的記憶體段中.
這個任務通常由記憶體管理程式碼進行;這個方法存在為了使驅動能強制特殊裝置可能有的任何的對齊請求.大部分驅動可以置這個方法為NULL.[10]*/
int (*check_flags)(int)
//這個方法允許模組檢查傳遞給fnctl(F_SETFL...)呼叫的標誌.
int (*dir_notify)(struct file*,unsigned long);
//這個方法在應用程式使用fcntl來請求目錄改變通知時呼叫.只對檔案系統有用;驅動不需要實現dir_notify.14, 字元裝置驅動程式設計基礎
主裝置號和次裝置號(二者一起為裝置號):
一個字元裝置或塊裝置都有一個主裝置號和一個次裝置號。主裝置號用來標識與裝置檔案相連的驅動程式,用來反映裝置型別。次裝置號被驅動程式用來辨別操作的是哪個裝置,用來區分同類型的裝置。
linux核心中,裝置號用dev_t來描述,2.6.28中定義如下:
typedef u_long dev_t;在32位機中是4個位元組,高12位表示主裝置號,低12位表示次裝置號。
可以使用下列巨集從dev_t中獲得主次裝置號:也可以使用下列巨集通過主次裝置號生成dev_t:
MAJOR(dev_tdev);
MKDEV(intmajor,intminor);
MINOR(dev_tdev);分配裝置號(兩種方法):
(1)靜態申請:
int register_chrdev_region(dev_t from,unsigned count,const char *name);
(2)動態分配:
int alloc_chrdev_region(dev_t *dev,unsigned baseminor,unsigned count,const char *name);
登出裝置號:
void unregister_chrdev_region(dev_t from,unsigned count);
建立裝置檔案:
利用cat/proc/devices檢視申請到的裝置名,裝置號。
(1)使用mknod手工建立:mknod filename type major minor
(2)自動建立;
利用udev(mdev)來實現裝置檔案的自動建立,首先應保證支援udev(mdev),由busybox配置。在驅動初始化程式碼裡呼叫class_create為該裝置建立一個class,再為每個裝置呼叫device_create建立對應的裝置。
15, 字元裝置驅動程式設計
設備註冊:
字元裝置的註冊分為三個步驟:
(1)分配
cdev:struct cdev *cdev_alloc(void);
(2)初始化
cdev:void cdev_init(struct cdev *cdev,const struct file_operations *fops);
(3)新增
cdev:int cdev_add(struct cdev *p,dev_t dev,unsigned count)
裝置操作的實現:
file_operations函式集的實現。
struct file_operations xxx_ops={
.owner=THIS_MODULE,
.llseek=xxx_llseek,
.read=xxx_read,
.write=xxx_write,
.ioctl=xxx_ioctl,
.open=xxx_open,
.release=xxx_release,
…
};特別注意:驅動程式應用程式的資料交換:
驅動程式和應用程式的資料交換是非常重要的。file_operations中的read()和write()函式,就是用來在驅動程式和應用程式間交換資料的。通過資料交換,驅動程式和應用程式可以彼此瞭解對方的情況。但是驅動程式和應用程式屬於不同的地址空間。驅動程式不能直接訪問應用程式的地址空間;同樣應用程式也不能直接訪問驅動程式的地址空間,否則會破壞彼此空間中的資料,從而造成系統崩潰,或者資料損壞。安全的方法是使用核心提供的專用函式,完成資料在應用程式空間和驅動程式空間的交換。這些函式對使用者程式傳過來的指標進行了嚴格的檢查和必要的轉換,從而保證使用者程式與驅動程式交換資料的安全性。這些函式有:
unsigned long copy_to_user(void__user *to,const void *from,unsigned long n);
unsigned long copy_from_user(void *to,constvoid __user *from,unsigned long n);
put_user(local,user);
get_user(local,user);設備註銷:
void cdev_del(struct cdev *p);
16,ioctl函式說明
ioctl是裝置驅動程式中對裝置的I/O通道進行管理的函式。所謂對I/O通道進行管理,就是對裝置的一些特性進行控制,例如串列埠的傳輸波特率、馬達的轉速等等。它的呼叫個數如下:
int ioctl(int fd,ind cmd,…);
其中fd就是使用者程式開啟裝置時使用open函式返回的檔案標示符,cmd就是使用者程式對裝置的控制命令,後面的省略號是一些補充引數,有或沒有是和cmd的意義相關的。
ioctl函式是檔案結構中的一個屬性分量,就是說如果你的驅動程式提供了對ioctl的支援,使用者就可以在使用者程式中使用ioctl函式控制裝置的I/O通道。
命令的組織是有一些講究的,因為我們一定要做到命令和裝置是一一對應的,這樣才不會將正確的命令發給錯誤的裝置,或者是把錯誤的命令發給正確的裝置,或者是把錯誤的命令發給錯誤的裝置。
所以在Linux核心中是這樣定義一個命令碼的:
| 裝置型別 | 序列號 | 方向 | 資料尺寸 |
|---|---|---|---|
| 8bit | 8bit | 2bit | 13~14bit |
這樣一來,一個命令就變成了一個整數形式的命令碼。但是命令碼非常的不直觀,所以LinuxKernel中提供了一些巨集,這些巨集可根據便於理解的字串生成命令碼,或者是從命令碼得到一些使用者可以理解的字串以標明這個命令對應的裝置型別、裝置序列號、資料傳送方向和資料傳輸尺寸。
點選(此處)摺疊或開啟
/*used to create numbers*/
#define _IO(type,nr) _IOC(_IOC_NONE,(type),(nr),0)
#define _IOR(type,nr,size) _IOC(_IOC_READ,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOW(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#defin e_IOR_BAD(type,nr,size) _IOC(_IOC_READ,(type),(nr),sizeof(size))
#define _IOW_BAD(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),sizeof(size))
#define _IOWR_BAD(type,nr,size)_IOC(_IOC_READ|_IOC_WRITE,(type),(nr),sizeof(size))
#define _IOC(dir,type,nr,size)\
(((dir)<<_IOC_DIRSHIFT)|\
((type)<<_IOC_TYPESHIFT)|\
((nr)<<_IOC_NRSHIFT)|\
((size)<<_IOC_SIZESHIFT))17,檔案私有資料
大多數linux的驅動工程師都將檔案私有資料private_data指向裝置結構體,read等個函式通過呼叫private_data來訪問裝置結構體。這樣做的目的是為了區分子裝置,如果一個驅動有兩個子裝置(次裝置號分別為0和1),那麼使用private_data就很方便。
這裡有一個函式要提出來:
container_of(ptr,type,member)//通過結構體成員的指標找到對應結構體的的指標
其定義如下:
/**
*container_of-castamemberofastructureouttothecontainingstructure
*@ptr: thepointertothemember.
*@type: thetypeofthecontainerstructthisisembeddedin.
*@member: thenameofthememberwithinthestruct.
*
*/
#define container_of(ptr,type,member)({ \
const typeof(((type*)0)->member)*__mptr=(ptr); \
(type*)((char*)__mptr-offsetof(type,member));})18,字元裝置驅動的結構
可以概括如下圖:
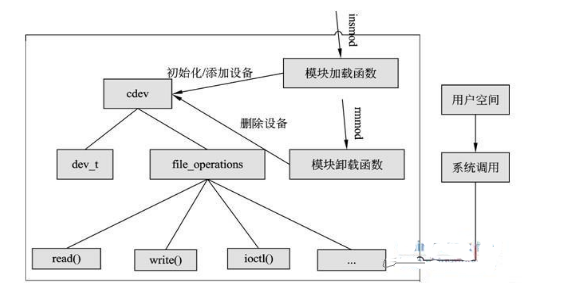
字元裝置是3大類裝置(字元裝置、塊裝置、網路裝置)中較簡單的一類裝置,其驅動程式中完成的主要工作是初始化、新增和刪除cdev結構體,申請和釋放裝置號,以及填充file_operation結構體中操作函式,並實現file_operations結構體中的read()、write()、ioctl()等重要函式。如圖所示為cdev結構體、file_operations和使用者空間呼叫驅動的關係。
19, 自旋鎖與訊號量
為了避免併發,防止競爭。核心提供了一組同步方法來提供對共享資料的保護。我們的重點不是介紹這些方法的詳細用法,而是強調為什麼使用這些方法和它們之間的差別。
Linux使用的同步機制可以說從2.0到2.6以來不斷髮展完善。從最初的原子操作,到後來的訊號量,從大核心鎖到今天的自旋鎖。這些同步機制的發展伴隨Linux從單處理器到對稱多處理器的過度;伴隨著從非搶佔核心到搶佔核心的過度。鎖機制越來越有效,也越來越複雜。目前來說核心中原子操作多用來做計數使用,其它情況最常用的是兩種鎖以及它們的變種:一個是自旋鎖,另一個是訊號量。
自旋鎖
自旋鎖是專為防止多處理器併發而引入的一種鎖,它在核心中大量應用於中斷處理等部分(對於單處理器來說,防止中斷處理中的併發可簡單採用關閉中斷的方式,不需要自旋鎖)。
自旋鎖最多隻能被一個核心任務持有,如果一個核心任務試圖請求一個已被爭用(已經被持有)的自旋鎖,那麼這個任務就會一直進行忙迴圈——旋轉——等待鎖重新可用。要是鎖未被爭用,請求它的核心任務便能立刻得到它並且繼續進行。自旋鎖可以在任何時刻防止多於一個的核心任務同時進入臨界區,因此這種鎖可有效地避免多處理器上併發執行的核心任務競爭共享資源。
自旋鎖的基本形式如下:
spin_lock(&mr_lock);
//臨界區
spin_unlock(&mr_lock);訊號量
Linux中的訊號量是一種睡眠鎖。如果有一個任務試圖獲得一個已被持有的訊號量時,訊號量會將其推入等待佇列,然後讓其睡眠。這時處理器獲得自由去執行其它程式碼。當持有訊號量的程序將訊號量釋放後,在等待佇列中的一個任務將被喚醒,從而便可以獲得這個訊號量。
訊號量的睡眠特性,使得訊號量適用於鎖會被長時間持有的情況;只能在程序上下文中使用,因為中斷上下文中是不能被排程的;另外當代碼持有訊號量時,不可以再持有自旋鎖。
訊號量基本使用形式為:
static DECLARE_MUTEX(mr_sem);//宣告互斥訊號量
if(down_interruptible(&mr_sem))
//可被中斷的睡眠,當訊號來到,睡眠的任務被喚醒
//臨界區
up(&mr_sem);訊號量和自旋鎖區別
從嚴格意義上說,訊號量和自旋鎖屬於不同層次的互斥手段,前者的實現有賴於後者,在訊號量本身的實現上,為了保證訊號量結構存取的原子性,在多CPU中需要自旋鎖來互斥。
訊號量是程序級的。用於多個程序之間對資源的互斥,雖然也是在核心中,但是該核心執行路徑是以程序的身份,代表程序來爭奪程序。鑑於程序上下文切換的開銷也很大,因此,只有當程序佔用資源時間比較長時,用訊號量才是較好的選擇。
當所要保護的臨界區訪問時間比較短時,用自旋鎖是非常方便的,因為它節省上下文切換的時間,但是CPU得不到自旋鎖會在那裡空轉直到執行單元鎖為止,所以要求鎖不能在臨界區里長時間停留,否則會降低系統的效率
由此,可以總結出自旋鎖和訊號量選用的3個原則:
1:當鎖不能獲取到時,使用訊號量的開銷就是程序上線文切換的時間Tc,使用自旋鎖的開銷就是等待自旋鎖(由臨界區執行的時間決定)Ts,如果Ts比較小時,應使用自旋鎖比較好,如果Ts比較大,應使用訊號量。
2:訊號量所保護的臨界區可包含可能引起阻塞的程式碼,而自旋鎖絕對要避免用來保護包含這樣的程式碼的臨界區,因為阻塞意味著要進行程序間的切換,如果程序被切換出去後,另一個程序企圖獲取本自旋鎖,死鎖就會發生。
3:訊號量存在於程序上下文,因此,如果被保護的共享資源需要在中斷或軟中斷情況下使用,則在訊號量和自旋鎖之間只能選擇自旋鎖,當然,如果一定要是要那個訊號量,則只能通過down_trylock()方式進行,不能獲得就立即返回以避免阻塞
自旋鎖VS訊號量
需求建議的加鎖方法
低開銷加鎖優先使用自旋鎖
短期鎖定優先使用自旋鎖
長期加鎖優先使用訊號量
中斷上下文中加鎖使用自旋鎖
持有鎖是需要睡眠、排程使用訊號量
20, 阻塞與非阻塞I/O
一個驅動當它無法立刻滿足請求應當如何響應?一個對 read 的呼叫可能當沒有資料時到來,而以後會期待更多的資料;或者一個程序可能試圖寫,但是你的裝置沒有準備好接受資料,因為你的輸出緩衝滿了。呼叫程序往往不關心這種問題,程式設計師只希望呼叫 read 或 write 並且使呼叫返回,在必要的工作已完成後,你的驅動應當(預設地)阻塞程序,使它進入睡眠直到請求可繼續。
阻塞操作是指在執行裝置操作時若不能獲得資源則掛起程序,直到滿足可操作的條件後再進行操作。
一個典型的能同時處理阻塞與非阻塞的globalfifo讀函式如下:
/*globalfifo讀函式*/
static ssize_t globalfifo_read(struct file *filp, char __user *buf, size_t count,
loff_t *ppos)
{
int ret;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
down(&dev->sem); /* 獲得訊號量 */
add_wait_queue(&dev->r_wait, &wait); /* 進入讀等待佇列頭 */
/* 等待FIFO非空 */
if (dev->current_len == 0) {
if (filp->f_flags &O_NONBLOCK) {
ret = - EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE); /* 改變程序狀態為睡眠 */
up(&dev->sem);
schedule(); /* 排程其他程序執行 */
if (signal_pending(current)) {
/* 如果是因為訊號喚醒 */
ret = - ERESTARTSYS;
goto out2;
}
down(&dev->sem);
}
/* 拷貝到使用者空間 */
if (count > dev->current_len)
count = dev->current_len;
if (copy_to_user(buf, dev->mem, count)) {
ret = - EFAULT;
goto out;
} else {
memcpy(dev->mem, dev->mem + count, dev->current_len - count); /* fifo資料前移 */
dev->current_len -= count; /* 有效資料長度減少 */
printk(KERN_INFO "read %d bytes(s),current_len:%d\n", count, dev->current_len);
wake_up_interruptible(&dev->w_wait); /* 喚醒寫等待佇列 */
ret = count;
}
out:
up(&dev->sem); /* 釋放訊號量 */
out2:
remove_wait_queue(&dev->w_wait, &wait); /* 從附屬的等待佇列頭移除 */
set_current_state(TASK_RUNNING);
return ret;
}
21, poll方法
使用非阻塞I/O的應用程式通常會使用select()和poll()系統呼叫查詢是否可對裝置進行無阻塞的訪問。select()和poll()系統呼叫最終會引發裝置驅動中的poll()函式被執行。
這個方法由下列的原型:
unsigned int (*poll) (struct file *filp, poll_table *wait);
這個驅動方法被呼叫, 無論何時使用者空間程式進行一個 poll, select, 或者 epoll 系統呼叫, 涉及一個和驅動相關的檔案描述符. 這個裝置方法負責這 2 步:
- 對可能引起裝置檔案狀態變化的等待佇列,呼叫
poll_wait()函式,將對應的等待佇列頭新增到poll_table. - 返回一個位掩碼, 描述可能不必阻塞就立刻進行的操作.
poll_table結構, 給 poll 方法的第 2 個引數, 在核心中用來實現 poll, select, 和 epoll 呼叫; 它在 中宣告, 這個檔案必須被驅動原始碼包含. 驅動編寫者不必要知道所有它內容並且必須作為一個不透明的物件使用它; 它被傳遞給驅動方法以便驅動可用每個能喚醒程序的等待佇列來載入它, 並且可改變 poll 操作狀態. 驅動增加一個等待佇列到poll_table結構通過呼叫函式 poll_wait:
void poll_wait (struct file *, wait_queue_head_t *, poll_table *);
poll 方法的第 2 個任務是返回位掩碼, 它描述哪個操作可馬上被實現; 這也是直接的. 例如, 如果裝置有資料可用, 一個讀可能不必睡眠而完成; poll 方法應當指示這個時間狀態. 幾個標誌(通過 定義)用來指示可能的操作:
POLLIN:如果裝置可被不阻塞地讀, 這個位必須設定.
POLLRDNORM:這個位必須設定, 如果”正常”資料可用來讀. 一個可讀的裝置返回( POLLIN|POLLRDNORM ).
POLLOUT:這個位在返回值中設定, 如果裝置可被寫入而不阻塞.
……
poll的一個典型模板如下:
static unsigned int globalfifo_poll(struct file *filp, poll_table *wait)
{
unsigned int mask = 0;
struct globalfifo_dev *dev = filp->private_data; /*獲得裝置結構體指標*/
down(&dev->sem);
poll_wait(filp, &dev->r_wait, wait);
poll_wait(filp, &dev->w_wait, wait);
/*fifo非空*/
if (dev->current_len != 0) {
mask |= POLLIN | POLLRDNORM; /*標示資料可獲得*/
}
/*fifo非滿*/
if (dev->current_len != GLOBALFIFO_SIZE) {
mask |= POLLOUT | POLLWRNORM; /*標示資料可寫入*/
}
up(&dev->sem);
return mask;
}應用程式如何去使用這個poll呢?一般用select()來實現,其原型為:
int select(int numfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
其中,readfds, writefds, exceptfds,分別是被select()監視的讀、寫和異常處理的檔案描述符集合。numfds是需要檢查的號碼最高的檔案描述符加1。
以下是一個具體的例子:
/*======================================================================
A test program in userspace
This example is to introduce the ways to use "select"
and driver poll
The initial developer of the original code is Baohua Song
<[email protected]>. All Rights Reserved.
======================================================================*/
#include <sys/types.h>
#include <sys/stat.h>
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/time.h>
#define FIFO_CLEAR 0x1
#define BUFFER_LEN 20
main()
{
int fd, num;
char rd_ch[BUFFER_LEN];
fd_set rfds,wfds;
/*以非阻塞方式開啟/dev/globalmem裝置檔案*/
fd = open("/dev/globalfifo", O_RDONLY | O_NONBLOCK);
if (fd != - 1)
{
/*FIFO清0*/
if (ioctl(fd, FIFO_CLEAR, 0) < 0)
{
printf("ioctl command failed\n");
}
while (1)
{
FD_ZERO(&rfds);// 清除一個檔案描述符集rfds
FD_ZERO(&wfds);
FD_SET(fd, &rfds);// 將一個檔案描述符fd,加入到檔案描述符集rfds中
FD_SET(fd, &wfds);
select(fd + 1, &rfds, &wfds, NULL, NULL);
/*資料可獲得*/
if (FD_ISSET(fd, &rfds)) //判斷檔案描述符fd是否被置位
{
printf("Poll monitor:can be read\n");
}
/*資料可寫入*/
if (FD_ISSET(fd, &wfds))
{
printf("Poll monitor:can be written\n");
}
}
}
else
{
printf("Device open failure\n");
}
}其中:
FD_ZERO(fd_set *set); //清除一個檔案描述符集set
FD_SET(int fd, fd_set *set); //將一個檔案描述符fd,加入到檔案描述符集set中
FD_CLEAR(int fd, fd_set *set); //將一個檔案描述符fd,從檔案描述符集set中清除
FD_ISSET(int fd, fd_set *set); //判斷檔案描述符fd是否被置位。
22,併發與競態介紹
Linux裝置驅動中必須解決一個問題是多個程序對共享資源的併發訪問,併發的訪問會導致競態,在當今的Linux核心中,支援SMP與核心搶佔的環境下,更是充滿了併發與競態。幸運的是,Linux 提供了多鍾解決競態問題的方式,這些方式適合不同的應用場景。例如:中斷遮蔽、原子操作、自旋鎖、訊號量等等併發控制機制。
併發與競態的概念
併發是指多個執行單元同時、併發被執行,而併發的執行單元對共享資源(硬體資源和軟體上的全域性變數、靜態變數等)的訪問則很容易導致競態。
臨界區概念是為解決競態條件問題而產生的,一個臨界區是一個不允許多路訪問的受保護的程式碼,這段程式碼可以操縱共享資料或共享服務。臨界區操縱堅持互斥鎖原則(當一個執行緒處於臨界區中,其他所有執行緒都不能進入臨界區)。然而,臨界區中需要解決的一個問題是死鎖。
23, 中斷遮蔽
在單CPU 範圍內避免競態的一種簡單而省事的方法是進入臨界區之前遮蔽系統的中斷。CPU 一般都具有遮蔽中斷和開啟