
hadoop學習1--hadoop2.7.3叢集環境搭建
下面的部署步驟,除非說明是在哪個伺服器上操作,否則預設為在所有伺服器上都要操作。為了方便,使用root使用者。
1.準備工作
1.1 centOS7伺服器3臺
master 192.168.174.132
node1 192.168.174.133
node2 192.168.174.134
1.2 軟體包
hadoop-2.7.3.tar.gz
jdk-7u79-linux-x64.tar.gz
上傳到3臺伺服器的/soft目錄下
1.3 關閉防火牆
檢查防火牆
[[email protected] systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall開機啟動
1.4 關閉selinux
檢查selinux狀態
enable這是生效狀態。[[email protected] ~]# sestatus SELinux status: enabled SELinuxfs mount: /sys/fs/selinux SELinux root directory: /etc/selinux Loaded policy name: targeted Current mode: enforcing Mode from config file: enforcing Policy MLS status: enabled Policy deny_unknown status: allowed Max kernel policy version: 28
臨時關閉
[[email protected] ~]# setenforce 0[[email protected] ~]# vi /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
#SELINUX=enforcing
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted1.5 安裝ntp
ntp糾正系統時間。檢查
[[email protected] ~]# rpm -q ntp
未安裝軟體包 ntp [[email protected] ~]# yum -y install ntp[[email protected] ~]# systemctl enable ntpd[[email protected] ~]# systemctl start ntpd1.6 安裝JDK
解壓jdk
[[email protected] ~]# mkdir /soft/java
[[email protected] soft]# tar -zxvf jdk-7u79-linux-x64.tar.gz -C /soft/java/[[email protected] soft]# echo -e "\nexport JAVA_HOME=/soft/java/jdk1.7.0_79" >> /etc/profile[[email protected] soft]# echo -e "\nexport PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile[[email protected] soft]# echo -e "\nexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar" >> /etc/profile1.7 配置主機域名
1)master 192.168.174.132上操作[[email protected] soft]# hostname master
[[email protected] ~]# vi /etc/hostname
master2)node1 192.168.174.133上操作
[[email protected]alhost soft]# hostname node1
[[email protected] ~]# vi /etc/hostname
node1[[email protected] soft]# hostname node2
[[email protected] ~]# vi /etc/hostname
node21.8 配置hosts
3臺伺服器上都執行
[[email protected] ~]# echo '192.168.174.132 master' >> /etc/hosts
[[email protected] ~]# echo '192.168.174.133 node1' >> /etc/hosts
[[email protected] ~]# echo '192.168.174.134 node2' >> /etc/hosts1.9 ssh免密碼登入
master上操作
[[email protected] home]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
1d:33:50:ac:03:2f:d8:10:8f:3d:48:95:d3:f8:7a:05 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| oo.+.o. |
| ..== E.. |
| o++= o+ |
| . o.=..+ |
| oSo. |
| . . |
| . |
| |
| |
+-----------------+
[[email protected] home]# [[email protected] ~]# cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys檢查node1,node2上/root下,是否有.ssh目錄,沒有則建立,注意要有ll -a命令
node1,node2上操作
[[email protected] ~]# ll -a /root/
總用量 36
dr-xr-x---. 2 root root 4096 11月 16 17:31 .
dr-xr-xr-x. 18 root root 4096 11月 17 16:49 ..
-rw-------. 1 root root 953 11月 16 17:27 anaconda-ks.cfg
-rw-------. 1 root root 369 11月 17 18:12 .bash_history
-rw-r--r--. 1 root root 18 12月 29 2013 .bash_logout
-rw-r--r--. 1 root root 176 12月 29 2013 .bash_profile
-rw-r--r--. 1 root root 176 12月 29 2013 .bashrc
-rw-r--r--. 1 root root 100 12月 29 2013 .cshrc
-rw-r--r--. 1 root root 129 12月 29 2013 .tcshrc
[[email protected] ~]# mkdir /root/.sshmaster上操作
[[email protected] ~]# scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/
[[email protected] ~]# scp /root/.ssh/authorized_keys [email protected]:/root/.ssh/[[email protected] ~]# chmod 700 /root/.ssh驗證
master上操作
ssh master,ssh node1,ssh node2
[[email protected] .ssh]# ssh node1
Last failed login: Fri Nov 18 16:52:28 CST 2016 from master on ssh:notty
There were 2 failed login attempts since the last successful login.
Last login: Fri Nov 18 16:22:23 2016 from 192.168.174.1
[[email protected] ~]# logout
Connection to node1 closed.
[[email protected] .ssh]# ssh node2
The authenticity of host 'node2 (192.168.174.134)' can't be established.
ECDSA key fingerprint is 95:76:9a:bc:ef:5e:f2:b3:cf:35:67:7a:3e:da:0e:e2.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node2' (ECDSA) to the list of known hosts.
Last failed login: Fri Nov 18 16:57:12 CST 2016 from master on ssh:notty
There was 1 failed login attempt since the last successful login.
Last login: Fri Nov 18 16:22:40 2016 from 192.168.174.1
[[email protected] ~]# logout
Connection to node2 closed.
[[email protected] .ssh]# ssh master
Last failed login: Fri Nov 18 16:51:45 CST 2016 from master on ssh:notty
There was 1 failed login attempt since the last successful login.
Last login: Fri Nov 18 15:33:56 2016 from 192.168.174.1
[[email protected] ~]# 2.配置hadoop叢集
下面操作,若無特別指明,均是3臺伺服器都執行操作。
2.1 解壓
[[email protected] soft]# mkdir -p /soft/hadoop/
[[email protected] soft]# tar -zxvf hadoop-2.7.3.tar.gz -C /soft/hadoop/2.2 配置環境
[[email protected] hadoop-2.7.3]# echo "export HADOOP_HOME=/soft/hadoop/hadoop-2.7.3'" >> /etc/profile
[[email protected] hadoop-2.7.3]# echo -e "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> /etc/profile[[email protected] hadoop-2.7.3]# source /etc/profile
[[email protected] hadoop-2.7.3]# hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /soft/hadoop/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar
[[email protected] hadoop-2.7.3]# 修改hadoop配置檔案
hadoop-env.sh,yarn-env.sh增加JAVA_HOME配置
[[email protected] soft]# echo -e "export JAVA_HOME=/soft/java/jdk1.7.0_79" >> /soft/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
[[email protected] soft]# echo -e "export JAVA_HOME=/soft/java/jdk1.7.0_79" >> /soft/hadoop/hadoop-2.7.3/etc/hadoop/yarn-env.sh建立目錄/hadoop,/hadoop/tmp,/hadoop/hdfs/data,/hadoop/hdfs/name
[[email protected] hadoop]# mkdir -p /hadoop/tmp
[[email protected] hadoop]# mkdir -p /hadoop/hdfs/data
[[email protected] hadoop]# mkdir -p /hadoop/hdfs/name修改core-site.xml檔案
vi /soft/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>vi /soft/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>[[email protected] hadoop]# cd /soft/hadoop/hadoop-2.7.3/etc/hadoop/
[[email protected] hadoop]# cp mapred-site.xml.template mapred-site.xml
[[email protected] hadoop]# vi mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
</configuration> <property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>[[email protected] hadoop]# echo -e "node1\nnode2" > /soft/hadoop/hadoop-2.7.3/etc/hadoop/slaves 2.3 啟動
只在master執行,格式化
[[email protected] hadoop]# cd /soft/hadoop/hadoop-2.7.3/bin/
[[email protected] bin]# ./hadoop namenode -format啟動,只在master執行
[[email protected] bin]# cd /soft/hadoop/hadoop-2.7.3/sbin/
[[email protected] sbin]# ./start-all.sh2.4 驗證
master
[[email protected] sbin]# jps
3337 Jps
2915 SecondaryNameNode
3060 ResourceManager
2737 NameNode
[[email protected] sbin]# node1
[[email protected] hadoop]# jps
2608 DataNode
2806 Jps
2706 NodeManager
[[email protected] hadoop]# node2
[[email protected] hadoop]# jps
2614 DataNode
2712 NodeManager
2812 Jps
[[email protected] hadoop]# 瀏覽器訪問master的50070,比如http://192.168.174.132:50070
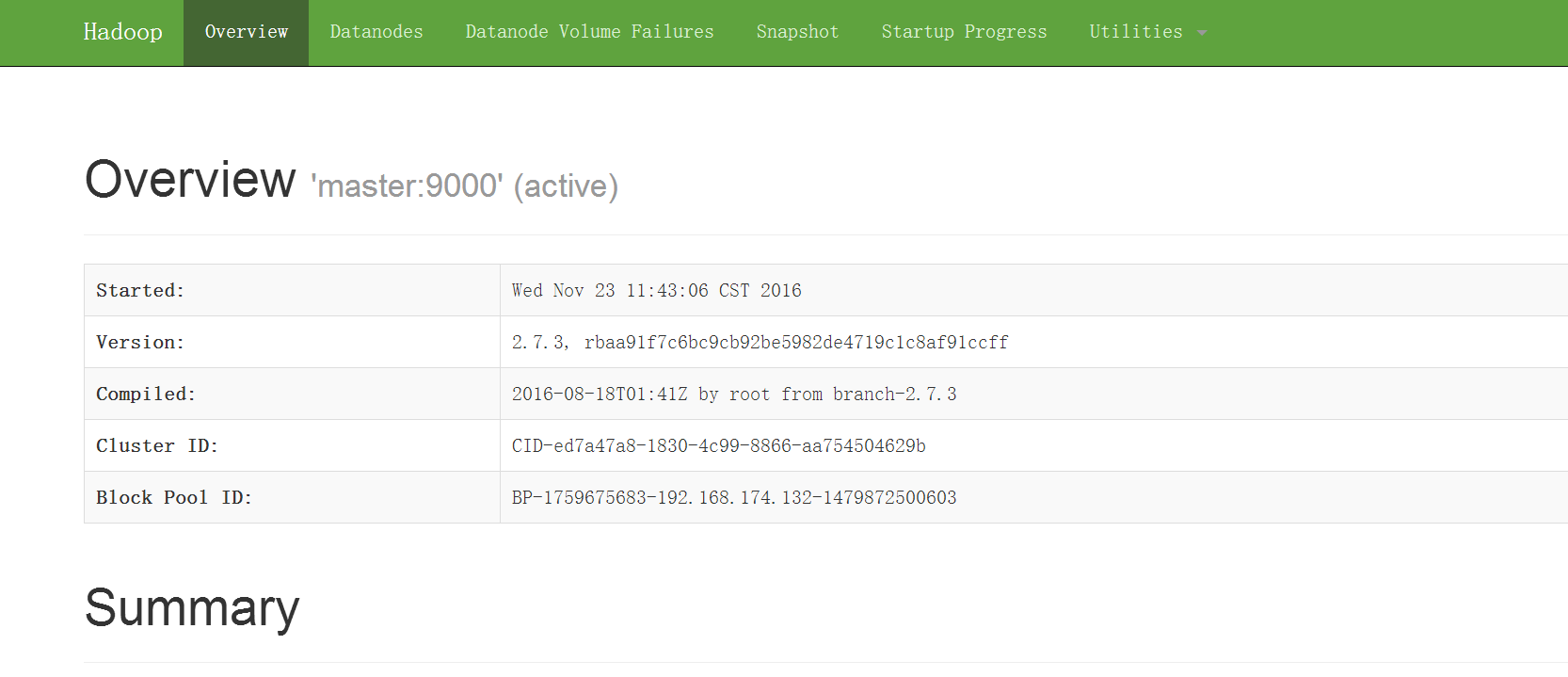
http://192.168.174.132:8088/
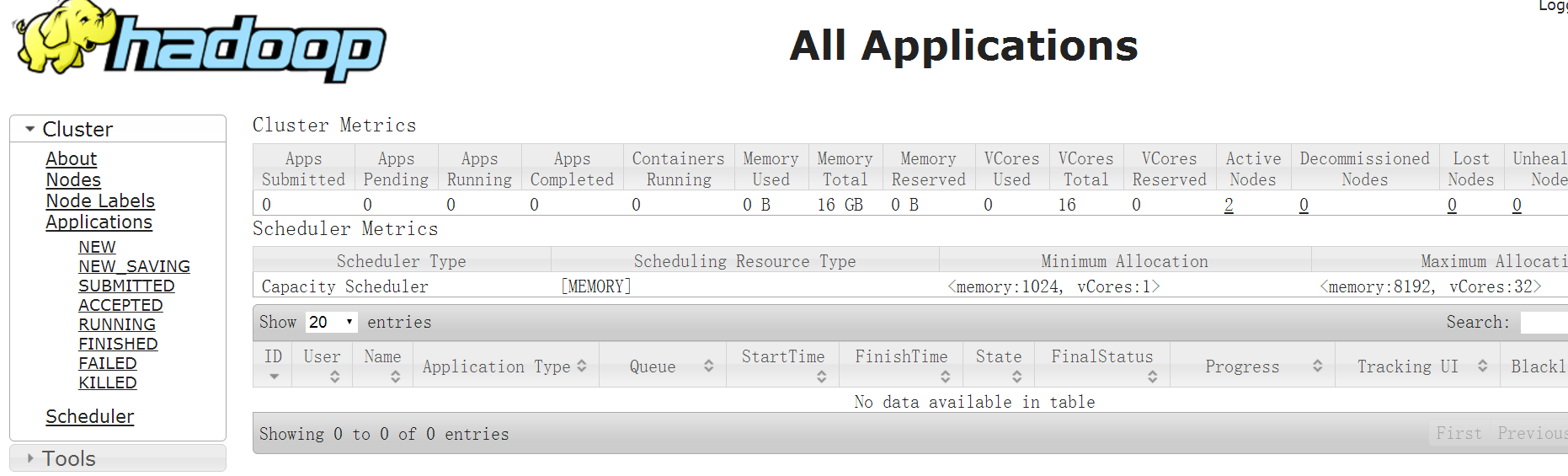
好了,說明hadoop叢集正常工作了
2.5 停止
[[email protected] bin]# cd /soft/hadoop/hadoop-2.7.3/sbin/
[[email protected] sbin]# ./stop-all.sh相關推薦
hadoop學習1--hadoop2.7.3叢集環境搭建
下面的部署步驟,除非說明是在哪個伺服器上操作,否則預設為在所有伺服器上都要操作。為了方便,使用root使用者。 1.準備工作 1.1 centOS7伺服器3臺 master 192.168.174.132 node1
CentOS 6.5 hadoop 2.7.3 叢集環境搭建
CentOS 6.5 hadoop 2.7.3 叢集環境搭建 所需硬體,軟體要求 使用 virtualbox 構建三臺虛擬機器模擬真實物理環境 作業系統:CentOS6.5 主機列表: master ip: 192.168.3.171 slav
Ubuntu + Hadoop2.7.3叢集搭建
先搭建Hadoop偽分佈: Ubuntu + Hadoop2.7.3偽分佈搭建 1.修改/etc/hosts檔案,IP對映 內容如下: 注:10.13.7.72為master節點IP,10.13.7.71為slave節點IP。(根據自己的IP地址設定) 2.修改maste
centos7 搭建ha(高可用)hadoop2.7.3叢集
寫在前面 作為一個單體應用開發人員對於理解分散式應用和微服務的理論還可以。但是部署分散式環境來說還是一個挑戰。最近在學習hadoop,正也把學習的東西分享出來,希望幫助感興趣的人。 前面一章寫了centos7搭建hadoop叢集 再跟著做本章實驗前建議初學
myeclipse下搭建hadoop2.7.3開發環境
感謝分享:http://www.cnblogs.com/duking1991/p/6056923.html 需要下載的檔案:連結:http://pan.baidu.com/s/1i5yRyuh 密碼:ms91 一 下載並編譯 hadoop-eclipse-plu
Hyperledger Fabric v1.1 單機多節點叢集環境搭建
Fabric v1.1 1.環境安裝 1).安裝go 1.9.x 下載地址 http://golang.org/dl/ 配置環境 #go的安裝根目錄 export GOROOT=/usr/local/go #go的工作路徑根目錄 export GOPAT
Ubuntu + Hadoop2.7.3偽分佈搭建
1.在virtualbox上設定共享目錄 將 JDK 和 hadoop 壓縮包上傳到Ubuntu: 參考連結:https://blog.csdn.net/qq_38038143/article/details/83017877 2.JDK安裝 在 /usr/loca
(一)大資料-Hadoop2.7.3偽分佈搭建
關閉防火牆 關閉當前登陸防火牆 檢視防火牆狀態 service iptables status 關閉防火牆 service iptables stop 關閉系統防火牆(即系統啟動時,不開啟防火牆) 檢視系統啟動 chkconfig --list 關閉系統啟動防火牆 chkconfig iptables o
大資料(Hadoop2.7.3偽分佈搭建)
安裝準備: vmware10 Centos6.5 64位版本 JDK1.8linux32位版 Hadoop2.7.3版
大資料學習環境搭建(CentOS6.9+Hadoop2.7.3+Hive1.2.1+Hbase1.3.1+Spark2.1.1)
node1192.168.1.11node2192.168.1.12node3192.168.1.13備註NameNodeHadoopYY高可用DateNode YYYResourceManager YY高可用NodeManagerYYYJournalNodes YYY奇數個,至少3個節點ZKFC(DFSZK
hadoop學習之路(一)---叢集環境搭建(2.7.3版本)
三:下載解壓 hadoop 到某個目錄(例如 /usr/loacl/hadoop) 四:賬號建立: 即為hadoop叢集專門設定一個使用者組及使用者,這部分比較簡單,參考示例如下: groupadd hadoop //設定h
(學習筆記版)Hadoop入門(一):Hadoop2.7.3完全分布式集群安裝
min property per cal mon 分別是 master 修改 node 在這裏寫下安裝hadoop2.7.3版本的完全分布式的過程,因為剛開始學習hadoop不久,希望自己把學習的東西記錄下來,和大家一起分享,可能有錯誤的地方,還請大牛們批評指正,在我學習的
01_PC單機Spark開發環境搭建_JDK1.8+Spark2.3.1+Hadoop2.7.1
tor 環境 eve exe ring row test source 分享圖片 本文檔基於Windows搭建本地JAVA Spark開發環境。 1 JDK 1.8安裝 官網下載JDK。 註意JDK安裝目錄不可以包含空格,比如:C:\Java\jdk1.8.
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分散式叢集環境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分散式叢集環境 一、環境說明 個人理解:zookeeper可以獨立搭建叢集,hbase本身不能獨立搭建叢集需要和hadoop和hdfs整合 叢集環境至少需要3個節點(也就是3臺伺服器裝置):1個Master,2
Hadoop2.7.3 HA高可靠性叢集搭建(Hadoop+Zookeeper)
一.概述 在hadoop1時代,只有一個NameNode。如果該NameNode資料丟失或者不能工作,那麼整個叢集就不能恢復了。這是hadoop1中的單點問題,也是hadoop1不可靠的表現。
Spark之——Hadoop2.7.3+Spark2.1.0 完全分散式環境 搭建全過程
一、修改hosts檔案在主節點,就是第一臺主機的命令列下;vim /etc/hosts我的是三臺雲主機:在原檔案的基礎上加上;ip1 master worker0 namenode ip2 worker1 datanode1 ip3 worker2 datanode2其中的i
在VM虛擬機器上搭建Hadoop2.7.3+Spark2.1.0完全分散式叢集
1.選取三臺伺服器(CentOS系統64位) 114.55.246.88主節點 114.55.246.77 從節點 114.55.246.93 從節點 之後的操作如果是用普通使用者操作的話也必須知道root使用者的密碼,因為有些操作是得
Hadoop-2.7.1叢集環境搭建
摘自:http://blog.csdn.net/u014039577/article/details/49813531 由於日誌資料量越來越大,資料處理的邏輯越來越複雜,同時還涉及到大量日誌需要批處理,當前的flume-kafka-storm-Hbase-web這一套流程已經不能滿足當前的需求了,所以只
Hadoop2.7.1+Hbase1.2.1叢集環境搭建(1)hadoop2.7.1原始碼編譯
官網目前提供的下載包為32位系統的安裝包,在linux 64位系統下安裝後會一直提示錯誤“WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-j
hadoop學習之HIVE(3.2):hadoop2.7.2下配置hiveserver2啟動遠端連線
./hive只是啟動本地客戶端,往往用來測試,我們可以啟動hive server2伺服器用於遠端連線,方便開發。 前提是配置好hadoop和hive 1,開啟hive server服務:bin/hiveserver2 可檢視服務是否開啟:netstat -nplt |