
機器學習實戰:k-臨近演算法(二)
海倫一直在使用線上約會網站尋找合適自己的約會物件,經過一番總結,海倫整理了以下資料,希望我們的分類軟體可以更好地幫助她將匹配物件劃分到確切的分類中
1、收集資料
40920 8.326976 0.953952 largeDoses 14488 7.153469 1.673904 smallDoses 26052 1.441871 0.805124 didntLike 75136 13.147394 0.428964 didntLike 38344 1.669788 0.134296 didntLike 72993 10.141740 1.032955 didntLike 35948 6.830792 1.213192 largeDoses 42666 13.276369 0.543880 largeDoses 67497 8.631577 0.749278 didntLike 35483 12.273169 1.508053 largeDoses 50242 3.723498 0.831917 didntLike 63275 8.385879 1.669485 didntLike 5569 4.875435 0.728658 smallDoses 51052 4.680098 0.625224 didntLike 77372 15.299570 0.331351 didntLike 43673 1.889461 0.191283 didntLike 61364 7.516754 1.269164 didntLike 69673 14.239195 0.261333 didntLike ......
第一列:每年獲得的飛行常客里程數
第二列:玩視訊遊戲所耗時間百分比
第三列:每週消費的冰淇淋公升數
第四列:海倫對資料的分類
largeDoses表示對海倫極具魅力的人
smallDoses表示對海倫魅力一般的人
didntlike表示海倫不喜歡的人
2、準備資料
(1)首先將分類的標籤轉為數字
largeDoses:用3表示
smallDoses:用2表示
didntlike:用1表示
新的資料如下:
40920 8.326976 0.953952 3 14488 7.153469 1.673904 2 26052 1.441871 0.805124 1 75136 13.147394 0.428964 1 38344 1.669788 0.134296 1 72993 10.141740 1.032955 1 35948 6.830792 1.213192 3 42666 13.276369 0.543880 3 67497 8.631577 0.749278 1 35483 12.273169 1.508053 3 50242 3.723498 0.831917 1 63275 8.385879 1.669485 1 5569 4.875435 0.728658 2 51052 4.680098 0.625224 1 77372 15.299570 0.331351 1 43673 1.889461 0.191283 1 61364 7.516754 1.269164 1 69673 14.239195 0.261333 1 ......
(2)用Python讀取檔案,將檔案中的內容轉為矩陣
測試:#將檔案轉為矩陣 def file2matrix(filename): fr=open(filename)#開啟檔案 arrayOLines=fr.readlines()#讀取整個檔案,分析成一個行的列表 numberOfLines=len(arrayOLines)#檔案行數 returnMat=zeros((numberOfLines,3))#建立len行3列的矩陣 classLabelVector=[]#定義儲存標籤的物件 index=0 #遍歷檔案每一行 for line in arrayOLines: line=line.strip()#擷取掉回車字元 listFromLine=line.split('\t')#根據\t tab將一行的內容分割 returnMat[index,:] = listFromLine[0:3]#選取分割後的前三個元素,returnMat[index,:]表示取得第index行的所有元素 classLabelVector.append(int(listFromLine[-1]))#向標籤列表中新增該條資料對應的分類 index += 1 return returnMat,classLabelVector data,label=file2matrix('datingTestSet2.txt') print(data) print(label)
[[ 4.09200000e+04 8.32697600e+00 9.53952000e-01]
[ 1.44880000e+04 7.15346900e+00 1.67390400e+00]
[ 2.60520000e+04 1.44187100e+00 8.05124000e-01]
...,
[ 2.65750000e+04 1.06501020e+01 8.66627000e-01]
[ 4.81110000e+04 9.13452800e+00 7.28045000e-01]
[ 4.37570000e+04 7.88260100e+00 1.33244600e+00]]
[3, 2, 1, 1, 1, 1, 3, 3, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1, 2, 3, 2, 1, 2, 3, 2, 3, 2, 3, 2, 1, 3, 1, 3, 1, 2, 1, 1, 2, 3, 3, 1, 2, 3, 3, 3, 1, 1, 1, 1, 2, 2, 1, 3, 2, 2, 2, 2, 3, 1, 2, 1, 2, 2, 2, 2, 2, 3, 2, 3, 1, 2, 3, 2, 2, 1, 3, 1, 1, 3, 3, 1, 2, 3, 1, 3, 1, 2, 2, 1, 1, 3, 3, 1, 2, 1, 3, 3, 2, 1, 1, 3, 1, 2, 3, 3, 2, 3, 3, 1, 2, 3, 2, 1, 3, 1, 2, 1, 1, 2, 3, 2, 3, 2, 3, 2, 1, 3, 3, 3, 1, 3, 2, 2, 3, 1, 3, 3, 3, 1, 3, 1, 1, 3, 3, 2, 3, 3, 1, 2, 3, 2, 2, 3, 3, 3, 1, 2, 2, 1, 1, 3, 2, 3, 3, 1, 2, 1, 3, 1, 2, 3, 2, 3, 1, 1, 1, 3, 2, 3, 1, 3, 2, 1, 3, 2, 2, 3, 2, 3, 2, 1, 1, 3, 1, 3, 2, 2, 2, 3, 2, 2, 1, 2, 2, 3, 1, 3, 3, 2, 1, 1, 1, 2, 1, 3, 3, 3, 3, 2, 1, 1, 1, 2, 3, 2, 1, 3, 1, 3, 2, 2, 3, 1, 3, 1, 1, 2, 1, 2, 2, 1, 3, 1, 3, 2, 3, 1, 2, 3, 1, 1, 1, 1, 2, 3, 2, 2, 3, 1, 2, 1, 1, 1, 3, 3, 2, 1, 1, 1, 2, 2, 3, 1, 1, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2, 3, 2, 3, 3, 3, 3, 1, 2, 3, 1, 1, 1, 3, 1, 3, 2, 2, 1, 3, 1, 3, 2, 2, 1, 2, 2, 3, 1, 3, 2, 1, 1, 3, 3, 2, 3, 3, 2, 3, 1, 3, 1, 3, 3, 1, 3, 2, 1, 3, 1, 3, 2, 1, 2, 2, 1, 3, 1, 1, 3, 3, 2, 2, 3, 1, 2, 3, 3, 2, 2, 1, 1, 1, 1, 3, 2, 1, 1, 3, 2, 1, 1, 3, 3, 3, 2, 3, 2, 1, 1, 1, 1, 1, 3, 2, 2, 1, 2, 1, 3, 2, 1, 3, 2, 1, 3, 1, 1, 3, 3, 3, 3, 2, 1, 1, 2, 1, 3, 3, 2, 1, 2, 3, 2, 1, 2, 2, 2, 1, 1, 3, 1, 1, 2, 3, 1, 1, 2, 3, 1, 3, 1, 1, 2, 2, 1, 2, 2, 2, 3, 1, 1, 1, 3, 1, 3, 1, 3, 3, 1, 1, 1, 3, 2, 3, 3, 2, 2, 1, 1, 1, 2, 1, 2, 2, 3, 3, 3, 1, 1, 3, 3, 2, 3, 3, 2, 3, 3, 3, 2, 3, 3, 1, 2, 3, 2, 1, 1, 1, 1, 3, 3, 3, 3, 2, 1, 1, 1, 1, 3, 1, 1, 2, 1, 1, 2, 3, 2, 1, 2, 2, 2, 3, 2, 1, 3, 2, 3, 2, 3, 2, 1, 1, 2, 3, 1, 3, 3, 3, 1, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 3, 2, 1, 3, 3, 2, 2, 2, 3, 1, 2, 1, 1, 3, 2, 3, 2, 3, 2, 3, 3, 2, 2, 1, 3, 1, 2, 1, 3, 1, 1, 1, 3, 1, 1, 3, 3, 2, 2, 1, 3, 1, 1, 3, 2, 3, 1, 1, 3, 1, 3, 3, 1, 2, 3, 1, 3, 1, 1, 2, 1, 3, 1, 1, 1, 1, 2, 1, 3, 1, 2, 1, 3, 1, 3, 1, 1, 2, 2, 2, 3, 2, 2, 1, 2, 3, 3, 2, 3, 3, 3, 2, 3, 3, 1, 3, 2, 3, 2, 1, 2, 1, 1, 1, 2, 3, 2, 2, 1, 2, 2, 1, 3, 1, 3, 3, 3, 2, 2, 3, 3, 1, 2, 2, 2, 3, 1, 2, 1, 3, 1, 2, 3, 1, 1, 1, 2, 2, 3, 1, 3, 1, 1, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 2, 2, 2, 3, 1, 3, 1, 2, 3, 2, 2, 3, 1, 2, 3, 2, 3, 1, 2, 2, 3, 1, 1, 1, 2, 2, 1, 1, 2, 1, 2, 1, 2, 3, 2, 1, 3, 3, 3, 1, 1, 3, 1, 2, 3, 3, 2, 2, 2, 1, 2, 3, 2, 2, 3, 2, 2, 2, 3, 3, 2, 1, 3, 2, 1, 3, 3, 1, 2, 3, 2, 1, 3, 3, 3, 1, 2, 2, 2, 3, 2, 3, 3, 1, 2, 1, 1, 2, 1, 3, 1, 2, 2, 1, 3, 2, 1, 3, 3, 2, 2, 2, 1, 2, 2, 1, 3, 1, 3, 1, 3, 3, 1, 1, 2, 3, 2, 2, 3, 1, 1, 1, 1, 3, 2, 2, 1, 3, 1, 2, 3, 1, 3, 1, 3, 1, 1, 3, 2, 3, 1, 1, 3, 3, 3, 3, 1, 3, 2, 2, 1, 1, 3, 3, 2, 2, 2, 1, 2, 1, 2, 1, 3, 2, 1, 2, 2, 3, 1, 2, 2, 2, 3, 2, 1, 2, 1, 2, 3, 3, 2, 3, 1, 1, 3, 3, 1, 2, 2, 2, 2, 2, 2, 1, 3, 3, 3, 3, 3, 1, 1, 3, 2, 1, 2, 1, 2, 2, 3, 2, 2, 2, 3, 1, 2, 1, 2, 2, 1, 1, 2, 3, 3, 1, 1, 1, 1, 3, 3, 3, 3, 3, 3, 1, 3, 3, 2, 3, 2, 3, 3, 2, 2, 1, 1, 1, 3, 3, 1, 1, 1, 3, 3, 2, 1, 2, 1, 1, 2, 2, 1, 1, 1, 3, 1, 1, 2, 3, 2, 2, 1, 3, 1, 2, 3, 1, 2, 2, 2, 2, 3, 2, 3, 3, 1, 2, 1, 2, 3, 1, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2, 2, 2, 2, 2, 1, 3, 3, 3](1)使用Matplotlib建立散點圖
匯入matplotlib
# -*- coding:utf-8 -*-
from numpy import *
import operator
import matplotlib
import matplotlib.pyplot as plt
#將檔案轉為矩陣
def file2matrix(filename):
fr=open(filename)#開啟檔案
arrayOLines=fr.readlines()#讀取整個檔案,分析成一個行的列表
numberOfLines=len(arrayOLines)#檔案行數
returnMat=zeros((numberOfLines,3))#建立len行3列的矩陣
classLabelVector=[]#定義儲存標籤的物件
index=0
#遍歷檔案每一行
for line in arrayOLines:
line=line.strip()#擷取掉回車字元
listFromLine=line.split('\t')#根據\t tab將一行的內容分割
returnMat[index,:] = listFromLine[0:3]#選取分割後的前三個元素,returnMat[index,:]表示取得第index行的所有元素
classLabelVector.append(int(listFromLine[-1]))#向標籤列表中新增該條資料對應的分類
index += 1
return returnMat,classLabelVector
data,label=file2matrix('datingTestSet2.txt')
#畫散點圖
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(data[:,1],data[:,2])#選擇資料集的第二列(玩遊戲所佔時間比)的值作為x軸,第三列(冰淇淋公升數)的值作為y軸
plt.show()#顯示散點圖
從散點圖上看不出什麼有用的資訊,所以我們來改一下程式:
#第一個引數:選擇資料集的第二列(玩遊戲所佔時間比)的值作為x軸
#第二個引數:第三列(冰淇淋公升數)的值作為y軸
#第三個引數和第四個引數:代表顏色和大小同時放大15倍,這時,同一類標籤顏色和大小相同
ax.scatter(data[:,1],data[:,2],15.0*array(label),15.0*array(label))此時散點圖:
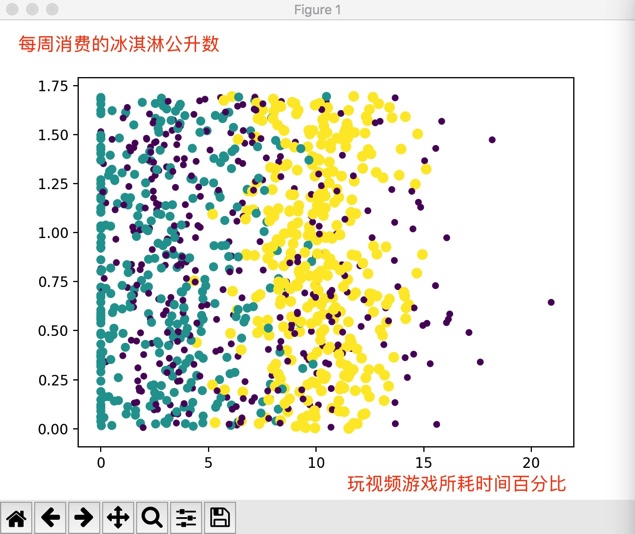
從圖中可以看出資料已經和對應的分類標籤掛鉤,基本上可以看到資料點所屬三個樣本分類的區域輪廓,綠色、黃色、重紫色(就這麼叫吧)分別代表了不同的分類,同一分類下的點大小和顏色都相同。
下面將飛行常客旅行數作為x軸資料,玩視訊遊戲所耗時間百分比作為y軸資料來看一下散點圖的情況:
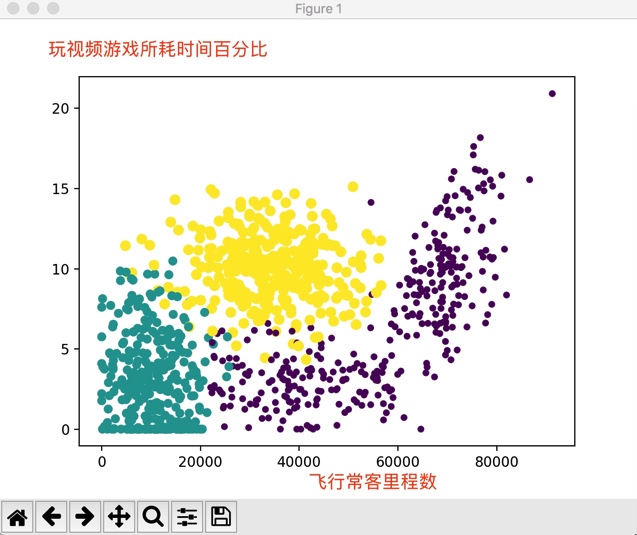
此圖清晰的標識了三個不同的樣本分類區域,更容易區分資料點從屬的類別。
4、歸一化數值
(1)取一些樣本資料

假如想計算樣本三和樣本4之間的距離,需要使用如下的方法:
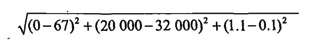
從方程中很容易發現,數字差值最大的屬性對計算結果影響最大,也就是飛行常客里程數對於計算結果的影響將遠遠大於玩視訊遊戲所佔時間比和每週消費冰淇淋公升數這兩個特徵,原因是飛行常客旅程數的數值遠大於其他特徵值的值,但是海倫認為這三種特徵是同等重要的,飛行常客里程數不應該如此嚴重的影響到計算結果。
處理這種不同取值範圍的特徵值時,通常採用的辦法是將數值歸一化,比如將數值的範圍處理為0到1之間的值。下面的公式可以將取值範圍轉換到0和1之間:
newValue=(oldValue-min)/(max-min)
max:資料集中最大特徵值
min:資料集中最小特徵值
下面定義一個函式,對資料進行歸一化處理:
#歸一化
def autoNorm(dataSet):
minVals=dataSet.min(0)#獲取每一列的最小值
maxVals=dataSet.max(0)#獲取每一列的最大值
ranges=maxVals-minVals#max-min差值
normDataSet=zeros(shape(dataSet))#zeros函式用來建立給定的矩陣型別,並初始化為0
m=dataSet.shape[0]#獲取資料集行數
normDataSet=dataSet-tile(minVals,(m,1))#將minVals為變為m行的矩陣(oldValue-min)
normDataSet=normDataSet/tile(ranges,(m,1))#將ranges變為m行的矩陣(oldValue-min)/(max-min)
return normDataSet,ranges,minVals每一列的最小值:minVals=[ 0. 0. 0.001156]
每一列的最大值:maxVals=[ 9.12730000e+04 2.09193490e+01 1.69551700e+00]
max-min對應的是ranges
由於minVals是一行三列的矩陣,為了便於相減,使用tile函式將minVals變為m行三列的矩陣,m為資料集的行數
同樣的辦法將ranges變為m行三列的矩陣,便於相除
來自:機器學習實戰
Python知識參考:
相關推薦
機器學習實戰:k-臨近演算法(二)
海倫一直在使用線上約會網站尋找合適自己的約會物件,經過一番總結,海倫整理了以下資料,希望我們的分類軟體可以更好地幫助她將匹配物件劃分到確切的分類中 1、收集資料 40920 8.326976 0.953952 largeDoses 14488 7.153469 1.673
機器學習實戰之k-近鄰演算法(3)---如何視覺化資料
關於視覺化: 《機器學習實戰》書中的一個小錯誤,P22的datingTestSet.txt這個檔案,根據網上的原始碼,應該選擇datingTestSet2.txt這個檔案。主要的區別是最後的標籤,作者原來使用字串‘veryLike’作為標籤,但是Python轉換會出現Val
機器學習實戰之k-近鄰演算法(4)--- 如何歸一化資料
歸一化的公式: newValue = (oldValue - min) / (max - min) 就是把資料歸一化到[0, 1]區間上。 好處: 防止某一維度的資料的數值大小對距離就算產生影響。多個維度的特徵是等權重的,所以不能被數值大小影響。 下面是歸一化特徵值的程式碼
機器學習實戰:K近鄰演算法--學習筆記
一、KNN的工作原理 假設有一個帶有標籤的樣本資料集(訓練樣本集),其中包含每條資料與所屬分類的對應關係。 輸入沒有標籤的新資料後,將新資料的每個特徵與樣本集中資料對應的特徵進行比較。 1) 計算新資料與樣本資料集中每條資料的距離。 2) 對求得的所有距離進
《機器學習實戰》Logistic迴歸演算法(1)
-0.017612 14.053064 0 -1.395634 4.662541 1 -0.752157 6.5386200 -1.322371 7.152853 0 0.42336311.054677 0 0.406704 7.067335 1 0
《機器學習實戰》第二章:k-近鄰演算法(3)手寫數字識別
這是k-近鄰演算法的最後一個例子——手寫數字識別! 怎樣?是不是聽起來很高大上? 呵呵。然而這跟影象識別沒有半毛錢的關係 因為每個資料樣本並不是手寫數字的圖片,而是有由0和1組成的文字檔案,就像這樣: 嗯,這個資料集中的每一個樣本用圖形軟體處理過,變成了寬高
《機器學習實戰》第二章:k-近鄰演算法(1)簡單KNN
收拾下心情,繼續上路。 最近開始看Peter Harrington的《Machine Learning in Action》... 的中文版《機器學習實戰》。準備在部落格裡面記錄些筆記。 這本書附帶的程式碼和資料及可以在這裡找到。 這本書裡程式碼基本是用python寫的
《機器學習實戰》第二章:k-近鄰演算法(2)約會物件分類
這是KNN的一個新例子。 在一個約會網站裡,每個約會物件有三個特徵: (1)每年獲得的飛行常客里程數(額...這個用來判斷你是不是成功人士?) (2)玩視訊遊戲所耗時間百分比(額...這個用來判斷你是不是肥宅?) (3)每週消費的冰激凌公升數(額...這個是何用意我真不知道
機器學習實戰(Machine Learning in Action)學習筆記————02.k-鄰近演算法(KNN)
機器學習實戰(Machine Learning in Action)學習筆記————02.k-鄰近演算法(KNN)關鍵字:鄰近演算法(kNN: k Nearest Neighbors)、python、原始碼解析、測試作者:米倉山下時間:2018-10-21機器學習實戰(Machine Learning in
《機器學習實戰》二分-kMeans演算法(二分K均值聚類)
首先二分-K均值是為了解決k-均值的使用者自定義輸入簇值k所延伸出來的自己判斷k數目,其基本思路是: 為了得到k個簇,將所有點的集合分裂成兩個簇,從這些簇中選取一個繼續分裂,如此下去,直到產生k個簇。 虛擬碼: 初始化簇表,使之包含由所有的點組成的簇。 repeat &n
機器學習筆記九:K近鄰演算法(KNN)
一.基本思想 K近鄰演算法,即是給定一個訓練資料集,對新的輸入例項,在訓練資料集中找到與該例項最鄰近的K個例項,這K個例項的多數屬於某個類,就把該輸入例項分類到這個類中。如下面的圖: 通俗一點來說,就是找最“鄰近”的夥伴,通過這些夥伴的類別來看自己的類別
機器學習實戰:K-均值及二分K-均值聚類演算法
# coding=utf-8 ''' Created on Feb 16, 2011 k Means Clustering for Ch10 of Machine Learning in Action #@author: Peter Harrington ''' from
機器學習系列:k 近鄰法(k-NN)的原理及實現
本內容將介紹機器學習中的 k k k 近鄰法(
機器學習之K-近鄰演算法(二)
本章內容: K-近鄰分類演算法 從文字檔案中解析和匯入資料 使用matplotlib建立擴散圖 歸一化數值 2-1 K-近鄰演算法概述 簡單的說,K-近鄰演算法採用測量不同特徵值之間的距離方法進行分類。 K-近鄰演算法 優點:精度高、對異常
機器學習實戰筆記-K近鄰演算法2(改進約會網站的配對效果)
案例二.:使用K-近鄰演算法改進約會網站的配對效果 案例分析: 海倫收集的資料集有三類特徵,分別是每年獲得的飛行常客里程數、玩視訊遊戲所耗時間百分比、 每週消費的冰淇淋公升數。我們需要將新資
《機器學習實戰》——k-近鄰演算法Python實現問題記錄
《機器學習實戰》第二章k-近鄰演算法,自己實現時遇到的問題,以及解決方法。做個記錄。 1.寫一個kNN.py儲存了之後,需要重新匯入這個kNN模組。報錯:no module named kNN. 解決方法:1.將.py檔案放到 site_packages 目錄下
機器學習系列之K-近鄰演算法(監督學習-分類問題)
''' @description : 演算法優點: a簡單、易於理解、易於實現、無需估計引數、無需訓練 演算法缺點: a懶惰演算法,對測試樣本分類時計算量大,記憶體開銷大 b必須制定k值,k值得選擇
機器學習實戰之K-近鄰演算法總結和程式碼解析
機器學習實戰是入手機器學習和python實戰的比較好的書,可惜我現在才開始練習程式碼!先宣告:本人菜鳥一枚,機器學習的理論知識剛看了一部分,python的知識也沒學很多,所以寫程式碼除錯的過程很痛可!但是還是挨個找出了問題所在,蠻開心的!看了很多大牛
py2.7 : 《機器學習實戰》 k-近鄰演算法 11.19 更新完畢
主要有幾個總結的: 1.python支援檔案模組化,所以在同一個目錄下import就可以呼叫了; 2.中文註釋要加上 # -*- coding: utf-8 -*- 3.import numpy 和 from numpy import * 區別是, 對於前者,呼叫的時候需要
Python機器學習筆記:線性判別分析(LDA)演算法
預備知識 首先學習兩個概念: 線性分類:指存在一個線性方程可以把待分類資料分開,或者說用一個超平面能將正負樣本區分開,表示式為y=wx,這裡先說一下超平面,對於二維的情況,可以理解為一條直線,如一次函式。它的分類演算法是基於一個線性的預測函式,決策的邊界是平的,比如直線和平面。一般的方法有感知器,最小