
2D多人關鍵點--《Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields》
《Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields》
來源:CMU,OpenPose開源多人姿態模型
原始碼:https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation
本文雖然是2016年的論文,但其文中提出的方法還是很值得學習和借鑑的
文章目錄
- 0 摘要
- 1介紹
- 2 PAF
- 2.1 Overall pipeline
- 2.2 Simultaneous Detection and Association
- 2.3 Loss Function
- 2.4 Confidence Maps for Part Detection
- 2.5 Part Affinity Fields for Part Association
- 2.6 MultiPerson Parsing using PAFs
- 3 結果
0 摘要
本文提出了一種區域性關聯場(PAF,Part Affinity Fields)方法,來實現自底向上(bottom-up)的多人2D姿態估計;
PAF:它是一種將單個人的各個區域性進行關聯;即同一個人的相鄰部位關聯度強(更具親和力),如肘部和腕部,不同人之間的部位關聯度弱,甚至沒有關聯,並用一個2D向量場來表示;且將這種關聯關係同關鍵點一起放入到CNN網路進行學習,從而達到端到端的自底向上的多人姿態估計
在COCO 2016 keypoints challenge多人場景上,大大超越了之前的方法,效率和效果都取得非常大的進步
1介紹
1)單人場景,略過
2)多人場景,難點
A)每張影象上的人數未知,位置不定,佔比不定
B)人與人之間,相互接觸,相互遮擋,部分交叉等增加了關聯難度
C)人數越多,複雜度越大,實時性難保證
3)多人場景,自上向下(top-dwon)
也就是先用目標檢測手段,定位每個個體,將問題轉化為單人場景;這種方法有2個隱患:
A)對目標檢測要求高,且有時間開銷
B)人數較多時,每個人都需要跑一次前向網路,時間開銷太大
4)多人場景,自底向上(bottom-up)
類似於本文的方法,CNN網路可能複雜度高,但不會因人數多少增加時間開銷,也不用目標檢測
文中對這兩種方案進行了時間開銷對比,如下圖:

2 PAF
2.1 Overall pipeline

首先,輸入
影象Fig. 2a,2D關鍵點Fig. 2e;
然後,two-branch CNN:
1)一路預測身體關鍵點的2D置信度對映圖集S(part confidence map),如Fig. 2b
J表示對映圖個數,一般為關鍵點個數+1(背景)
2)另一路預測區域性關聯場對2D向量場集L(part affinity vector field),如Fig. 2c
L用來編碼部位之間的關聯程度,對於每個肢體(成對的部位)具有C個向量場;每個點編碼成一個2D向量場Lc,如圖:

肢體:由關鍵點對組成,如右肘關節和右腕關節,儘管這裡的某些肢體可能不是人的真正肢體;2D向量編碼這個肢體的位置和方向
最後,通過對置信度對映和關聯場進行貪婪推理得出所有人的關鍵點,如Fig. 2d
2.2 Simultaneous Detection and Association

如上述所說,本文采用two-branch multi-stage CNN作為最終CNN框架;如上圖,上半部分為關聯場預測網路,下半部分為關鍵點預測網路,並採用多級(stage)級聯方法 ,每級之後,將影象和兩個支流融合到一起供下一級使用;且在訓練過程中,每級都會進行loss監督(中間監督)
用數學式表達框架為:
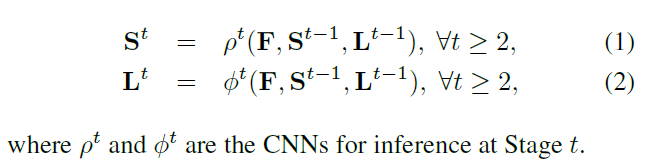
2.3 Loss Function
loss function:
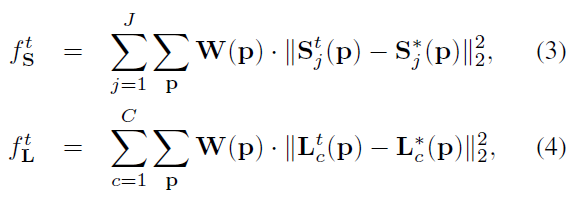
其中,t表示第幾級,
表示groundtruth part confidence map;
表示groundtruth part affinity vector field;
W表示二值mask,
就表示當前點p缺失(不可見或不在影象中),用來避免訓練時錯誤懲罰
且在訓練時,增加中間級監督,防止梯度消失(vanishing gradient problem)
最終loss為:
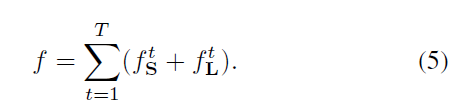
2.4 Confidence Maps for Part Detection
理論上每個confidence map是對應groundtruth位置單個畫素響應(為1),其他畫素點位0;但在實際應用中,我們是用高斯函式生成對應groundtruth位置,周圍畫素響應(高斯響應)
對於單人場景來說,一個響應圖只有一個峰值響應;
而多人場景,就複雜得多了,一個響應圖中,每個人k對應可見點j都應該有峰值響應:
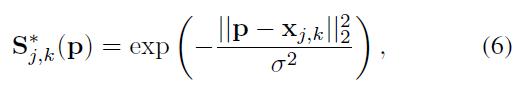
在預測階段,通過對個體置信度響應進行max操作和非最大化抑制獲取候選點:
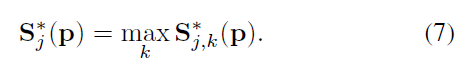
2.5 Part Affinity Fields for Part Association
如圖:

1)如上圖中Fig. 5a,給定檢測到身體的候選點(紅色和藍色點),在人數未知情況下,我們如何確定那些點是同一個人的呢???這就是自底向上(bottom-up)多人姿態估計面臨的最大挑戰
2)面對這樣一個問題,我們就需要一個描述部位(點)之間關係的一種度量,一種表示方法,來判定;
3)測量關聯的一種可能方法是檢測肢體上每對點之間的額外中點,並檢查候選點之間的關聯,如圖Fig. 5b所示;然而,當人們聚集在一起時,這些中點很可能支援錯誤的關聯(如圖Fig. 5b中的綠線所示),這種錯誤的關聯是由表示中兩個侷限引起的:
(1)它只編碼每一肢體的位置,而沒有方向;
(2)將肢體的支撐區域縮小到單點(中點)。
4)針對一些侷限,本文提出了一種新的表示方法,即區域性關聯場(PAF),它將整個肢體區域作為支撐域,並同時編碼位置和方向資訊,如圖Fig. 5c;對於屬於肢體的每個畫素,PAF對從肢體的一點到另一點的方向進行編碼,每種型別的肢體都有一個2D向量場來表示。
向量場表示
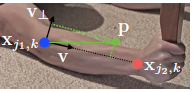
1)上圖表示一個肢體,
,
表示影象種第k個人的肢體c中的兩個groundtruth點j1和j2
2)點p是肢體上的點,當然它有界定範圍:
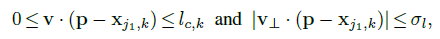
其中:
表示肢體單位方向向量
表示v的垂直向量
表示肢體長度
表示肢體寬度
3)則肢體區域的向量場表示為:

4)最終向量場groundtruth是平均影象中的所有個人:
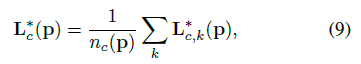
其中
表示非0點數的平均值
5)預測階段,我們計算相應向量場上的線段積分來衡量關聯關係;換句話說,我們計算PAF連線候選肢體的線佇列,如候選點
,
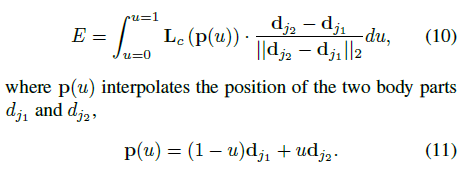
在實際應用中,我們通過取樣和等間距u值的累加來近似積分。
2.6 MultiPerson Parsing using PAFs
我們對檢測置信度對映進行非最大抑制操作,以獲取候選點位置的離散集,如圖:
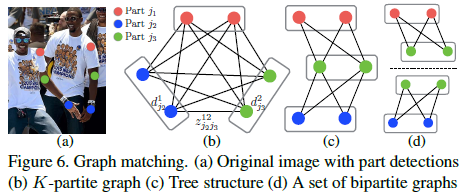
1)對於每個部位,可能有多個候選項,因為影象中有多個人或誤報(Fig. 6b),這些候選部位定義來大量可能的分支;
2)我們使用PAF來對這些分支進行評分,如式10,找到這個最有解問題是一個NP-Hard的K維匹配問題;本文中提出來一種貪婪鬆弛方法,它可以持續的產生高質量的匹配,這也得益於PAF進行全域性上下文編碼,擁有很大的接受域
3)定義
來表示候選點
,
是否連線,從而我們優化目標就變成找到最優匹配,從可能連線中: