
postgresql中實現按周統計詳解
在做報表這種,我們經常會遇到各種各樣的需求,按周統計就是一種。剛啊看到這個需求可能會一臉懵逼,不知如何下手。甚至有的人會利用最原始的方法,將客戶所選日期拆分成N周,每一週都獲取一下週一和周天時間,然後每週查詢一次。這樣的haul執行效率非常的低下,那有沒有更好的方法實現啦,肯定是有的,這個時候我們就要了解一下資料庫自帶的函式。
SELECT EXTRACT(DOW FROM CURRENT_DATE); 執行結果如下。
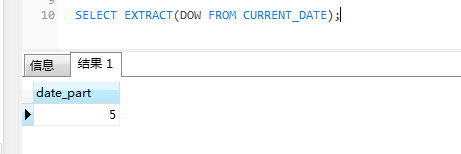
這個SQL語句的意思就是計算當前日期是一週中的第幾天。
EXTRACT(DOW FROM CURRENT_DATE) 函式的返回值,0表示星期天,6表示星期六。
因為外國人的習慣是一週從週日開始,二我們中國人的習慣一週的開始是星期一。
下面我們就來講一下按周統計的思路,如果我們能夠將表中的時間欄位,都改造成對應時間的週一時間。那我們就可以實現。
示例。那我們只需要按這個日期分組統計就可以實現按周統計。
例如今天2019-01-11,是星期五,我麼把他變成對應這周星期一的時間2018-01-07
同樣2019-01-10,星期四,改成對應的週一時間2018-01-07。依次將所有日期改造,就可以實現按周統計
那麼如何將日期欄位,改造成對應週一時間就是一個問題。
以上我們通過 EXTRACT(DOW FROM CURRENT_DATE)可以知道當前時間對應在一週找那個的天數。如果我們能夠用對應時間往前推他在一週的天數。例如今天2019-01-11號星期五,如果我們把時間往前推4天,我就可以得到對應這天週一的天數,首先我們需要改造一下EXTRACT(DOW FROM CURRENT_DATE)函式,以適應我們國人週一為一週的開始。
SELECT (EXTRACT(DOW FROM CURRENT_DATE)-1) diffday; 明顯週一與週五之間相差4天。我們用當前日期往前推4天便得到星期一的日期
SELECT CURRENT_DATE-(EXTRACT(DOW FROM CURRENT_DATE)-1||'day')::interval diffday;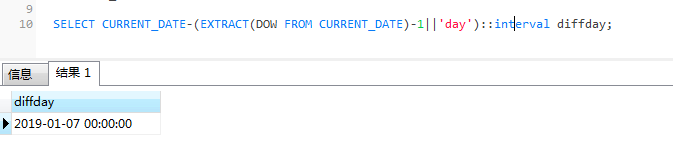
2019-01-07便是星期一的日器。下面我們一表為基礎實現

一共6條資料,我們統計每週的數量
select row_time::DATE-(extract(dow from row_time::TIMESTAMP)-1||'day')::interval monday, count(*) amount from acd_details where 1=1 GROUP BY row_time::DATE-(extract(dow from row_time::TIMESTAMP)-1||'day')::interval
下面看一下上面語句的執行效果
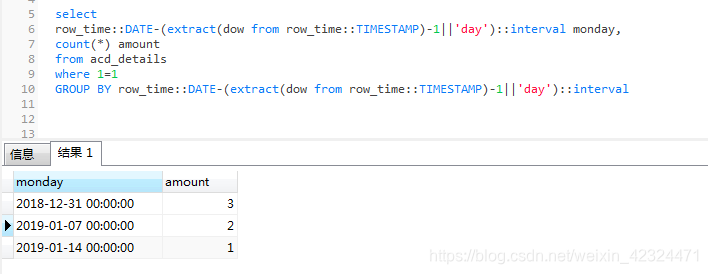
顯示的日期為每週週一的時間,總共六條資料,第一週(2018-12-31-2019-01-06) 3條
第二週(2019-01-07-2019-01-13) 2條,第三週(2019-01-14-2019-01-20) 1條。,至此大功告成。