
乾貨分享:SparkBench--Spark平臺的基準效能測試
SparkBench簡介
SparkBench是Spark的基準效能測試專案,由來自IBM Watson研究中心的五位研究者(Min Li, Jian Tan, Yandong Wang, Li Zhang, Valentina Salapura)發起,並貢獻至開源社群。
SparkBench的測試專案覆蓋了Spark支援的四種最主流的應用型別,即機器學習、圖計算、SQL查詢和流資料計算。每種型別的應用又選擇了最常用的幾個演算法或者應用進行比對測試,測試結果從系統資源消耗、時間消耗、資料流特點等各方面全面考察,總體而言是比較全面的測試。
所有的研究結果以論文的形式公開發布,原文可在SparkBench的官方網站下載,測試相關的資料和程式碼也可下載供測試使用,本文將主要的研究結果呈現給大家。
SparkBench的目的
SparkBench最主要的目的是通過基準效能測試,研究Spark與傳統計算平臺的不同之處,為搭建Spark平臺提供參考和通用指導原則。具體而言SparkBench可以在如下場景中發揮作用:
1、重點領域需要有參考資料和定量分析結果,包括:Spark快取設定、記憶體管理優化、排程策略;
2、需要不同硬體、不同平臺中執行Spark的效能參照資料;
3、尋找Spark叢集規劃指導原則,幫助定位資源配置中的瓶頸,通過合理的配置使資源競爭最小化;
4、需要從多個角度深入分析Spark平臺,包括:負載型別、關鍵配置引數、擴充套件性和容錯性等
SparkBench測試專案
SparkBench主要的的測試專案,按負載型別劃分如下表所示:
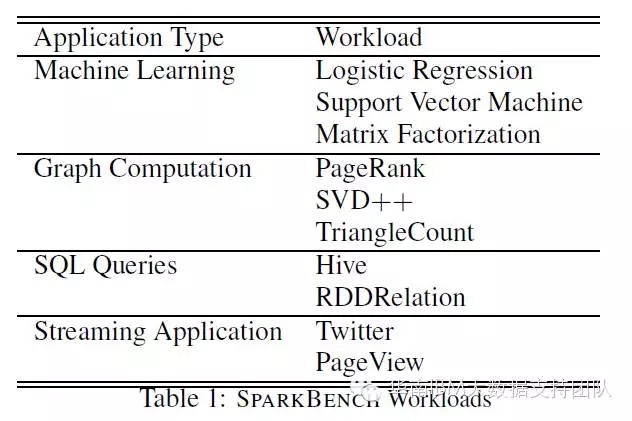
其中機器學習型別選擇了最常用的邏輯迴歸、支援向量機和矩陣分解演算法,這些是在進行資料歸類或者構建推薦系統時最常用的機器學習演算法,很有代表性。圖計算類別中選取了最流行的三種圖計算演算法:PangeRank、SVD++和TriangleCount,各具特點。SQL查詢類別同時測試了Hive on Spark和原生態的Spark SQL,測試覆蓋最常用的三種SQL操作:select、aggregate和 join。流計算類別分別測試了Twitter資料介面Twitter4j的流資料和模擬使用者訪問網頁的流資料(PageView)。
除了表中列出的測試專案,目前最新版本的SparkBench還包括很多其他負載型別的測試專案:KMeans,LinearRegression,DecisionTree,ShortestPaths, LabelPropagation, ConnectedComponent, StronglyConnectedComponent,PregelOperatio。
SparkBench的測試資料
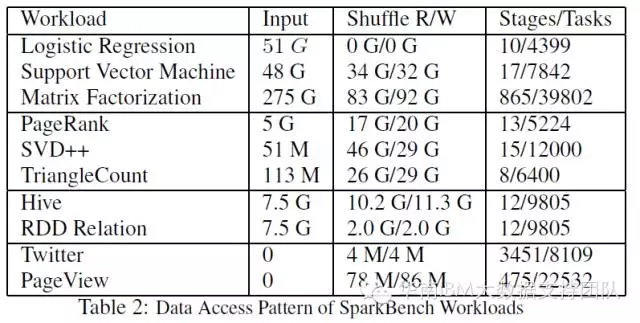
SparkBench大部分測試資料由專案自帶的資料生成器生成,其中SQL查詢使用模擬生成的電子商務系統的訂單資料,流計算使用的分別是Twitter資料(Twitter4j每60秒釋出一次最熱門的標籤資料)和模擬生成的使用者活動資料(使用者點選、頁面訪問統計等等)。具體測試專案的資料量如下表所示:
SparkBench的研究方法
SparkBench基準測試通過每個測試專案指標的縱向對比,和多個測試專案指標的橫向對比,來發現不同工作負載的規律,目前版本研究的主要指標是:任務執行時間、資料處理速度和對資源的消耗情況。在未來的版本中會陸續加入其它方面的指標進行研究,包括shuffle資料量, 輸入輸出資料量等。
SparkBench測試環境
公開發布的結果是基於IBM SoftLayer雲端計算平臺的測試環境:總共11臺虛擬主機,每臺配置4核CPU,8GB的記憶體和2塊100GB的虛擬硬碟(一塊盤分配給HDFS,另一塊做為Spark本地快取使用),網路頻寬1Gbps。11臺虛擬主機中,只有1臺作為管理節點,剩下的10臺作為HDFS資料節點和Spark計算節點,每個Spark計算節點只設置1個executor並分配了6GB的最大記憶體。
可能會有人擔心虛擬機器測試結果會與物理環境測試結果相差過大,對於這一點論文指出,經過實際測試,在該虛擬環境中的測試結果與同等配置硬體環境的測試結果相比,相差不超過5%。
背景交代完畢,下面是最重要的內容:SparkBench測試結果及分析!
SparkBenc測結果和分析
任務執行時間對比
MapReduce作業分為Map和Reduce兩個階段,類似的Spark作業也可分為兩部分:ShuffleMapTask和ResultTask。前者由Spark DAG生成,會在不同節點間分發資料,產生一系列高代價的操作:IO、資料序列化、反序列化等。按這兩個階段(分別顯示為Shuffle Time和Regular Time)統計的執行時間佔比如下:
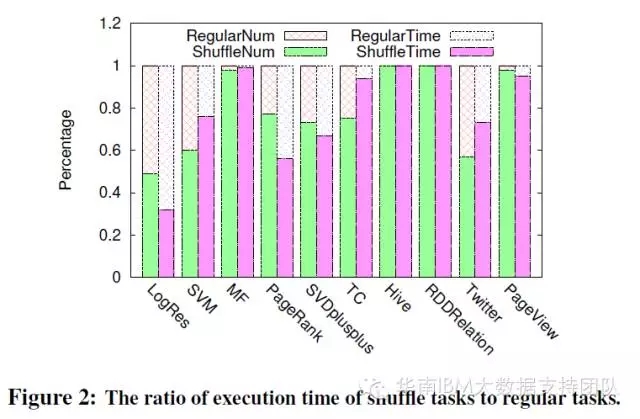
測試結果顯示,除了邏輯迴歸測試專案中ShuffleMapTasks階段執行時間佔比小於一半,其他測試專案都超了過50%,其中HIVE SQL/Spark SQL和矩陣分解演算法等這幾個測試的ShuffleMapTasks時間佔比接近100%! 論文中論述的原因是:SQL查詢及矩陣分解演算法都使用了大量的聚合和資料關聯操作(RDD或表),比如矩陣分解演算法中GroupBy操作就佔用了約98%的時間,這樣的操作會使Spark花費大量時間在不同Stage之間的協同和資料分發上。
測試專案的資源佔比分析
我們摘選幾個關鍵測試專案的測試結果呈現如下:
邏輯迴歸測試:對CPU和記憶體的佔用較為平均,分別為63%和5.2GB;對磁碟IO的佔用峰值出現在測試開始階段,後繼佔用逐漸減少。
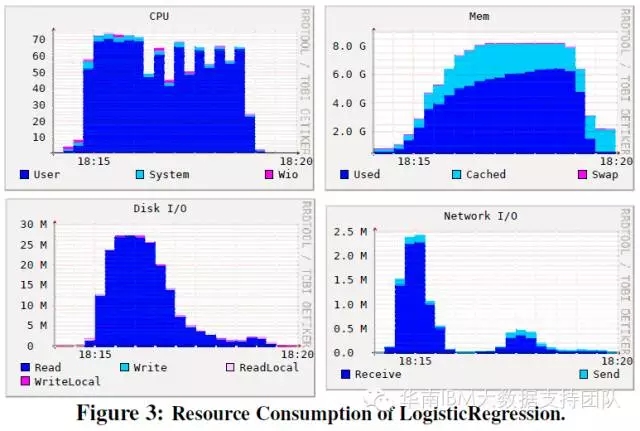
SVM測試專案:對CPU和IO的佔用具有雙峰的特點,分別在測試開始不久和測試結束前佔用較多CPU和IO資源。
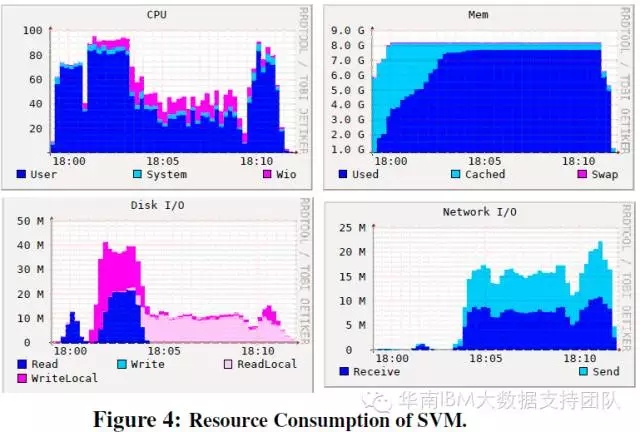
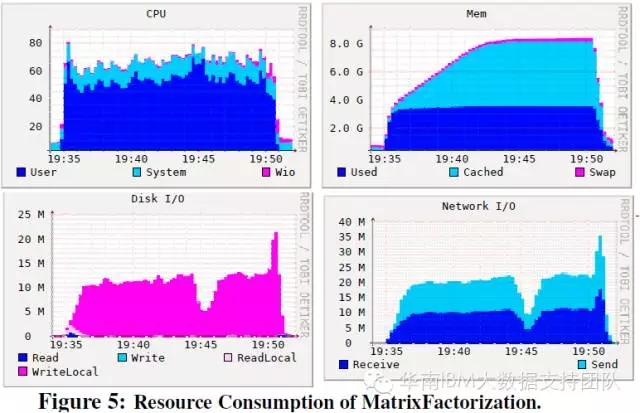
矩陣分解測試: 佔用較高CPU和記憶體,對磁碟IO的佔用特點是有大量的本地盤操作而不是HDFS操作,這是因為該工作負載產生大量的Shuffle資料,Shuffle是由本地盤的IO來完成的。
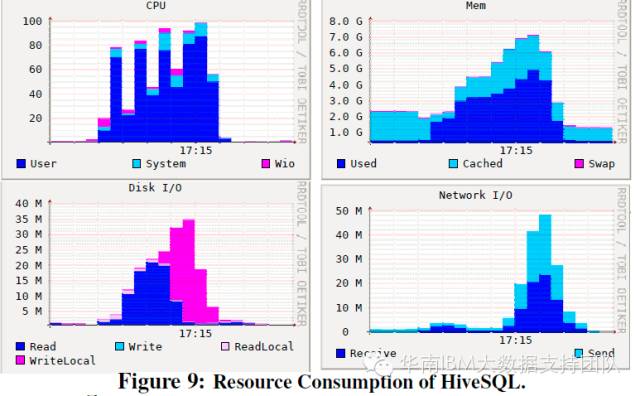
SQL查詢測試專案:HIVE SQL和Spark Native SQL對資源的佔用規律類似,都佔用了將近100%的資源! 這與SQL計算中有大量的資料表關聯有關。
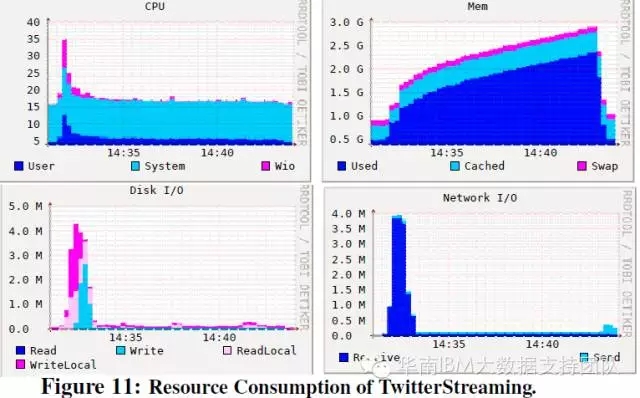
流計算測試專案:兩個流計算測試專案的資源佔用規律類似。與其他負載型別相比,除了記憶體佔用逐漸變大,對其他資源(CPU/IO/網路)的佔用率較低。
測試結果的指導意義
通過對四種工作負載、多個測試專案的結果分析,得到如下結論:
1. 記憶體資源對Spark尤為重要,因為所有型別的負載都需要在記憶體中儲存大量RDD資料,因此係統配置時需要優先配置記憶體;
2. 進行優化時,Shuffle的優化異常重要,大部分負載超過50%的執行時間都用在Shuffle上。
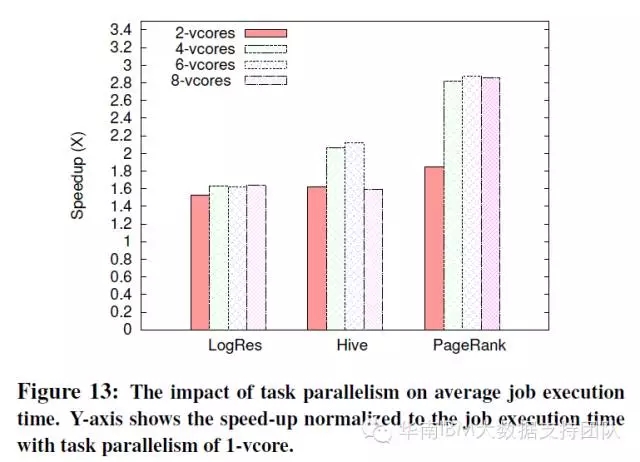
有趣!只增加CPU可能會降低效能
SparkBench測試還研究了增加CPU資源對負載效能的影響。測試中選用三種典型的負載(邏輯迴歸、PangeRank和Hive SQL),來研究線性增加CPU個數對任務執行時間的影響。
由於Spark中預設一個CPU Core分配一個Executor,只要系統CPU資源足夠多,Spark會啟動多個並行任務(Executor),因此增加CPU個數就是增加併發任務數量。而在現有環境中CPU核數從1增加到2,總體上都可以減少執行時間,成倍增加效率;但如果過度增加CPU可能不僅沒能改善,反而會降低效能,參見HiveSQL測試結果:
相關推薦
乾貨分享:SparkBench--Spark平臺的基準效能測試
SparkBench簡介 SparkBench是Spark的基準效能測試專案,由來自IBM Watson研究中心的五位研究者(Min Li, Jian Tan, Yandong Wang, Li Zhang, Valentina Salapura)發起,並貢獻至開源社群。
#Java乾貨分享:面試過程中經常碰到的9大難題解析
第一,談談final, finally, finalize的區別。 final?修飾符(關鍵字)如果一個類被宣告為final,意味著它不能再派生出新的子類,不能作為父類被繼承。因此一個類不能既被宣告為 abstract的,又被宣告為final的。將變數或方法宣告為final,可以保證它們在使用中
#乾貨分享:Java 的泛型擦除和執行時泛型資訊獲取
Java 的泛型擦除 程式設計師界有句流行的話,叫 talk is cheap, show me the code,所以話不多說,看程式碼。 如果有想學習java的程式設計師,可來我們的java學習扣qun:79979,2590免費送java的視訊教程噢!我整理了一份適合18年學習的java
#Java乾貨分享:如何用Java框架快速搭建web專案
1、 確定專案方向、架構,編制前端頁面,前端用到boostrap、jQuery、h5、js。 如果有想學習java的程式設計師,可來我們的java學習扣qun:79979,2590免費送java的視訊教程噢!我整理了一份適合18年學習的java乾貨,送給每一位想學的小夥伴,並且每天晚上8點還會在
#Java乾貨分享:一篇文章讓你深入瞭解Java中的包和介面
很多新手程式設計師對於Java中兩個具創新性的特徵————包與介面不是非常清楚,所以我特意發了這篇文章來闡述什麼是包,什麼是介面。 包(package)是多個類的容器,它們用於保持類的名稱空間相互隔離。 如果有想學習java的程式設計師,可來我們的java學習扣qun:79979,2590免
乾貨分享:Eclipse所有快捷鍵大合集,提升數倍工作效率
小編相信這裡有很多學習java的朋友,小編整理了一份java方面的學習資料,想要獲取的可以加我的java學習群的喲,928204055。歡迎愛學習Java的你們。 編輯 作用域 功能 快捷鍵 檢視 作用域 功能 快捷鍵 全域性 放大 C
#Java乾貨分享:兩分鐘瞭解日常程式設計中的小技巧,提高你的能力
1.return 一個空的集合,而不是 null 如果一個程式返回一個沒有任何值的集合,請確保一個空集合返回,而不是空元素。這樣你就不用去寫一大堆 ”if else” 判斷null元素。 如果有想學習java的程式設計師,可來我們的java學習扣qun:94311,1692免費送java的視
乾貨分享:智慧工廠時代下大資料 + 智慧的深度實踐
11 月 23 日,由七牛雲主辦的主題為「AI 產業技術的滲透與融合」的 NIUDAY 小牛匯共享日在北京舉行。會上,七牛雲技術總監陳超為大家帶來了題為《資料智慧時代的智慧工廠實踐》的內容分享。 以下是演講內容的實錄整理。 今天要介紹的是智慧工廠的相關內容。本次 NIUDAY
乾貨分享:從我的歷程談談該如何學習遊戲開發
01 好玩科技 耿宇篇 11月14號星期三農曆十月初七,手握滑鼠不慌張,本身就是一種力量。As the tree, so the fruit. 作者 | Ciel 來源 | 好玩科技 作為遊戲開發界的搬磚大師兄,我有責任和義務為後來者分享我的學習歷程和經驗
乾貨分享:vue2.0做移動端開發用到的相關外掛和經驗總結(2)
最近一直在做移動端微信公眾號專案的開發,也是我首次用vue來開發移動端專案,前期積累的移動端開發經驗較少。經過這個專案的鍛鍊,加深了對vue相關知識點的理解和運用,同時,在專案中所涉及到的微信api(微信分享,微信支付),百度地圖api(如何例項化地圖,給地圖新增自定義覆蓋物,給地圖新增自定義標註,對地圖進行
乾貨分享:vue2.0做移動端開發用到的相關外掛和經驗總結
最近一直在做移動端微信公眾號專案的開發,也是我首次用vue來開發移動端專案,前期積累的移動端開發經驗較少。經過這個專案的鍛鍊,加深了對vue相關知識點的理解和運用,同時,在專案中所涉及到的微信api(微信分享,微信支付),百度地圖api(如何例項化地圖,給地圖新增自
Java乾貨分享:10個非常有用的Java程式碼片段,記得收藏哦!
最近有粉絲私信我說,能不能分享一些技術型的乾貨,方便開發,於是我抽時間總結了一些經常會用帶的程式碼片段,分享給大家! 下面是10個非常有用的Java程式片段,希望能對你有用。 字串有整型的相互轉換 向檔案末尾新增內容 轉字串到日期 4.使用JDBC連結O
乾貨分享:十年大廠資深程式設計師的開發經驗總結
本文由騰訊雲加社群整理和釋出,原文連結:cloud.tencent.com/developer/article/1004735,內容有刪減和改動。 1、引言 在網際網路一線做了十年的程式開發,經歷了網易、百度、騰訊研究院、MIG 等幾個地方,陸續做過 3D 遊戲、2D 頁遊、瀏覽器、移動端翻
#Java乾貨分享:一分鐘明白基本資料型別與對應的包裝類
很多朋友在剛開始學習Java的時候,總是分不清資料型別、包裝類等等名詞,總是導致程式碼是對的,可是因為資料轉換出錯而執行錯誤,所以筆者特意針對一些初學者,列出了這兩者之間的異同之處。 Java語言提供了八種基本型別。六種數字型別(四個整數型,兩個浮點型),一種字元型別,還有一種布林型。&n
騰訊Bugly乾貨分享:Android機型適配之痛
一、個性化十足的Launcher 快捷方式雖然看起來只是一個很小的功能點,但是它涉及到的機型適配問題很多。 快捷方式建立程式碼: ntent addShortCut = new Intent("com.android.launcher.action.I
乾貨分享:清法網路分析小紅書內容運營那點事兒
有人說小紅書是“一夜爆紅”,其實不然。事實上,任何平臺的火爆都少不了長期的SEO優化。搜尋公關專家清法認為,雖然小紅書的成功大部分歸功於內容營銷,但是小紅書中的內容運營策略與SEO優化密不可分。一、使用者定位使用者定位是SEO優化過程中必不可少的步驟。我們建一個網站,要考慮使用者有哪些需求,再對使用者的需求進
乾貨分享:詳解執行緒的開始和建立
C#多執行緒之旅目錄: C#多執行緒之旅(5)——同步機制介紹 C#多執行緒之旅(6)——詳解多執行緒中的鎖 更多文章正在更新中,敬請期待...... C#多執行緒之旅(2)——建立和開始執行緒 程式碼下載 第一篇~第三篇的程式碼示例: 一、執行緒的建立和開始
從0到1:打造移動端H5效能測試平臺
如何打造一個移動端H5效能平臺?聽起來是否有點高大上,不知道如何下手。不要緊張,我們來手把手教大家打造自己的移動端H5效能測試平臺。 【H5前端效能平臺可以做什麼–功能篇】 以前我們要測試移動端H5效能,通常會用到遠端連線+抓包分析,工具諸如:fiddl
大數據知識點分享:大數據平臺應用 17 個知識點匯總
安全 完成 采集 資源 還需 不可 企業 數據緩存 實戰 一、大數據中的數據倉庫和Mpp數據庫如何選型? 在Hadoop平臺中,一般大家都把hive當做數據倉庫的一種選擇,而Mpp數據庫的典型代表就是impala,presto。Mpp架構的數據庫主要用於即席查詢場景,暨對數
乾貨分享:ASP.NET CORE(C#)與Spring Boot MVC(JAVA)異曲同工的程式設計方式總結
目錄 C# VS JAVA 基礎語法類比篇: 一、匿名類 二、型別初始化 三、委託(方法引用) 四、Lambda表示式 五、泛型 六、自動釋放