
python: 知乎大規模(34k)使用者爬蟲
前些天學習python,完成了python練習冊的大部分習題:https://github.com/Show-Me-the-Code/python(我的github上有習題程式碼,歡迎自取)。之後看到@salamer的一個python爬蟲專案,覺得很不錯。於是自己花了4天的時間完成了一個大規模爬取知乎使用者資訊的爬蟲,由於個人網路原因,爬取12小時,獲得了34k使用者的資訊(理論上可以爬全站的資訊,可能時間要長一些,最好放在伺服器上跑)並整理成直觀的圖表(文章末尾顯示)。
好了,說一下主要的技術點:
(1)使用python的request模組獲取html頁面,注意要修改自己的cookie,使得我們更像是使用瀏覽器訪問
(2)使用xpath模組從html中提取需要的關鍵資訊(姓名,職業,居住地,關注人等)
(3)使用redis作為佇列,很好的解決併發和大規模資料的問題(可以分散式)
(4)使用bfs寬度優先搜尋,使得程式得以不斷擴充套件持續搜尋使用者
(5)資料儲存至no-sql資料庫:mongodb(高效輕量級並且支援併發)
(6)使用python的程序池模組提高抓取速度
(7)使用csv,pandas,matplotlib模組進行資料處理(需要完善)
接下來我們進行仔細的分析:
(一)資料的獲取
主要使用了python的request進行html的獲取,另外,header中的cookie攜帶了我們的登陸資訊,所以,按下你的F12將自己的cookie新增至程式中。
知乎上有很多水軍,我們為了更加高質量的抓取使用者資訊,使用了這樣一個策略:只抓取每個人的關注者,這樣可以相對有效的減少水軍和小號。

#cookie要自己從瀏覽器獲取 self.header["User-Agent"]="Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:35.0) Gecko/20100101 Firefox/35.0" self.cookies={"q_c1":"8074ec0c513747b090575cec4a547cbd|1459957053000|1459957053000", "l_cap_id":'"Y2MzODMyYjgzNWNjNGY4YzhjMDg4MWMzMWM2NmJmZGQ=|1462068499|cd4a80252719f069cc467a686ee8c130c5a278ae"', "cap_id":'"YzIwNjMwNjYyNjk0NDcyNTkwMTFiZTdiNmY1YzIwMjE=|1462068499|efc68105333307319525e1fc911ade8151d9e6a6"', "d_c0":'"AGAAI9whuwmPTsZ7YsMeA9d_DTdC6ijrE4A=|1459957053"', "_za":"9b9dde53-9e53-4ed1-a17f-363b875a8107", "login":'"YWQyYzQ4ZDYyOTAwNDVjNTg2ZmY3MDFkY2QwODI5MGY=|1462068522|49dd99d3c8330436f211a130209b4c56215b8ec3"', "__utma":"51854390.803819812.1462069647.1462069647.1462069647.1", "__utmz":"51854390.1462069647.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic", "_xsrf":"6b32002d2d529794005f7b70b4ad163e", "_zap":"a769d54e-78bf-44af-8f24-f9786a00e322", "__utmb":"51854390.4.10.1462069647", "__utmc":"51854390", "l_n_c":"1", "z_c0":"Mi4wQUFBQWNJQW9BQUFBWUFBajNDRzdDUmNBQUFCaEFsVk5LdkpNVndCRlQzM1BYVEhqbWk0VngyVkswSVdpOXhreDJB|1462068522|eed70f89765a9dd2fdbd6ab1aabd40f7c23ea283", "s-q":"%E4%BA%91%E8%88%92", "s-i":"2", "sid":"1jsjlbsg", "s-t":"autocomplete", "__utmv":"51854390.100--|2=registration_date=20140316=1^3=entry_date=20140316=1", "__utmt":"1"}
使用xpath提取html中我們需要關注的資訊,這裡給個小例子,關於xpath的用法請自行百度:)
def get_xpath_source(self,source):
if source:
return source[0]
else:
return ''
tree=html.fromstring(html_text)
self.user_name=self.get_xpath_source(tree.xpath("//a[@class='name']/text()"))
self.user_location=self.get_xpath_source(tree.xpath("//span[@class='location item']/@title"))
self.user_gender=self.get_xpath_source(tree.xpath("//span[@class='item gender']/i/@class"))
(二)搜尋和儲存
準備搜尋的url佇列可能會很大,我們使用redis作為佇列來儲存,不僅程式退出後不會丟失資料(程式重新執行可以繼續上次的搜尋),而且支援分散式水平擴充套件和併發。
核心採用BFS寬度優先搜尋來進行擴充套件,這裡不清楚的,恐怕要自己去學習下演算法了。儲存提供兩種方式,一種直接輸出至控制檯,另一種就是儲存至mongodb費關係資料庫。
# 核心模組,bfs寬度優先搜尋
def BFS_Search(option):
global red
while True:
temp=red.rpop('red_to_spider')
if temp==0:
print 'empty'
break
result=Spider(temp,option)
result.get_user_data()
return "ok"
def store_data_to_mongo(self):
new_profile = Zhihu_User_Profile(
user_name=self.user_name,
user_be_agreed=self.user_be_agreed,
user_be_thanked=self.user_be_thanked,
user_followees=self.user_followees,
user_followers=self.user_followers,
user_education_school=self.user_education_school,
user_education_subject=self.user_education_subject,
user_employment=self.user_employment,
user_employment_extra=self.user_employment_extra,
user_location=self.user_location,
user_gender=self.user_gender,
user_info=self.user_info,
user_intro=self.user_intro,
user_url=self.url
)
new_profile.save()
(三)多程序提高效率
python由於GIL鎖的原因,多執行緒並不能達到真正的並行。這裡使用python提供的程序池進行多程序操作,這裡有一個問題需要大家注意:
實際測試下來,在選取將資料儲存至mongodb資料庫這個方式下,多程序沒能提高效率,甚至比單程序還要慢,我分析了下原因:由於計算的部分花時間很少,主要的瓶頸在磁碟IO,也就是寫進資料庫,一個時刻只能有一個程序在寫,多程序的話會增加很多鎖機制的無端開銷,造成了上述結果。
但是直接輸出的話速度會快很多。這也提示我們多程序並不是一定能提高速度的,要根據情況選擇合適的模型。
使用多程序,注意,實際測試出來,並沒有明顯速度的提升,瓶頸在IO寫;如果直接輸出的話,速度會明顯加快
res=[]
process_Pool=Pool(4)
for i in range(4):
res.append(process_Pool.apply_async(BFS_Search,(option, )))
process_Pool.close()
process_Pool.join()
for num in res:
print ":::",num.get()
print 'Work had done!'
(四)資料分析
這裡我們使用csv,pandas模組進行資料分析,關於模組的使用請自行google,這裡貼出自己做出的一些分析圖:
知乎使用者城市分佈:
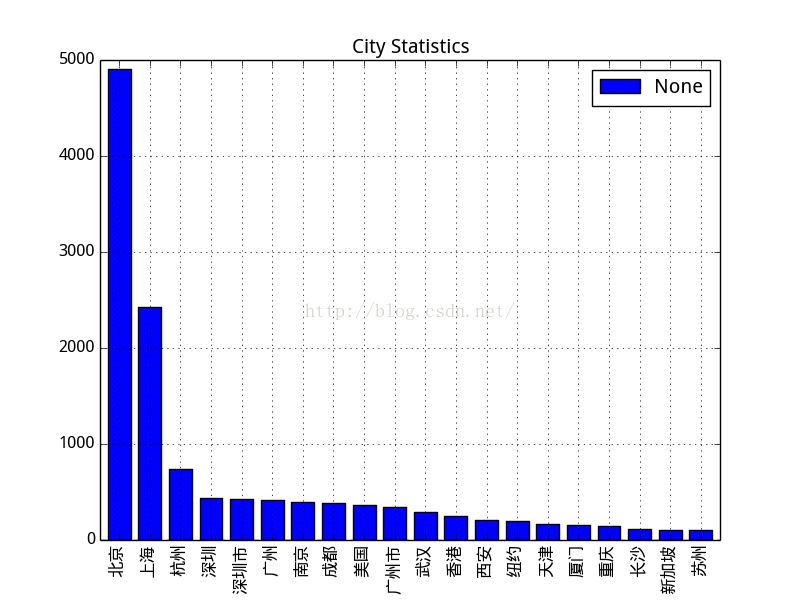
一線城市的使用者高居榜首,尤其北京。美國的也好多啊..
知乎使用者專業分佈:
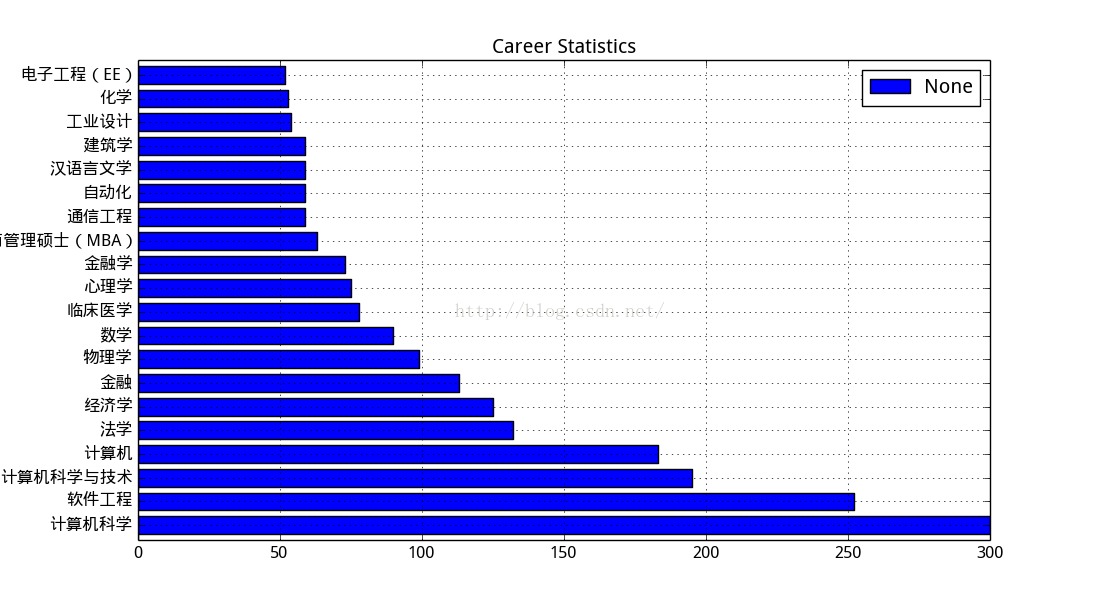
果然知乎上的程式猿最多。。
知乎使用者學校分佈:
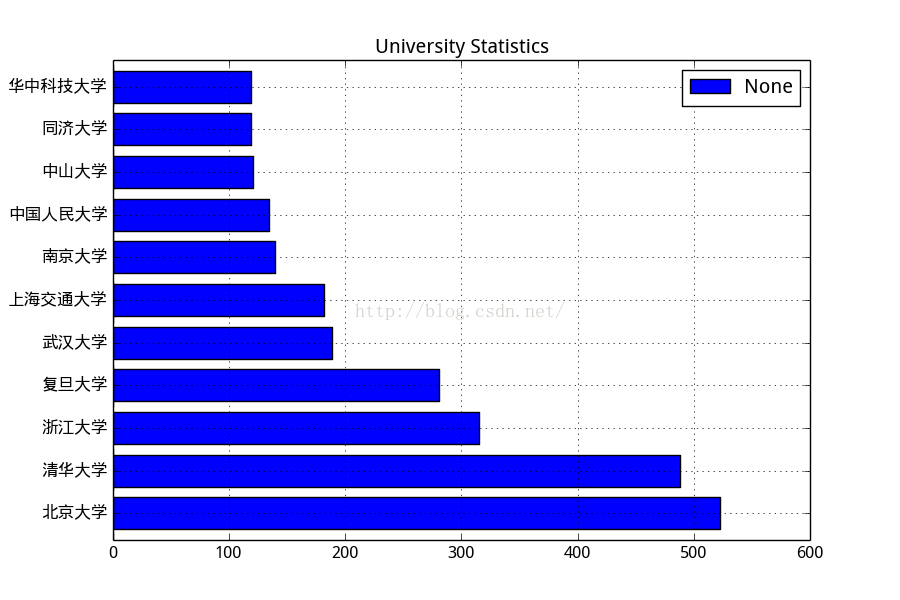
清北和華東五虎高校的學校居多,看來知乎的學生群體質量很高。
知乎使用者職業分佈:
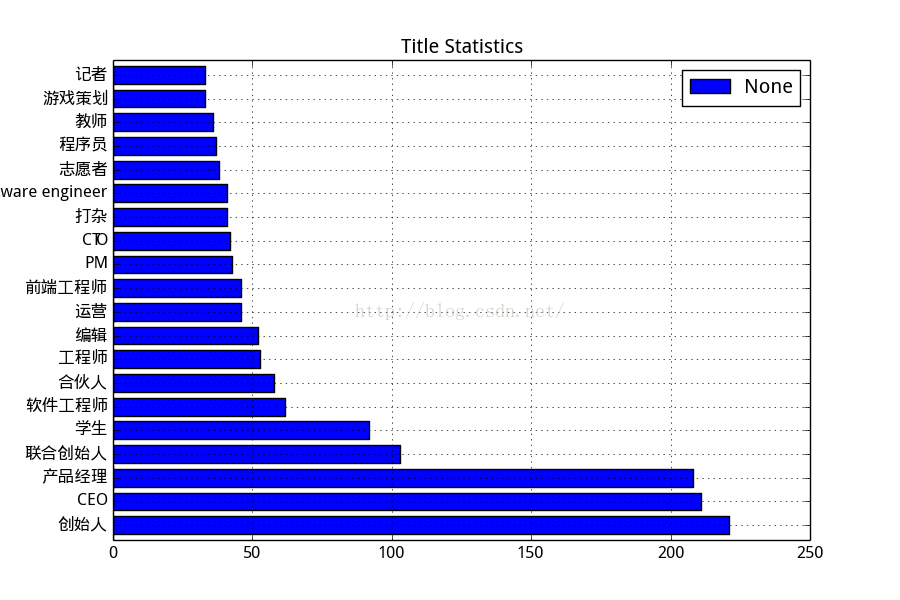
很多大佬啊,這麼多創始人和CEO,還有天敵:產品經理....
好了,就展示到這裡吧,對這個專案有興趣的同學,可以到我的Github檢視,原始碼全部在 這裡
資料分析部分並不專業,希望更多的人來完善這個專案,我自己也會開啟下一步學習,將其改為分散式爬蟲,希望給大家帶來幫助~
相關推薦
python: 知乎大規模(34k)使用者爬蟲
前些天學習python,完成了python練習冊的大部分習題:https://github.com/Show-Me-the-Code/python(我的github上有習題程式碼,歡迎自取)。之後看到@salamer的一個python爬蟲專案,覺得很不錯。於是自己花了4天的
微信小程式日記——高仿知乎日報(上)
該小程式的作者是Oopsguy,我也參與小功能的開發和完善,希望大家能支援一下 本人對知乎日報是情有獨鍾,看我的部落格和github就知道了,寫了幾個不同技術型別的知乎日報APP 要做微信小程式首先要對html,css,js有一定的基礎,還有對微信小
Android 高仿知乎日報(1)
個人蠻喜歡沒事看看知乎的,前陣子湊巧也在網上搜到了知乎日報的API,詳情見某位開發者在Github上的分享:知乎日報 API 分析 靠著這個,我就做了一個高仿知乎日報的小應用 動態圖看起來不怎麼流暢,其實真機執行的話還是很流程的,畢竟這只是一個純
知乎搜尋/(引擎)的故事
一、以搜尋“姬無命”為例——站內搜尋與通用搜索之爭 PC端目前有三類四種知乎搜尋的方法: (注:手機端微信內支援知乎搜尋。) 第一類自然是知乎網頁內部直接搜尋(zhihu.com) 第一類是:搜狗知乎搜尋(https://zhihu.sogou.com/) 第二類是:主流搜尋引擎的站點內搜尋。 一是百度:如搜
python知乎內容抓取(redis存儲)
sorted mat param 爬取 Nid odi 請求 quest 一個 因為平時喜歡上知乎,發現其話題是一個有向無環圖(自己介紹說得),一級一級往上最後到根話題,所以我就想嘗試從根話題一級一級往下將其全部內容爬取。最後實踐過程中發現自己想多了..有以下三個問題:
知乎--LSTM(挺全的)
最近接到指導老師給的“看一下LSTM”的任務。 雖然之前已經瞭解過LSTM以及RNN的基本原理和適用範圍,但是還沒有寫過程式碼,因此通過這個機會,將RNN以及LSTM及其變體,更詳細的瞭解一下,並儘量將其實現。 Below comes from Wikipedia: 遞迴神經網路(RNN
Python 接口測試(一)
blog 系統環境變量 resp 環境變量 nbsp 們的 www nload uic 1. 概念: 接口測試是測試系統組件間接口的一種測試。接口測試主要用於檢測外部系統與系統之間以及內部各個子系統之間的交互點。測試的重點是要檢查數據的交換,傳遞和控制管理過程,以及系統間的
Python 接口測試(五)
方式 img 思路 tag 會有 地址 api接口 pytho 自己 五:使用python進行組織編寫接口測試用例 接口測試其實就是幾個步驟。 拿到接口的url地址 查看接口是用什麽方式發送 添加請求頭,請求體 發送查看返回結果,校驗返回結果是否正確 明白了接口測試的測
Python 接口測試(三)
3.4 control .html .get agent gif gin version tps 四:python接口之http請求 python的強大之處在於提供了很多的標準庫以及第三庫,本文介紹urllib 和第三庫的requests。 Urllib 定義了很多函數和類
Python 接口測試(四)
數列 格式 dumps code 輸出 pre weather 標準 lang 五:python數列化和反序列化 把python的對象編碼轉換為json格式的字符串,反序列化可以理解為:把json格式 字符串解碼為python數據對象。在python的標準庫中,專門提供了j
Python 接口測試(二)
expect type version not found 指定 刷新 created 進行 拷貝 三:http狀態碼含義(來源於w3school): 狀態碼: 1xx: 信息 消息: 描述: 100 Continue 服務器僅接收到部分請求,但是一旦
python學習之路(四)
[1] size class dex epc uri msu 語句 這就是 繼續昨天的學習,學到了數組。 首先有兩個數組,name1和name2.我們可以將兩個數組合並 name1=[1,2,3,4] name2=[5,6,7,8] names=name1.extend(
python學習-day6-生成器(generator)
expr 無法 color 循環調用 限制 10個 數列 例子 ner 一,列表生成式 ls = [i*i for i in range(10)]ls[0, 1, 4, 9, 16, 25, 36, 49, 64, 81] ge = (i*i for i in range(
python中的JSON(1)
welcome 定義 ack () found 存儲 remember nbsp python程序 很多程序都要求用戶輸入某種信息, 例如: 讓用戶存儲遊戲首選項或提供要可視化的數據,程序把用戶的信息存儲在列表和字典等數據結構中, 用戶關閉程序時,我們幾乎總要保存他們提
Python學習手冊筆記(1):Python對象類型
python 在Python中一切皆對象,Python程序可以分解為模塊、語句、表達式及對象。如下所示:1 程序由模塊組成2 模塊包含語句3 語句包含表達式4 表達式建立並處理對象 內置對象(核心類型):1)數字:>>> 2+2 #整數加法4>>&g
Python httpServer服務器(初級)
prot link 相關 esp 表達式 title 處理 版本 web服務器 使用原生的python開發的web服務器,入門級! #!/usr/bin/python # -*- coding: UTF-8 -*- import os #Python的標準
python交互式(input)
python交互式(input)#交互式輸出#!/usr/bin/env python # -*- coding:utf-8 -*- name = input("what is your name?") password = input("Please enter password?") print(na
Python入門系列教程(二)
字符 小寫 無符號 bsp div width raw_input abc body 字符串 1.字符串輸出 name = ‘xiaoming‘ print("姓名:%s"%name) 2.字符串輸入 userName = raw_input(‘請輸
Python Click 學習筆記(轉)
col 輸出 小工具 方法 chm 好的 put name 回調 原文鏈接:Python Click 學習筆記 Click 是 Flask 的團隊 pallets 開發的優秀開源項目,它為命令行工具的開發封裝了大量方法,使開發者只需要專註於功能實現。恰好我最近在開發的一個小
Python入門系列教程(五)函數
st3 python入門 test print 缺省 .com 教程 技術 log 全局變量 修改全局變量 a=100 def test(): global a a=200 print a 多個返回值 缺省參數 d