
Python機器學習筆記:線性判別分析(LDA)演算法
預備知識
首先學習兩個概念:
線性分類:指存在一個線性方程可以把待分類資料分開,或者說用一個超平面能將正負樣本區分開,表示式為y=wx,這裡先說一下超平面,對於二維的情況,可以理解為一條直線,如一次函式。它的分類演算法是基於一個線性的預測函式,決策的邊界是平的,比如直線和平面。一般的方法有感知器,最小二乘法。
非線性分類:指不存在一個線性分類方程把資料分開,它的分類介面沒有限制,可以是一個曲面,或者是多個超平面的組合。
LDA在模式識別領域(比如人臉識別,艦艇識別等圖形影象識別領域)中有非常廣泛的應用,因此我們有必要了解一下它的演算法原理。不過在學習LDA之前,我們有必要將其與自然語言處理領域中的LDA區分開,在自然語言處理領域,LDA是隱含狄利克雷分佈(Latent DIrichlet Allocation,簡稱LDA),它是一種處理文件的主題模型,我們本文討論的是線性判別分析,因此後面所說的LDA均為線性判別分析。
那麼為什麼要用LDA呢?
1,為什麼要學習LDA演算法?
前面部落格學了PCA降維,部落格地址如下:
Python機器學習筆記:主成分分析(PCA)演算法
PCA是一種無監督的資料降維方法,與之不同的是:LDA是一種有監督的資料降維方法。我們知道即使在訓練樣本上,我們提供了類別標籤,在使用PCA模型的時候,我們是不利於類別標籤的,而LDA在進行資料降維的時候是利用資料的類別標籤提供的資訊的。
從幾何的角度來看,PCA和LDA都是將資料投影到新的相互正交的座標軸上。只不過在投影的過程中他們使用的約束是不同的,也可以說目標是不同的。PCA是將資料投影到方差最大的幾個相互正交的方向上,以期待保留最多的樣本資訊。樣本的方差越大表示樣本的多樣性越好,在訓練模型的時候,我們當然希望資料的差別越大越好。否則即使樣本很多但是他們彼此相似或者相同,提供的樣本資訊將相同,相當於只有很少的樣本提供資訊是有用的。樣本資訊不足將導致模型效能不夠理想。這就是PCA降維的目的:將資料投影到方差最大的幾個相互正交的方向上。這種約束有時候很有用,比如在下面這個例子:
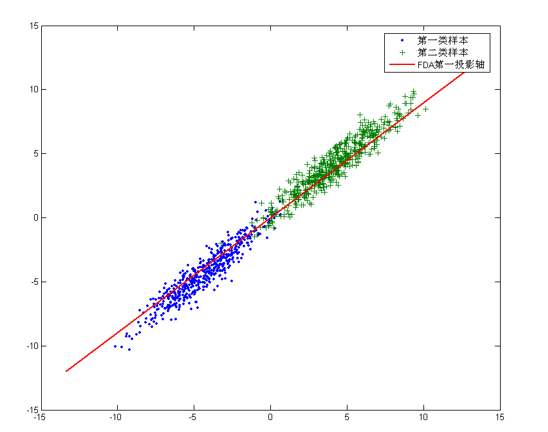
對於這個樣本集我們可以將資料投影到 x 軸或者 y 軸,但這都不是最佳的投影方向,因為這兩個方向都不能最好的反映資料的分佈。很明顯還存在最佳的方向可以描述資料的分佈趨勢,那就是圖中紅色直線所在的方向。也是資料樣本作投影,方差最大的方向。向這個方向做投影,投影后資料的方差最大,資料保留的資訊最多。
但是,對於另外的一些不同分佈的資料集,PCA的這個投影后方差最大的目標就不太適合了。比如對於下面圖片中的資料集:
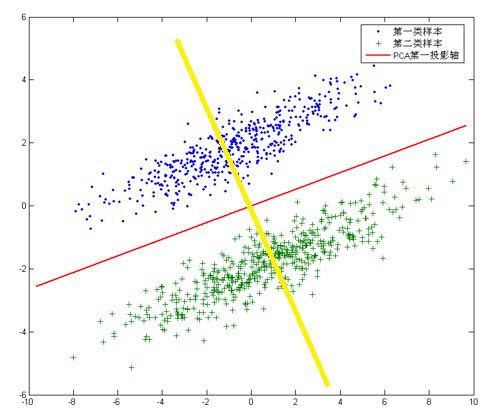
針對這個資料集,如果同樣選擇使用PCA,選擇方差最大的方向作為投影方向,來對資料進行降維。那麼PCA選出的最佳投影方向,將是圖中紅色直線所示的方向。這樣做投影確實方差最大,但是是不是有其他問題。聰明的你發現了,這樣做投影之後兩類資料樣本將混合在一起,將不再線性可分,甚至是不可分的。這對我們來說簡直是地獄,本來線性可分的樣本被我們親手變得不再可分。而我們發現,如果使用圖中黃色直線,向這條直線做投影即能使資料降維,同時還能保證兩類資料仍然是線性可分的。上面的這個資料集如果使用LDA降維,找出的投影方向就是黃色直線所在的方向。
這其實就是LDA的思想,或者說LDA降維的目標:將帶有標籤的資料降維,投影到低維空間同時滿足三個條件:
- 1,儘可能多的保留資料樣本的資訊(即選擇最大的特徵是對應的特徵向量所代表的方向)。
- 2,尋找使樣本儘可能好分的最佳投影方向。
- 3,投影后使得同類樣本儘可能近,不同類樣本儘可能遠。


2,LDA的思想
LDA的核心思想:類內小,類間大
線性判別分析(Linear Discriminant Analysis, 以下簡稱LDA)是一種監督學習的降維技術,也就是說它的資料集的每個樣本是有類別輸出的。這點和PCA不同,PCA是不考慮樣本類別輸出的無監督降維技術。LDA的思想可以用一句話概述,就是“投影后類內方差最小,類間方差最大”,什麼意思呢?我們要將資料在低維度上進行投影,投影后希望每一種類別資料的投影點儘可能的接近,而不同類別的資料的類別中心之間的距離儘可能的大。
可能這句話有點抽象,那我們先看看最簡單的情況。假設我們有兩類資料分別是紅色和藍色,如下圖所示,這些資料特徵是二維的,我們希望將這些資料投影到一維的一條直線,讓每一種類別資料的投影點儘可能的接近,而紅色和藍色資料中心之間的距離儘可能的大。
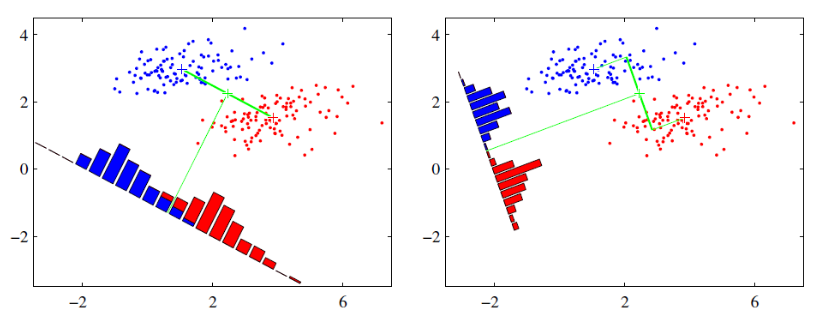
上圖中提供了兩種投影方式,哪一種能更好的滿足我們的標準呢?從直觀上看出,右邊要比左邊圖的投影效果好,因為右邊圖的紅色資料進而藍色資料各個較為集中,且類別之間的距離明顯,左邊的則在邊界處資料混雜。以上就是LDA的主要思想了,當然在實際應用中,我們的資料是多個類別的,我們的原始資料一般也是超過二維的,投影后的也一般不是直線,而是一個低維的超平面。
周志華老師的《機器學習》一書中,已有簡述線性判別分析的中心思想,其實這可以聯想到方差分析中的組內偏差SSE和組間偏差SSA,畢竟Fisher線性判別分析和方差分析的發明者都是R.A.Fisher。
Fisher判別分析的思想非常樸素:給定訓練樣本例集,設法將樣例投影到一條直線上,使得同類樣例的投影點儘可能接近,不同類樣例的投影點儘可能遠離。在對新樣本進行分類時,將其投影到同樣的這條直線上,再根據新樣本投影點的位置來確定它的類別。
3,LDA演算法的優化目標(周志華老師的推導過程)
LDA的原理:投影到維度更低的空間中,使得投影后的點,會形成按類別區分,一簇一簇的情況,相同類別的點,將會在投影后的空間中更接近方法。
下圖來自周志華《機器學習》,給出了一個二維示意圖:
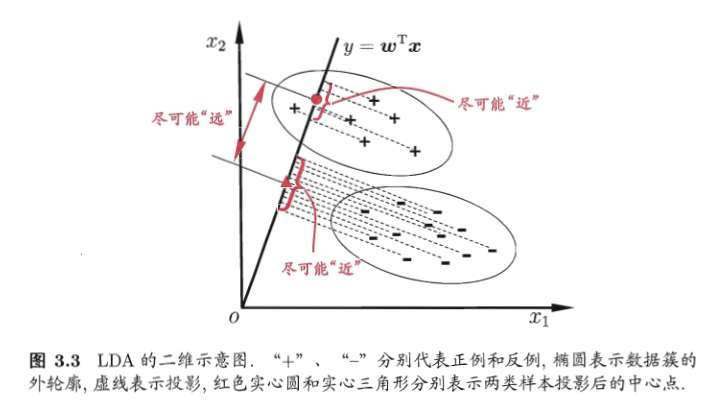
什麼是線性判別分析呢?所謂的線性就是,我們要將資料點投影到直線上(可能是多條直線),直線的函式解析式又稱為線性函式,通常直線的表示式為:

其實這裡的 x 就是樣本向量(列向量),如果投影到一條直線上 w 就是一個特徵向量(列向量形式)或者多個特徵向量構成的矩陣。至於 w 為什麼是特徵向量,後面我們就能推匯出來。 y 為投影后的樣本點(列向量)。
我們首先使用兩類樣本來說明,然後再推廣到多類問題。這裡簡單的學習一下(後面會學習詳細推導過程)。
將資料投影到直線 w 上,則兩類樣本的中心在直線上的投影分別為 WTμ0,WTμ1,若將所有的樣本點都投影到直線上,則兩類樣本的協方差分別為 WT∑0 W 和 WT∑1W。
投影后同類樣本協方差矩陣的求法:
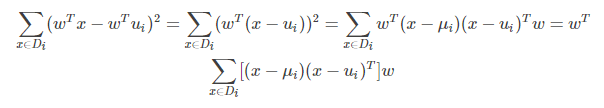
上式的中間部分(即第二行的式子)就是同類樣本投影前的協方差矩陣。還可以看出同類樣本投影前後協方差矩陣之間的關係。如果投影前的協方差矩陣為 ∑ 則投影后的為 WT∑ W。
上式的推導需要用到如下公式,a,b都是列向量:
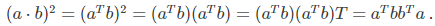
欲使同類樣例的投影點儘可能接近,可以讓同類樣本點的協方差矩陣儘可能小,即下面式子儘可能小:
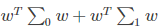
欲使異類樣例的投影點儘可能遠離,可以讓類中心之間的距離儘可能大,即下面式子儘可能大:
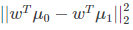
同時考慮二者,則可得到最大化的目標
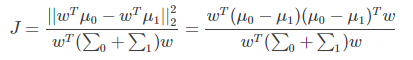
上式 ||*|| 表示歐幾里得範數,其中:
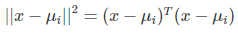
3.1 對上面推導關鍵點的理解
上面說的同類樣本點的協方差矩陣儘可能小,同類樣例的投影點就儘可能接近,這句話如何理解呢?
我們在最初接觸協方差是用來表示兩個變數的相關性,我們來看一下協方差和方差的公式:
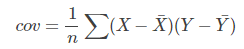
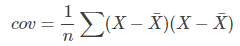
可以看到協方差的公式和方差十分相近,甚至可以說方差是協方差的一種特例。我們知道方差可以用來度量資料的離散程度,(X - Xhat)越大,表示資料距離樣本中心越遠,資料越離散,資料的方差越大。同樣我們觀察,協方差的公式,(X - Xhat)和(Y - Yhat)越大,表示資料距離樣本中心越遠,資料分佈越分散,協方差越大。相反他們越小表示資料距離樣本中心越近,資料分佈越集中,協方差越小。
所以協方差不僅是反映了變數之間的相關性,同樣反映了多維樣本分佈的離散程度(一維樣本使用方差),協方差越大(對於負相關來說是絕對值越大),表示資料的分佈越分散。所以上面的“欲使同類樣例的投影點儘可能接近,可以讓同類樣本點的協方差矩陣儘可能小”就可以理解了。
要是還不能理解,我們這裡再分析一波。
首先LDA分類的一個目標是使得不同類別之間的距離越遠越好,同一類別之中的距離越近越好。那麼不同類別之間的距離越遠越好,我們是可以理解的,就是越遠越好區分。
比如每類樣例的均值為:
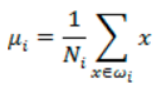
而投影后的均值為:
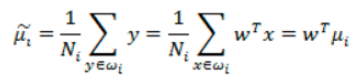
那投影后的兩類樣本中心點儘量分離:
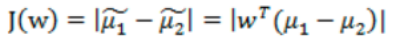
那是不是說我們只最大化J(w) 就可以了?
實際情況當然不是,比如下面情況:

我們發現,對上圖來說,假設我們只有兩種分類方向,一種是X1方向,一種是 X2方向。
我們看到X1的方向可以最大化J(w)的值,但是卻分的不好,μ1 和 μ2 兩個資料集之間還有交叉。但是X2方向,雖然不會最大化J(w)的值,但是卻分的好。。。。
基於這個問題,我們提出了雜湊值(也就是樣本點的密集程度),當雜湊值越大,越分散,反之越集中。
我們肯定是希望同類之間應該更密集些,表示如下:
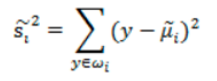
所以,總結來說,就是我們希望不同類樣本中心值儘量越分散越好,也就是J(w) 越大越好,而同類之間距離越小越好,也就是雜湊值之和越小越好。我們最終還是希望J(w)越大越好,所以我們可以將公式寫成下面方式,基於此,我們得到目標函式為:
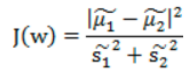
分子展示如下(其中SB稱為類間散佈矩陣):
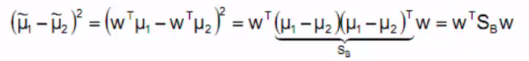
雜湊值公式展示:

雜湊矩陣(scatter matrices):

類間散佈矩陣:

其中:
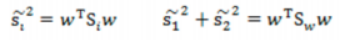
最終目標函式為:
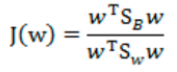
4,瑞利商(Rayleigh quotient)與廣義瑞利商(genralized Rayleigh quotient)
我們首先來看看瑞利商的定義。瑞利商是指這樣的函式R(A, x):
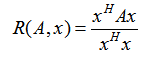
其中 x 為非零向量,而A為 n*n 的Hermitan矩陣。所謂的 Hermitan矩陣就是滿足共軛轉置矩陣和自己相等的矩陣,即AH=A。如果我們的矩陣A是實矩陣,則滿足 AH=A 的矩陣即為Hermitan矩陣。
瑞利商R(A, x) 有一個非常重要的性質,即它的最大值等於矩陣A最大的特徵值,而最小值等於矩陣A的最小的特徵值,也就是滿足:
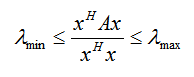
具體的證明這裡不給出了,當向量 x 是標準正交基時,即滿足xHx = 1時,瑞利商退化為:R(A, x) =xHAx,這個形式在譜聚類和PCA中都有出現。
以上就是瑞利商的內容,現在我們看看廣義瑞利商。廣義瑞利商是指這樣的函式 R(A, B, x):
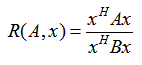
其中 x 為非零向量,而A, B為 n*n 的Hermitan矩陣。B為正定矩陣。它的最大值和最小值是什麼呢?其實我們只要通過標準化就可以轉化為瑞利商的格式。我們令 x = B-1/2x',則分母轉化為:

而分子轉化為:

此時我們的 R(A, B, x) 轉化為 R(A, B, x'):
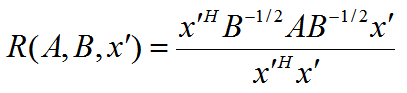
利用前面的瑞利商的性質,我們可以很快的知道,R(A, B, x')的最大值為矩陣 B-1/2AB-1/2的最大特徵值,或者說矩陣 B-1A 的最大特徵值,而最小值為矩陣 B-1A 的最小特徵值(這裡使用了一個技巧,即對矩陣進行標準化)。
5,二類LDA原理
現在我們回到LDA的原理上,我們在上面說到了LDA希望投影后希望同一種類別數據的投影點儘可能的接近,而不同類別的資料的類別中心之間的距離儘可能的大,但是這只是一個感官的度量。現在我們首先從比較簡單的二類LDA入手,嚴謹的分析LDA的原理。
LDA的原理:投影到維度更低的空間中,使得投影后的點,會形成按類別區分,一簇一簇的情況,相同類別的點,將會在投影后的空間中更接近方法。

假設我們的資料集 D={(x1, y1), (x2, y2), .... (xm, ym)},其中任意樣本 xi 為n維向量,yi屬於{0, 1}。我們定義 Nj(j=0, 1)為第 j 類樣本的個數,Xj(j = 0, 1)為第 j 類 樣本的集合,而 μj(j=0, 1)為第 j 類樣本的均值向量,定義 Σj(j=0, 1) 為第 j 類樣本的協方差矩陣(嚴格說是缺少分母部分的協方差矩陣)。
μj 的表示式為:
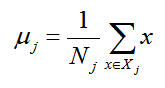
其中 j = 0, 1
Σj的表示式為:
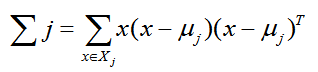
由於是兩類資料,因此我們只需要將資料投影到一條直線上即可。假設我們的投影直線是向量 w,則對任意一個樣本 xi,它在直線 w 上的投影為 wTxi,對於我們的兩個類別的中心點 μ0, μ1,在直線 w 的投影為 wTμ0,wTμ1。由於LDA需要讓不同類別的資料的類別中心之間的距離儘可能的大,也就是我們要最大化 ||wTμ0 - wTμ1||22 ,同時我們希望同一種類別數據的投影點儘可能的接近,也就是要同類樣本投影點的協方差 wT Σ0 w 和 wT Σ1w 儘可能的小,即最小化 wT Σ0 w + wT Σ1w 。綜上所述,我們的優化目標為:

類內散度矩陣
我們一般定義類內散度矩陣 Sw為:
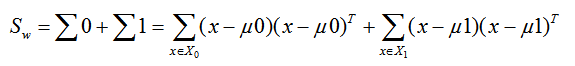
類間散度矩陣
類間散度矩陣其實就是協方差矩陣乘以樣本數目,即散度矩陣與協方差矩陣只是相差一個係數。
同時定義類間散度矩陣 Sb為:
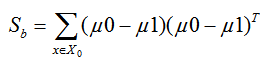
定義過類內散度矩陣和類間散度矩陣後,我們就可以將上述的優化目標重寫為:

仔細一看上式,就是我們的廣義瑞利商嘛!利用我們提到的廣義瑞利商的性質,我們知道我們的 J(w') 最大值為矩陣 Sw-1/2SbSw-1/2 的最大特徵值,而對應的w' 為 Sw-1/2SbSw-1/2 的最大特徵值對應的特徵向量!,而Sw-1/2Sb 的最大特徵值對應的特徵向量!,而Sw-1Sb 的特徵值和 Sw-1/2SbSw-1/2 的特徵值相同, Sw-1Sb 的特徵向量 w' 滿足 w=Sw-1/2w'的關係。
注意到對於二類的時候,Sbw 的方向恆平行於 μ0 - μ1,不妨令 Sbw = λ( μ0 - μ1),將其代入:(Sw-1Sb)w = λ w,可以得到 w = Sw-1( μ0 - μ1),也就是我們只要求出原始二類樣本的均值和方差就可以確定最佳的投影方向 w 了。
所以如何確定 w?上面已經簡單的說了,這裡使用公式更加顯而易見吧。
注意上面的分子和分母都是關於 w 的二次項,因此上面的解與 w 的長度無關,只與其方向有關,不失一般性,我們令:

(我們對分母進行歸一化:因為如果分子,分母都是可以取任意值的,那就會使得有無窮解,我們將分母限制為長度為1)
則優化目標等價於:


使用拉格朗日乘子法,上式等價於:
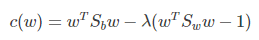
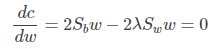
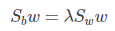
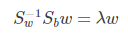
可以看到上式就有轉換為一個求解特徵值和特徵向量的問題了。W就是我們矩陣SW-1SB要求解的特徵向量,這就驗證了我們之前所說的式子:
中的 w 就是特徵向量構成的矩陣。但是在這裡我們仍然有個問題要解決,就是Sw是否可逆,遺憾的是在實際的應用中,它通常是不可逆的,我們通常有兩個辦法解決它。
方法1:令 Sw = Sw + γ I ,其中 γ 是一個特別小的數,這樣 Sw一定可逆。
方法2:先用PCA對資料進行降維,使得在降維後的資料上 Sw可逆,再使用LDA。
6,多類 LDA 原理
有了二類LDA的基礎,我們再來看看多類別 LDA的原理。
假設我們的資料集 D={(x1, y1), (x2, y2), .... (xm, ym)},其中任意樣本 xi 為n維向量,yi屬於{C1, C2,... ,Ck}。我們定義 Nj(j=1, 2, ... k)為第 j 類樣本的個數,Xj(j = 1, 2, ....k)為第 j 類樣本的均值向量,定義 Σj(j = 1, 2, 3, ...k) 為第 j 類樣本的協方差矩陣。在二類 LDA 裡面定義的公式可以很容易的類推到多類LDA。
由於我們是多類向低維投影,則此時投影到的低維空間就不是一條直線,而是一個超平面了。假設我們投影到的低維空間的維度為 d,對應的基向量為 (w1, w2, ....wd),基向量組成的矩陣為 W,它是一個 n*d 的矩陣。
此時我們的優化目標應該可以變成為:

其中:μ 為所有樣本均值向量
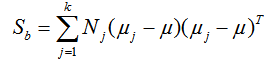
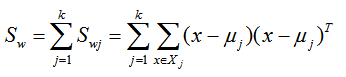
但是有一個問題,就是WTSbW 和 WTSwW 都是矩陣,不是標量,無法作為一個標量函式來優化!也就是說,我們無法直接用二類LDA的優化方法,怎麼做呢?一般來說,我們使用其他的一些替代優化目標來實現。
常見的一個 LDA多類優化目標函式定義為:
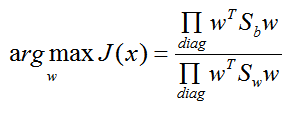
其中 ∏A 為 A的主對角線元素的乘積,W為 n*d 的矩陣。
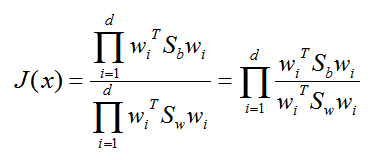
仔細觀察上式最右邊,這不就是廣義瑞利商嘛!最大值是矩陣 Sw-1Sb 的最大特徵值,最大的 d 個值的乘積就是矩陣 Sw-1Sb 的最大的 d個特徵值的乘積,此時對應的矩陣 W 為這最大的 d 個特徵值對應的特徵向量張成的矩陣。
由於 W 是一個利用了樣本的類別得到的投影矩陣,因此它的降維到的維度 d 最大值為 k-1,為什麼最大維度不是類別 k 呢?因為Sb中每個 μj - μ 的秩為1,因此協方差矩陣相加後最大的秩為 k(矩陣的秩小於等於各個相加矩陣的秩的和),但是由於我們知道前 k-1 個 μj 後,最後一個 μk 可以由前 k-1 個 μj 線性表示,因此Sb的秩最大為 k-1,即特徵向量最多有 K-1個。
7,LDA 演算法流程
下面我們對 LDA 降維的流程做一個總結。
輸入:資料集 D = {(x1, y1), (x2, y2), .... (xm, ym)},其中任意樣本 xi 為 n維向量, yi € {C1, c2, ...Ck},降維到的維度 d。
輸出:降維後的樣本集 D'
- 1)計算類內散度矩陣Sw
- 2)計算類間散度矩陣 Sb
- 3)計算矩陣Sw-1Sb
- 4)計算 Sw-1Sb 的最大的 d個特徵值和對應的 d個特徵向量 (w1, w2, ... wd),得到投影矩陣 W
- 5)對樣本集中的每一個樣本特徵 xi,轉化為新的樣本 zi = WTxi
- 6)得到輸出樣本集 D' = {(z1, y1), (z2, y2), .... (zm, ym)}
以上就是使用 LDA 進行降維的演算法流程。實際上LDA除了可以用於降維以外,還可以用於分類。一個常見的LDA分類基本思想是假設各個類別的樣本資料符合高斯分佈,這樣利於LDA進行投影后,可以利用極大似然估計計算各個類別投影資料的均值和方差,進而得到該類別高斯分佈的概率密度函式。當一個新的樣本到來後,我們可以將它投影,然後將投影后的樣本特徵分別代入各個類別的高斯分佈概率密度函式,計算它屬於這個類別的概率,最大的概率對應的類別即為預測類別。
8,LDA vs PCA
LDA用於降維,和PCA有很多相同,也有很多不同的地方,因此值得好好地比較一下兩者的降維異同點。
首先我們看看相同點:
- 1,兩者均可以對資料進行降維
- 2,兩者在降維時均使用了矩陣特徵分解的思想
- 3,兩者都假設資料符合高斯分佈
不同點:
- 1,LDA 是由監督的降維方法,而PCA是無監督的降維方法
- 2,LDA降維最多降到類別數 k-1 的維度,而PCA沒有這個限制
- 3,LDA除了可以用於降維,還可以用於分類
- 4,LDA選擇分類效能最好的投影方向,而PCA選擇樣本點投影具有最大方差的方向
第四點可以從下圖形象的看出,在某些資料分佈下LDA比PCA降維較優
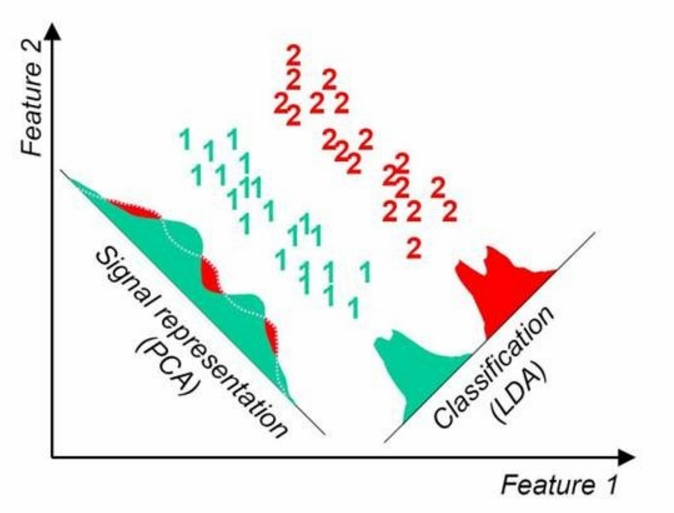
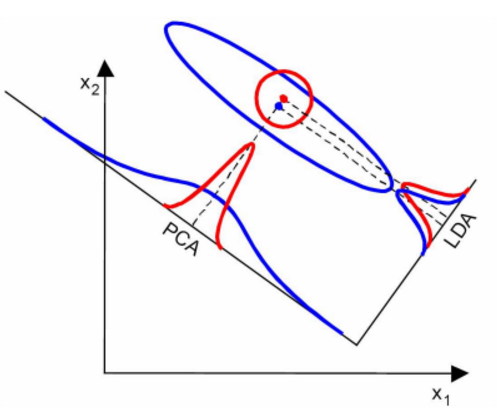
當然,某些資料分佈下,PCA 比 LDA 降維較優,如下圖所示:
9,LDA演算法小結
LDA演算法既可以用來降維,也可以用來分類,但是目前來說,主要還是用於降維。在我們進行影象識別相關的資料分析時,LDA是一個有力的工具,下面總結LDA演算法的優缺點
LDA演算法的主要優點:
- 1,在降維過程中可以使用類別的先驗知識經驗,而像PCA這樣的無監督學習則無法使用類別先驗知識
- 2,LDA在樣本分類資訊依賴均值而不是方差的時候,比PCA之類的演算法較優
LDA演算法的主要缺點:
- 1,LDA不適合對非高斯分佈樣本進行降維,PCA也有這個問題
- 2,LDA降維最多降到類別數 k-1 的維數,如果我們降維的維度大於 k-1,則不能使用 LDA。當然目前有一些LDA的進化版演算法可以繞過這個問題
- 3,LDA在樣本分類資訊依賴方差而不是均值的時候,降維效果不好
- 4,LDA可能過度擬合數據,
用Sklearn 進行LDA降維
在scikit-learn中, LDA類是sklearn.discriminant_analysis.LinearDiscriminantAnalysis。那既可以用於分類又可以用於降維。當然,應用場景最多的還是降維。和PCA類似,LDA降維基本也不用調參,只需要指定降維到的維數即可。
1,LinearDiscriminantAnalysis 類概述
我們這裡對LinearDiscriminantAnalysis類的引數做一個基本的總結。
1)solver : 即求LDA超平面特徵矩陣使用的方法。可以選擇的方法有奇異值分解"svd",最小二乘"lsqr"和特徵分解"eigen"。一般來說特徵數非常多的時候推薦使用svd,而特徵數不多的時候推薦使用eigen。主要注意的是,如果使用svd,則不能指定正則化引數shrinkage進行正則化。預設值是svd
2)shrinkage:正則化引數,可以增強LDA分類的泛化能力。如果僅僅只是為了降維,則一般可以忽略這個引數。預設是None,即不進行正則化。可以選擇"auto",讓演算法自己決定是否正則化。當然我們也可以選擇不同的[0,1]之間的值進行交叉驗證調參。注意shrinkage只在solver為最小二乘"lsqr"和特徵分解"eigen"時有效。
3)priors :類別權重,可以在做分類模型時指定不同類別的權重,進而影響分類模型建立。降維時一般不需要關注這個引數。
4)n_components:即我們進行LDA降維時降到的維數。在降維時需要輸入這個引數。注意只能為[1,類別數-1)範圍之間的整數。如果我們不是用於降維,則這個值可以用預設的None。
從上面的描述可以看出,如果我們只是為了降維,則只需要輸入n_components,注意這個值必須小於“類別數-1”。PCA沒有這個限制。
2,LinearDiscriminantAnalysis 降維例項
我們知道,PCA和LDA都可以用於降維,兩者沒有絕對的優劣之分,使用兩者的原則實際取決於資料的分佈。由於LDA可以利用類別資訊,因此某些時候比完全無監督的PCA會更好,下面我們舉一個LDA降維可能更優的例子。
首先,生成三類三維特徵的資料,程式碼如下:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.datasets.samples_generator import make_classification
X, y = make_classification(n_samples=1000, n_features=3, n_redundant=0,
n_classes=3, n_informative=2, n_clusters_per_class=1,
class_sep=0.5, random_state=10)
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(X[:, 0], X[:, 1], X[:, 2], marker='o', c=y)
我們看看最初的三維資料的分佈情況:

首先我們看看使用PCA降維到二維的情況,注意PCA無法使用類別資訊來降維,程式碼如下:
pca = PCA(n_components=2) pca.fit(X) print(pca.explained_variance_ratio_) print(pca.explained_variance_) # [0.43377069 0.3716351 ] # [1.21083449 1.0373882 ] X_new = pca.transform(X) plt.scatter(X_new[:, 0], X_new[:, 1], marker='o', c=y) plt.show()
圖如下:
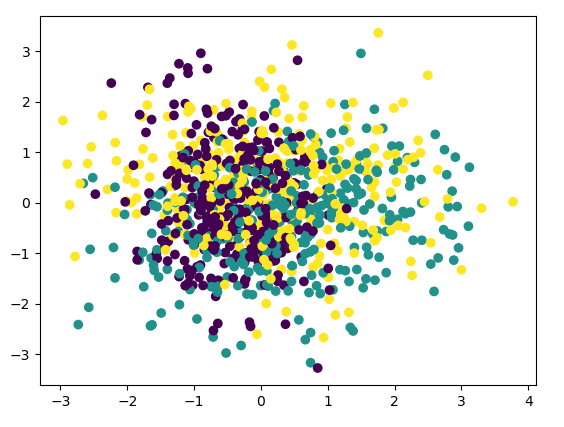
由於PCA沒有利用類別資訊,我們可以看到降維後,樣本特徵和類別的資訊關聯幾乎完全丟失。
下面看看LDA的效果,程式碼如下:
lda = LinearDiscriminantAnalysis() lda.fit(X, y) X_new = lda.transform(X) plt.scatter(X_new[:, 0], X_new[:, 1], marker='o', c=y) plt.show()
輸出的效果圖如下:
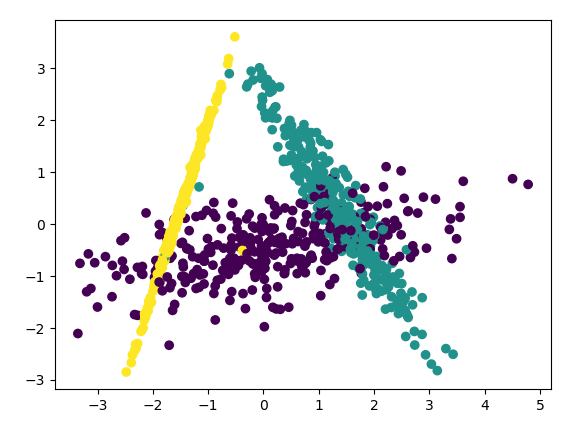
可以看出降維後樣本特徵資訊之間的關係得以保留。
一般來說,如果我們的資料是由類別標籤的,那麼優先選擇LDA去嘗試降維;當然也可以使用PCA做很小幅度的降維去消去噪音,然後再使用LDA降維。如果沒有類別標籤,那麼肯定PCA是最先考慮的一個選擇了。
3,LDA實現iris 資料
首先,iris資料集可以去我的GitHub下載(地址:https://github.com/LeBron-Jian/MachineLearningNote)
下面我們分析匯入的資料集,程式碼如下:
import pandas as pd
feature_dict = {i: label for i, label in zip(range(4),
("Sepal.Length",
"Sepal.Width",
"Petal.Length",
"Petal.Width",))}
# print(feature_dict) # {0: 'Sepal.Length', 1: 'Sepal.Width', 2: 'Petal.Length', 3: 'Petal.Width'}
df = pd.read_csv('iris.csv', header=None, sep=',')
df.columns = ["Number"] + [l for i, l in sorted(feature_dict.items())] + ['Species']
# to drop the empty line at file-end
df.dropna(how='all', inplace=True)
# print(df.tail()) # 列印資料的後五個,和 .head() 是對應的
後五個資料如下:

下面我們把資料分成data和label,如下形式:

程式碼如下:
X = df[["Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"]].values y = df['Species'].values enc = LabelEncoder() label_encoder = enc.fit(y) y = label_encoder.transform(y) + 1
這樣我們對label進行分類,其中{1: 'Setosa', 2: 'Versicolor', 3: 'Virginica'},分類大概是這樣的:
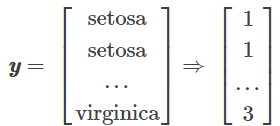
下面我們分別求三種鳶尾花資料在不同特徵維度上的均值向量 Mi。

求均值的程式碼如下:
np.set_printoptions(precision=4)
mean_vectors = []
for c1 in range(1, 4):
mean_vectors.append(np.mean(X[y == c1], axis=0))
print('Mean Vector class %s : %s\n' % (c1, mean_vectors[c1 - 1]))
三個類別,求出的均值如下:
Mean Vector class 1 : [5.006 3.428 1.462 0.246] Mean Vector class 2 : [5.936 2.77 4.26 1.326] Mean Vector class 3 : [6.588 2.974 5.552 2.026]
下面計算兩個 4*4 維矩陣:類內散佈矩陣和類間散佈矩陣,公式如下:
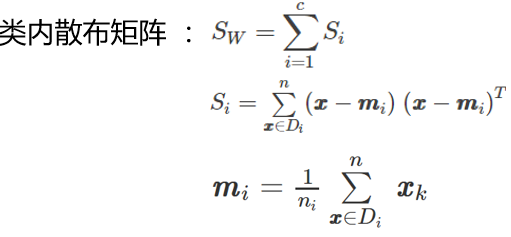
程式碼如下:
S_W = np.zeros((4, 4))
for c1, mv in zip(range(1, 4), mean_vectors):
# scatter matrix for every class
class_sc_mat = np.zeros((4, 4))
for row in X[y == c1]:
# make column vectors
row, mv = row.reshape(4, 1), mv.reshape(4, 1)
class_sc_mat += (row - mv).dot((row - mv).T)
# sum class scatter metrices
S_W += class_sc_mat
print('within-class Scatter Matrix:\n', S_W)
結果如下:
within-class Scatter Matrix: [[38.9562 13.63 24.6246 5.645 ] [13.63 16.962 8.1208 4.8084] [24.6246 8.1208 27.2226 6.2718] [ 5.645 4.8084 6.2718 6.1566]]
類間散佈矩陣如下:
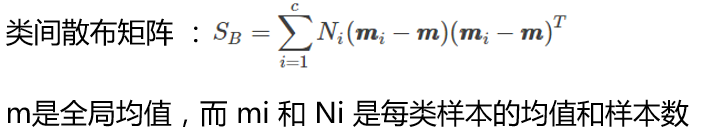
程式碼如下:
overall_mean = np.mean(X, axis=0)
S_B = np.zeros((4, 4))
for i, mean_vec in enumerate(mean_vectors):
n = X[y == i + 1, :].shape[0]
# make column vector
mean_vec = mean_vec.reshape(4, 1)
# make column vector
overall_mean = overall_mean.reshape(4, 1)
S_B += n*(mean_vec - overall_mean).dot((mean_vec - overall_mean).T)
print('between-class Scatter matrix:\n', S_B)
結果展示:
between-class Scatter matrix: [[ 63.2121 -19.9527 165.2484 71.2793] [-19.9527 11.3449 -57.2396 -22.9327] [165.2484 -57.2396 437.1028 186.774 ] [ 71.2793 -22.9327 186.774 80.4133]]
然後我們求解矩陣的特徵值:

程式碼如下:
eig_vals, eig_vecs = np.linalg.eig(np.linalg.inv(S_W).dot(S_B))
for i in range(len(eig_vals)):
eigvec_sc = eig_vecs[:, i].reshape(4, 1)
print('\n Eigenvector {}: \n {}'.format(i+1, eigvec_sc.real))
print('Eigenvalue {: }: {:.2e}'.format(i+1, eig_vals[i].real))
結果如下:
Eigenvector 1: [[ 0.2087] [ 0.3862] [-0.554 ] [-0.7074]] Eigenvalue 1: 3.22e+01 Eigenvector 2: [[-0.0065] [-0.5866] [ 0.2526] [-0.7695]] Eigenvalue 2: 2.85e-01 Eigenvector 3: [[-0.868 ] [ 0.3515] [ 0.3431] [ 0.0729]] Eigenvalue 3: -1.04e-15 Eigenvector 4: [[-0.1504] [-0.2822] [-0.3554] [ 0.8783]] Eigenvalue 4: 1.16e-14
最後求特徵值與特徵向量,其中:
- 特徵向量:表示對映方向
- 特徵值:特徵向量的重要程度
程式碼如下:
# make a list of (eigenvalue, eigenvector) tuples
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:, i]) for i in range(len(eig_vals))]
# sort the (eigenvalue, eigenvector) tuples from high to low
eig_pairs = sorted(eig_pairs, key=lambda k: k[0], reverse=True)
# Visually cinfirm that the list is correctly sorted by decreasing eigenvalues
print('Eigenvalues in decreasing order: \n')
for i in eig_pairs:
print(i[0])
特徵向量如下:
Eigenvalues in decreasing order: 32.19192919827802 0.28539104262306847 1.1615338676864736e-14 1.039562883345519e-15
特徵值程式碼如下:
print('Variance explained:\n')
eigv_sum = sum(eig_vals)
for i, j in enumerate(eig_pairs):
print('eigenvalue {0:}: {1:.2%}'.format(i + 1, (j[0] / eigv_sum).real))
結果如下:
Variance explained: eigenvalue 1: 99.12% eigenvalue 2: 0.88% eigenvalue 3: 0.00% eigenvalue 4: 0.00%
我們從上可以知道,選擇前兩維特徵
W = np.hstack((eig_pairs[0][1].reshape(4, 1), eig_pairs[1][1].reshape(4, 1)))
print('Matrix W: \n', W.real)
特徵矩陣W如下
Matrix W: [[ 0.2087 -0.0065] [ 0.3862 -0.5866] [-0.554 0.2526] [-0.7074 -0.7695]]
lda如下:
X_lda = X.dot(W) assert X_lda.shape == (150, 2), 'The matrix is not 150*2 dimensional.'
下面畫圖:
def plt_step_lda():
ax = plt.subplot(111)
for label, marker, color in zip(range(1, 4), ('^', 's', 'o'), ('blue', 'red', 'green')):
plt.scatter(x=X_lda[:, 0].real[y == label],
y=X_lda[:, 1].real[y == label],
marker=marker,
color=color,
alpha=0.5,
label=label_dict[label])
plt.xlabel('LD1')
plt.ylabel('LD2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title('LDA: Iris projection onto the first 2 linear discriminants')
# hide axis ticks
plt.tick_params(axis='both', which='both', bottom='off',
top='off', labelbottom='on', left='off',
labelleft='on')
# remove axis spines
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
plt.grid()
plt.tight_layout()
plt.show()
plt_step_lda()
如圖所示:

使用sklearn實現lda:
# LDA
sklearn_lda = LDA(n_components=2)
X_lda_sklearn = sklearn_lda.fit_transform(X, y)
def plot_scikit_lda(X, title):
ax = plt.subplot(111)
for label, marker, color in zip(range(1, 4), ('^', 's', 'o'), ('blue', 'red', 'green')):
plt.scatter(x=X_lda[:, 0].real[y == label],
# flip the figure
y=X_lda[:, 1].real[y == label] * -1,
marker=marker,
color=color,
alpha=0.5,
label=label_dict[label])
plt.xlabel('LD1')
plt.ylabel('LD2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title(title)
# hide axis ticks
plt.tick_params(axis='both', which='both', bottom='off',
top='off', labelbottom='on', left='off',
labelleft='on')
# remove axis spines
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
plt.grid()
plt.tight_layout()
plt.show()
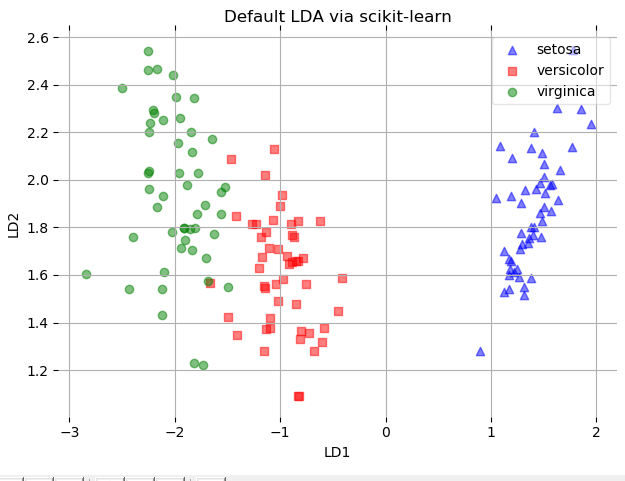
plot_scikit_lda(X, title='Default LDA via scikit-learn')
結果如下:
完整程式碼及其資料,請移步小編的GitHub
傳送門:請點選我
如果點選有誤:https://github.com/LeBron-Jian/MachineLearningNote
PS:這裡是整理的學習筆記,參考文獻如下,還有自己老師的PPT,不喜勿噴,謝謝
參考文獻:http://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html
https://www.cnblogs.com/pinard/p/6244265.html
https://www.cnblogs.com/pinard/p/6249328.html
https://blog.csdn.net/liuweiyuxiang/article/details/7887