
KMP演算法最淺顯理解——一看就明白
說明
KMP演算法看懂了覺得特別簡單,思路很簡單,看不懂之前,查各種資料,看的稀裡糊塗,即使網上最簡單的解釋,依然看的稀裡糊塗。
我花了半天時間,爭取用最短的篇幅大致搞明白這玩意到底是啥。
這裡不扯概念,只講演算法過程和程式碼理解:
KMP演算法求解什麼型別問題
字串匹配。給你兩個字串,尋找其中一個字串是否包含另一個字串,如果包含,返回包含的起始位置。
如下面兩個字串:
char *str = "bacbababadababacambabacaddababacasdsd";
char *ptr = "ababaca";str有兩處包含ptr
分別在str的下標10,26處包含ptr。
“bacbababadababacambabacaddababacasdsd”;\

問題型別很簡單,下面直接介紹演算法
演算法說明
一般匹配字串時,我們從目標字串str(假設長度為n)的第一個下標選取和ptr長度(長度為m)一樣的子字串進行比較,如果一樣,就返回開始處的下標值,不一樣,選取str下一個下標,同樣選取長度為n的字串進行比較,直到str的末尾(實際比較時,下標移動到n-m)。這樣的時間複雜度是O(n*m)。
KMP演算法:可以實現複雜度為O(m+n)
為何簡化了時間複雜度:
充分利用了目標字串ptr的性質(比如裡面部分字串的重複性,即使不存在重複欄位,在比較時,實現最大的移動量)。
上面理不理解無所謂,我說的其實也沒有深刻剖析裡面的內部原因。
考察目標字串ptr:
ababaca
這裡我們要計算一個長度為m的轉移函式next。
next陣列的含義就是一個固定字串的最長字首和最長字尾相同的長度。
比如:abcjkdabc,那麼這個陣列的最長字首和最長字尾相同必然是abc。
cbcbc,最長字首和最長字尾相同是cbc。
abcbc,最長字首和最長字尾相同是不存在的。
**注意最長字首:是說以第一個字元開始,但是不包含最後一個字元。
比如aaaa相同的最長字首和最長字尾是aaa。**
對於目標字串ptr,ababaca,長度是7,所以next[0],next[1],next[2],next[3],next[4],next[5],next[6]分別計算的是
a
下圖中的1,2,3,4是一樣的。1-2之間的和3-4之間的也是一樣的,我們發現A和B不一樣;之前的演算法是我把下面的字串往前移動一個距離,重新從頭開始比較,那必然存在很多重複的比較。現在的做法是,我把下面的字串往前移動,使3和2對其,直接比較C和A是否一樣。
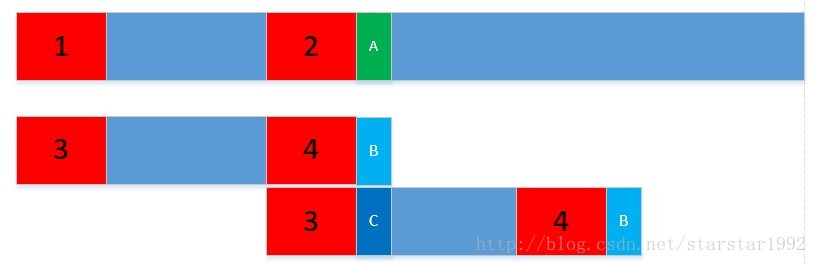

程式碼解析
void cal_next(char *str, int *next, int len)
{
next[0] = -1;//next[0]初始化為-1,-1表示不存在相同的最大字首和最大字尾
int k = -1;//k初始化為-1
for (int q = 1; q <= len-1; q++)
{
while (k > -1 && str[k + 1] != str[q])//如果下一個不同,那麼k就變成next[k],注意next[k]是小於k的,無論k取任何值。
{
k = next[k];//往前回溯
}
if (str[k + 1] == str[q])//如果相同,k++
{
k = k + 1;
}
next[q] = k;//這個是把算的k的值(就是相同的最大字首和最大字尾長)賦給next[q]
}
}KMP
這個和next很像,具體就看程式碼,其實上面已經大概說完了整個匹配過程。
int KMP(char *str, int slen, char *ptr, int plen)
{
int *next = new int[plen];
cal_next(ptr, next, plen);//計算next陣列
int k = -1;
for (int i = 0; i < slen; i++)
{
while (k >-1&& ptr[k + 1] != str[i])//ptr和str不匹配,且k>-1(表示ptr和str有部分匹配)
k = next[k];//往前回溯
if (ptr[k + 1] == str[i])
k = k + 1;
if (k == plen-1)//說明k移動到ptr的最末端
{
//cout << "在位置" << i-plen+1<< endl;
//k = -1;//重新初始化,尋找下一個
//i = i - plen + 1;//i定位到該位置,外層for迴圈i++可以繼續找下一個(這裡預設存在兩個匹配字串可以部分重疊),感謝評論中同學指出錯誤。
return i-plen+1;//返回相應的位置
}
}
return -1;
}測試
char *str = "bacbababadababacambabacaddababacasdsd";
char *ptr = "ababaca";
int a = KMP(str, 36, ptr, 7);
return 0;注意如果str裡有多個匹配ptr的字串,要想求出所有的滿足要求的下標位置,在KMP演算法需要稍微修改一下。見上面註釋掉的程式碼。
複雜度分析
next函式計算複雜度是(m),開始以為是O(m^2),後來仔細想了想,cal__next裡的while迴圈,以及外層for迴圈,利用均攤思想,其實是O(m),這個以後想好了再寫上。
………………………………………..分割線……………………………………..
其實本文已經結束,後面的只是針對評論裡的疑問,我嘗試著進行解答的。
進一步說明(2018-3-14)
看了評論,大家對cal_next(..)函式和KMP()函式裡的
while (k > -1 && str[k + 1] != str[q])
{
k = next[k];
}和
while (k >-1&& ptr[k + 1] != str[i])
k = next[k];這個while迴圈和k=next[k]很疑惑!
確實啊,我開始看這幾行程式碼,相當懵逼,這寫的啥啊,為啥這樣寫;後來上機跑了一下,慢慢了解到為何這樣寫了。這幾行程式碼,可謂是對KMP演算法本質得了解非常清楚才能想到的。很牛逼!
直接看cal_next(..)函式:
首先我們看第一個while迴圈,它到底幹了什麼。
在此之前,我們先回到原程式。原程式裡有一個大的for()迴圈,那這個for()迴圈是幹嘛的?
這個for迴圈就是計算next[0],next[1],…next[q]…的值。
裡面最後一句next[q]=k就是說明每次迴圈結束,我們已經計算了ptr的前(q+1)個字母組成的子串的“相同的最長字首和最長字尾的長度”。(這句話前面已經解釋了!) 這個“長度”就是k。
好,到此為止,假設迴圈進行到 第 q 次,即已經計算了next[q],我們是怎麼計算next[q+1]呢?
比如我們已經知道ababab,q=4時,next[4]=2(k=2,表示該字串的前5個字母組成的子串ababa存在相同的最長字首和最長字尾的長度是3,所以k=2,next[4]=2。這個結果可以理解成我們自己觀察算的,也可以理解成程式自己算的,這不是重點,重點是程式根據目前的結果怎麼算next[5]的).,那麼對於字串ababab,我們計算next[5]的時候,此時q=5, k=2(上一步迴圈結束後的結果)。那麼我們需要比較的是str[k+1]和str[q]是否相等,其實就是str[1]和str[5]是否相等!,為啥從k+1比較呢,因為上一次迴圈中,我們已經保證了str[k]和str[q](注意這個q是上次迴圈的q)是相等的(這句話自己想想,很容易理解),所以到本次迴圈,我們直接比較str[k+1]和str[q]是否相等(這個q是本次迴圈的q)。
如果相等,那麼跳出while(),進入if(),k=k+1,接著next[q]=k。即對於ababab,我們會得出next[5]=3。 這是程式自己算的,和我們觀察的是一樣的。
如果不等,我們可以用”ababac“描述這種情況。 不等,進入while()裡面,進行k=next[k],這句話是說,在str[k + 1] != str[q]的情況下,我們往前找一個k,使str[k + 1]==str[q],是往前一個一個找呢,還是有更快的找法呢? (一個一個找必然可以,即你把 k = next[k] 換成k- -也是完全能執行的(更正:這句話不對啊,把k=next[k]換成k–是不行的,評論25樓舉了個反例)。但是程式給出了一種更快的找法,那就是 k = next[k]。 程式的意思是說,一旦str[k + 1] != str[q],即在後綴裡面找不到時,我是可以直接跳過中間一段,跑到字首裡面找,next[k]就是相同的最長字首和最長字尾的長度。所以,k=next[k]就變成,k=next[2],即k=0。此時再比較str[0+1]和str[5]是否相等,不等,則k=next[0]=-1。跳出迴圈。
(這個解釋能懂不?)
以上就是這個cal_next()函式裡的
while (k > -1 && str[k + 1] != str[q])
{
k = next[k];
}最難理解的地方的一個我的理解,有不對的歡迎指出。
複雜度分析:
分析KMP複雜度,那就直接看KMP函式。
int KMP(char *str, int slen, char *ptr, int plen)
{
int *next = new int[plen];
cal_next(ptr, next, plen);//計算next陣列
int k = -1;
for (int i = 0; i < slen; i++)
{
while (k >-1&& ptr[k + 1] != str[i])//ptr和str不匹配,且k>-1(表示ptr和str有部分匹配)
k = next[k];//往前回溯
if (ptr[k + 1] == str[i])
k = k + 1;
if (k == plen-1)//說明k移動到ptr的最末端
{
//cout << "在位置" << i-plen+1<< endl;
//k = -1;//重新初始化,尋找下一個
//i = i - plen + 1;//i定位到該位置,外層for迴圈i++可以繼續找下一個(這裡預設存在兩個匹配字串可以部分重疊),感謝評論中同學指出錯誤。
return i-plen+1;//返回相應的位置
}
}
return -1;
}這玩意真的不好解釋,簡單說一下:
從程式碼解釋複雜度是一件比較難的事情,我們從
這個圖來解釋。
我們可以看到,匹配串每次往前移動,都是一大段一大段移動,假設匹配串裡不存在重複的字首和字尾,即next的值都是-1,那麼每次移動其實就是一整個匹配串往前移動m個距離。然後重新一一比較,這樣就比較m次,概括為,移動m距離,比較m次,移到末尾,就是比較n次,O(n)複雜度。 假設匹配串裡存在重複的字首和字尾,我們移動的距離相對小了點,但是比較的次數也小了,整體代價也是O(n)。
所以複雜度是一個線性的複雜度。
相關推薦
KMP演算法最淺顯理解——一看就明白
說明 KMP演算法看懂了覺得特別簡單,思路很簡單,看不懂之前,查各種資料,看的稀裡糊塗,即使網上最簡單的解釋,依然看的稀裡糊塗。 我花了半天時間,爭取用最短的篇幅大致搞明白這玩意到底是啥。 這裡不扯概念,只講演算法過程和程式碼理解: KMP演算法求解
KMP演算法最淺顯理解
說明 KMP演算法看懂了覺得特別簡單,思路很簡單,看不懂之前,查各種資料,看的稀裡糊塗,即使網上最簡單的解釋,依然看的稀裡糊塗。 我花了半天時間,爭取用最短的篇幅大致搞明白這玩意到底是啥。 這裡不扯概念,只講演算法過程和程式碼理解: KMP演算法求解什麼型別問題
Spring AOP面向切面程式設計:理解篇(一看就明白)
一、到底什麼是AOP(面向切面程式設計)? 無論在學習或者面試的時候,大家都會張口說spring的特性AOP和IOC(控制反轉咱們下一篇講),有些大神理解的很到位,但是對於大多數初中級工程師來講還是模糊階段,但是為什麼會有AOP這種技術呢?傻瓜都知道:為了開發者的方便!
Unity3D《一看就明白系列》之讀取Txt (一)
策劃寫Excel ---> 程式解析Excel為Text(letter) --->程式讀取Txt 檔案路徑: Appliction.dataPath 專案資源路徑 Application.
Unity3D《一看就明白系列》之Unity3D中使用SqlLite資料庫(二)採用框架結構
主要就是增刪改查,而這些操作語句我們主要就是更改其中的引數。 因此我們需要做一個架構來實現這一目標 DB:整體 中間功能層:實現功能 邏輯層:在功能層之下實現不同的邏輯 For Example: Void Add(a,b)這是一個功能實現兩個數相加 Add(2,
Unity3D《一看就明白系列》之Unity3D中使用SqlLite資料庫 (一)
遊戲開發主要是關係資料庫,兩張表之間有關係,減少資訊冗餘 PC:後端 mysql 前端:手機端等輕量級 sqlLite,主義是記錄資訊,設計簡單的增刪改查 注意事項: 對大小寫不敏感 Create CR
貝葉斯分類(這個講的比較清晰,一看就明白)
原文地址:http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html 1.2、分類問題綜述 對於分類問題,其實誰都不會陌生,說我們每個人每天都在執行分類操
Android Dagger2 MVP架構 一看就明白
Dagger2介紹 好了,介紹一下Dagger2吧! Dagger2 是Google 的新一代依賴注入框架(依賴注入不講,你都看到這篇文章了,那你應該懂,如果不懂,請度娘、谷哥之,此文不廢話),Dagger2是Dagger1的分支,但兩個框架沒有嚴格的繼承關
關於vue下跨域問題,一看就明白!
最終還是遇到了跨域問題,經過一下午的各種嘗試終於成功的掉到了想要的東西,下面就來寫一下是如何實現的,也算是給後來者填個坑: 你需要做一個反向代理的東西開啟你的vue專案的config資料夾下的index.js 然後找到以下的程式碼: dev:
讓你一看就明白的binder機制
寫在前面 網上有很多學習android binder機制的文章和部落格,但是大部分或者是深入native不能自拔,看的雲裡霧裡(本人一直使用java,C語言較渣);或者是隻講理論缺乏實際程式設計的過程。所以就想總結下binder的基本理論並附帶一個基於Aidl
HashMap實現原理簡析及實現的demo(一看就明白)
transient 獲取 img 超過 微軟 fault font isempty throw HashMap底層就是一個數組結構,數組中的每一項又是一個鏈表。 jdk源碼: 1 transient Node<K,V>[] table; 2
最簡單24點演算法,可任意實現n數n點,一看就明!
介紹 網上的24點演算法基本上都專注於4張牌湊24點,有的演算法甚至枚舉了所有括號的組合,讓人看得頭暈眼花。這些演算法若是推廣到n個數湊n點,基本都歇菜了。 本演算法採用暴力列舉法,能處理任意個數湊任意值。以24點為例,本演算法會枚舉出4個數+3個運算子能組成的所
kmp演算法(最簡單最直觀的理解,看完包會)
本文將以特殊的方式來讓人們更好地理解kmp演算法,不包括kmp演算法的推導,接下來,我們將從樸素演算法出發。 在這之前,我們先設主串為S,模式串為T,我們要解決的詢問是主串中是否包含模式串(即T是否為S的子串)。 版權宣告:本文為原創文章,轉載請標明出處。
演算法的時間與空間複雜度(一看就懂)
演算法(Algorithm)是指用來操作資料、解決程式問題的一組方法。對於同一個問題,使用不同的演算法,也許最終得到的結果是一樣的,但在過程中消耗的資源和時間卻會有很大的區別。 那麼我們應該如何去衡量不同演算法之間的優劣呢? 主要還是從演算法所佔用的「時間」和「空間」兩個維度去考量。 時間維
一看就懂的Alpha-Beta剪枝演算法詳解
原貼:http://blog.csdn.net/tangchenyi/article/details/22925957 Alpha-Beta剪枝演算法(Alpha Beta Pruning) Alpha-Beta剪枝用於裁剪搜尋樹中沒有意義的不需要搜尋的樹枝,以
一看就懂的 Alpha-Beta 剪枝演算法詳解
Alpha-Beta剪枝用於裁剪搜尋樹中沒有意義的不需要搜尋的樹枝,以提高運算速度。假設α為下界
史上最簡單的Elasticsearch教程-第四章:Elasticsearch與Mysql的區別,一看就懂
Es與Mysql的區別,一看就懂! (提前宣告:文章由作者:張耀烽/CSDN主頁:https://blog.csdn.net/youbitch1/ 結合自己生產中的使用經驗整理,最終形成簡單易懂的文章,寫作不易,轉載請註明) (整個教程的ES版本以及Kibana版本
演算法-把n個數的每一種排列情況都列出來(排列組合)-全排列-字典序演算法(一看就懂)
首先需要介紹字典序演算法 比如 236541想找到下一個比它大的數 他有3個步驟 1.從最右邊開始找到第一組 左小於右的數 41 54 65 36 23 這樣找,很顯然,我們找到36就找到了,後面的就不用找了。 2.找到之後立刻交換嗎?不是的。定位了這個3以後,再從右邊開始
一看就懂的K近鄰演算法(KNN),K-D樹,並實現手寫數字識別!
1. 什麼是KNN 1.1 KNN的通俗解釋 何謂K近鄰演算法,即K-Nearest Neighbor algorithm,簡稱KNN演算法,單從名字來猜想,可以簡單粗暴的認為是:K個最近的鄰居,當K=1時,演算法便成了最近鄰演算法,即尋找最近的那個鄰居。 用官方的話來說,所謂K近鄰演算法,即是給定一個訓練資
演算法一看就懂之「 陣列與連結串列 」
資料結構是我們軟體開發中最基礎的部分了,它體現著我們程式設計的內功。大多數人在正兒八經學習資料結構的時候估計是在大學計算機課上,而在實際專案開發中,反而感覺到用得不多。 其實也不是真的用得少,只不過我們在使用的時候被很多高階語言和框架元件封裝好了,真正需要自己去實現的地方比較少而已。但別人封裝好了不代