
2D/3D 手勢關鍵點:《Hand Keypoint Detection in Single Images using Multiview Bootstrapping》
《Hand Keypoint Detection in Single Images using Multiview Bootstrapping》
作者:Tomas Simon, Hanbyul Joo, Iain Matthews, Yaser Sheikh
機構:Carnegie Mellon University
論文:PDF
實現:OpenPose
文章目錄
- 1 Introduction
- 2 Related Work
- 3 Multiview Bootstrapped Training
- 4 Detection Architecture
- 5 Performance
1 Introduction
現狀:
1)帶標籤點手勢關鍵點資料很少
2)手勢變化複雜,人工標記資料,時間和花銷代價巨大
3)特殊場景下,人工標記也無法準確標記關鍵點,只能大概估計,如遮擋、握拳✊等,如下圖

思想:
利用立體幾何,以多檢視作為監督訊號源,生成一致的手部關鍵點標籤,引導訓練手部關鍵點檢測器。
本文提出的是一種弱監督訓練方法,在訓練資料上,只有少量標註資料,大量未標註的多檢視資料
結論:
該方法訓練的關鍵點檢測器可以實時執行在單RGB影象上,其精度可與深度感測器方法媲美;能夠支援複雜物件3D無標記動作捕捉。
2 Related Work
相關研究,略
但它們大部分都是基於深度圖,且需要大量帶標記的資料來訓練;當然對於深度圖來說,相對容易合成,而RGB圖則困難得多
3 Multiview Bootstrapped Training
首先定義一個檢測器d:
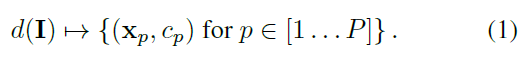
其中,d表示檢測器,I表示影象,
表示預測關鍵點座標,
表示點置信度,P表示點個數
對於初始化訓練集
:
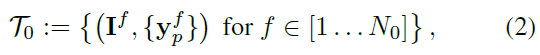
其中f表示影象幀,每幀
個檢視,y標識真實標籤。初始化檢測器
:
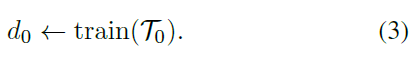
這時給定未標定資料集
,用
預測標記
,再進一步訓練檢測器
:
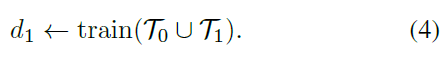
在用
預測標記
中需要做額外監督處理,才能保證
不包含
中已經存在的資訊,才能提升
為
。
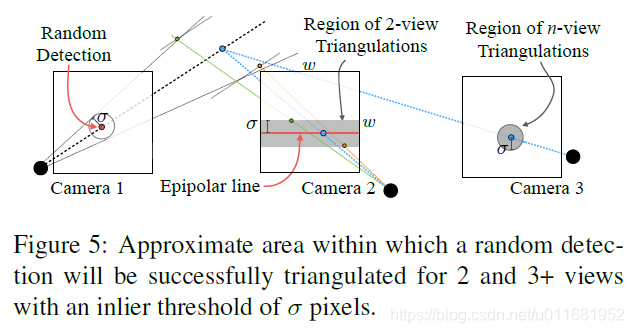
而這個額外監督正是基於立體幾何多檢視。因為在多檢視下,總會有某些檢視較其他容易檢測,那麼只要至少存在2個檢視檢測成功,就可以利用立體幾何方式三角化3D關鍵點,然後再重投影到檢測失敗樣本上進行標記,進而再訓練。如下圖

(a)圖表示至少2個檢視能夠成功檢測;(b)利用立體幾何重建3D關鍵點;(c)檢測失敗檢視;(d)重投影到失敗檢視(標記);(e)重新訓練(公式4)
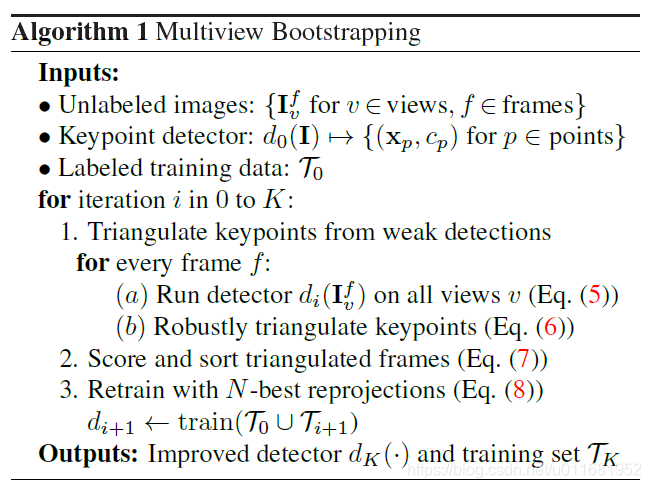
整體演算法流程如下:
其中,
表示含F幀V個檢視,且未標記樣本
迭代K次:
1)用帶標籤的
初始化d為弱檢測器
對每一幀f
a)預測每一個檢視
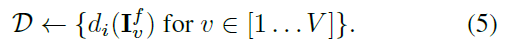
b)增加3D點魯棒性
本文采用
的RANSAC演算法來輔助3D點計算,並且要求2D點置信度大於閾值
。也就是在RANSAC inliers內點p,我們最小化重投影誤差(公式6,
表示重投影)來獲得最終三角點:
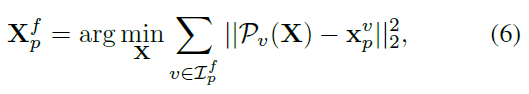
2)根據點置信度對檢視排序,只選擇成功檢視進行3D重建
用置信度和排序:
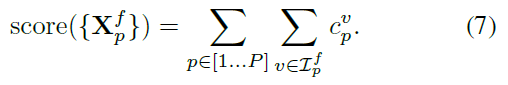
3)重投影到失敗檢視,共生成
幀檢視,並用於迭代訓練檢測器
用N-best 幀參與下一輪訓練:
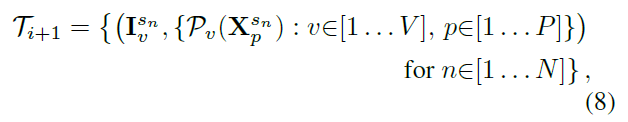
4 Detection Architecture
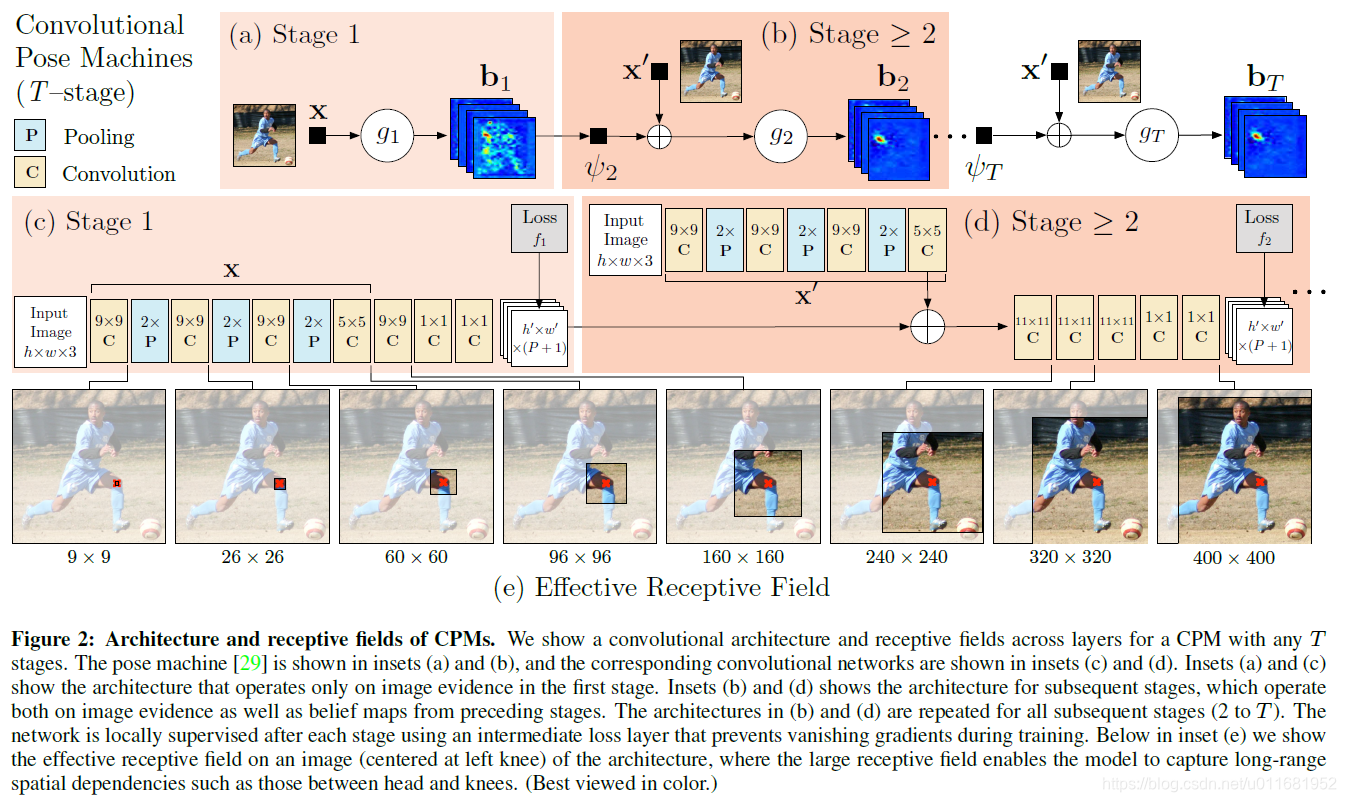
本文模型架構採用CPM(Convolutional Pose Machines),詳見CPM
5 Performance

實測效果見OpenPose