
4.4.2分類模型評判指標(一)
簡介
混淆矩陣是ROC曲線繪製的基礎,同時它也是衡量分型別模型準確度中最基本,最直觀,計算最簡單的方法。
一句話解釋版本:
混淆矩陣就是分別統計分類模型歸錯類,歸對類的觀測值個數,然後把結果放在一個表裡展示出來。這個表就是混淆矩陣。
資料分析與挖掘體系位置
混淆矩陣是評判模型結果的指標,屬於模型評估的一部分。此外,混淆矩陣多用於判斷分類器(Classifier)的優劣,適用於分型別的資料模型,如分類樹(Classification Tree)、邏輯迴歸(Logistic Regression)、線性判別分析(Linear Discriminant Analysis)等方法。
在分型別模型評判的指標中,常見的方法有如下三種:
- 混淆矩陣(也稱誤差矩陣,Confusion Matrix)
- ROC曲線
- AUC面積
本篇主要介紹第一種方法,即混淆矩陣,也稱誤差矩陣。
此方法在整個資料分析與挖掘體系中的位置如下圖所示。

混淆矩陣的定義
混淆矩陣(Confusion Matrix),它的本質遠沒有它的名字聽上去那麼拉風。矩陣,可以理解為就是一張表格,混淆矩陣其實就是一張表格而已。
以分類模型中最簡單的二分類為例,對於這種問題,我們的模型最終需要判斷樣本的結果是0還是1,或者說是positive還是negative。
我們通過樣本的採集,能夠直接知道真實情況下,哪些資料結果是positive,哪些結果是negative。同時,我們通過用樣本資料跑出分型別模型的結果,也可以知道模型認為這些資料哪些是positive,哪些是negative。
因此,我們就能得到這樣四個基礎指標,我稱他們是一級指標(最底層的):
- 真實值是positive,模型認為是positive的數量(True Positive=TP)
- 真實值是positive,模型認為是negative的數量(False Negative=FN):這就是統計學上的第一類錯誤(Type I Error)
- 真實值是negative,模型認為是positive的數量(False Positive=FP):這就是統計學上的第二類錯誤(Type II Error)
- 真實值是negative,模型認為是negative的數量(True Negative=TN)
將這四個指標一起呈現在表格中,就能得到如下這樣一個矩陣,我們稱它為混淆矩陣(Confusion Matrix):

混淆矩陣的指標
預測性分類模型,肯定是希望越準越好。那麼,對應到混淆矩陣中,那肯定是希望TP與TN的數量大,而FP與FN的數量小。所以當我們得到了模型的混淆矩陣後,就需要去看有多少觀測值在第二、四象限對應的位置,這裡的數值越多越好;反之,在第一、三四象限對應位置出現的觀測值肯定是越少越好。
二級指標
但是,混淆矩陣裡面統計的是個數,有時候面對大量的資料,光憑算個數,很難衡量模型的優劣。因此混淆矩陣在基本的統計結果上又延伸瞭如下4個指標,我稱他們是二級指標(通過最底層指標加減乘除得到的):
- 準確率(Accuracy)—— 針對整個模型
- 精確率(Precision)
- 靈敏度(Sensitivity):就是召回率(Recall)
- 特異度(Specificity)
我用表格的方式將這四種指標的定義、計算、理解進行了彙總:
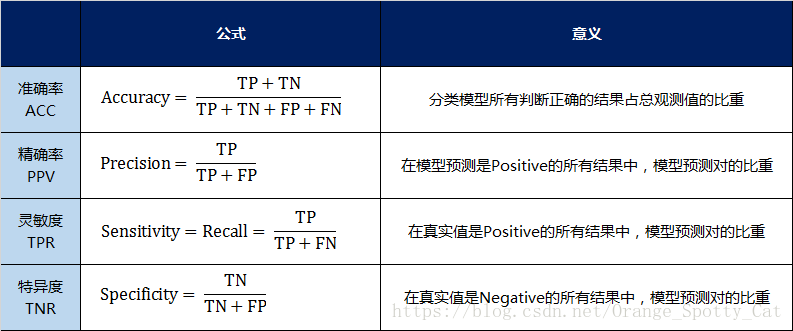
通過上面的四個二級指標,可以將混淆矩陣中數量的結果轉化為0-1之間的比率。便於進行標準化的衡量。
在這四個指標的基礎上在進行拓展,會產令另外一個三級指標
三級指標
這個指標叫做F1 Score。他的計算公式是:
其中,P代表Precision,R代表Recall。
F1-Score指標綜合了Precision與Recall的產出的結果。F1-Score的取值範圍從0到1的,1代表模型的輸出最好,0代表模型的輸出結果最差。
混淆矩陣的例項
當分類問題是二分問題是,混淆矩陣可以用上面的方法計算。當分類的結果多於兩種的時候,混淆矩陣同時適用。
一下面的混淆矩陣為例,我們的模型目的是為了預測樣本是什麼動物,這是我們的結果:
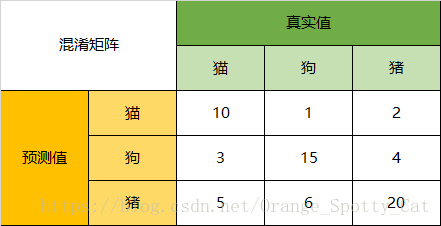
通過混淆矩陣,我們可以得到如下結論:
Accuracy
在總共66個動物中,我們一共預測對了10 + 15 + 20=45個樣本,所以準確率(Accuracy)=45/66 = 68.2%。
以貓為例,我們可以將上面的圖合併為二分問題:
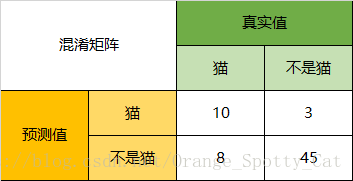
Precision
所以,以貓為例,模型的結果告訴我們,66只動物裡有13只是貓,但是其實這13只貓只有10只預測對了。模型認為是貓的13只動物裡,有1條狗,兩隻豬。所以,Precision(貓)= 10/13 = 76.9%
Recall
以貓為例,在總共18只真貓中,我們的模型認為裡面只有10只是貓,剩下的3只是狗,5只都是豬。這5只八成是橘貓,能理解。所以,Recall(貓)= 10/18 = 55.6%
Specificity
以貓為例,在總共48只不是貓的動物中,模型認為有45只不是貓。所以,Specificity(貓)= 45/48 = 93.8%。
雖然在45只動物裡,模型依然認為錯判了6只狗與4只貓,但是從貓的角度而言,模型的判斷是沒有錯的。
(這裡是參見了Wikipedia,Confusion Matrix的解釋,https://en.wikipedia.org/wiki/Confusion_matrix)
F1-Score
通過公式,可以計算出,對貓而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
同樣,我們也可以分別計算豬與狗各自的二級指標與三級指標值。
ROC曲線在R中的實現
library(ISLR)
cor(Smarket[,-9])
attach(Smarket)
# logistic Model
model_LR <- glm(Direction ~ Lag1 + Lag2 + Lag3 + Lag4 + Lag5 + Volume,
family = binomial,
data = Smarket)
# Make prediction
prob_LR <- predict(model_LR, type = 'response', newdata = Smarket[1:300,])
prob_LR <- predict(model_LR, type = 'response', newdata = Smarket[,])
# create a vector of class predictions based on wether the predicted probability of a market increase is greater than or less than 0.5
pred_LR <- rep("Down" , 1250)
pred_LR[prob_LR > 0.5] = 'Up'
# Confusion Matrix
table(pred_LR, Direction)
相關推薦
4.4.2分類模型評判指標(一)
簡介混淆矩陣是ROC曲線繪製的基礎,同時它也是衡量分型別模型準確度中最基本,最直觀,計算最簡單的方法。一句話解釋版本:混淆矩陣就是分別統計分類模型歸錯類,歸對類的觀測值個數,然後把結果放在一個表裡展示出來。這個表就是混淆矩陣。資料分析與挖掘體系位置混淆矩陣是評判模型結果的指標
4.4.2分類模型評判指標(三)
簡介 KS曲線是用來衡量分型別模型準確度的工具。KS曲線與ROC曲線非常的類似。其指標的計算方法與混淆矩陣、ROC基本一致。它只是用另一種方式呈現分類模型的準確性。KS值是KS圖中兩條線之間最大的距離,其能反映出分類器的劃分能力。 一句話概括版本: KS曲線是兩條線,其
顯著性目標檢測模型評價指標(一)——平均絕對誤差:Mean Absolute Error(MAE)
顯著性目標檢測模型評價指標 之 平均絕對誤差(MAE)原理與實現程式碼 目錄 一、顯著性目標檢測簡介 顯著性目標(Salient Object): 當我們在看一張圖片時,注意力首先會落在我們所感興趣的物體部分。比如我們看到一張畫有羊
二分類問題F-score評判指標(轉載)
ati ria 比例 csdn 但是 https 假設 tail rgb 小書匠深度學習分類方法常用的評估模型好壞的方法.
Swift 4 和 Objective-C 混合編程(一) 快速起步
命名方式 import 編譯器 選擇性 工程 Swift 4 和 Objective-C 在同一個工程裏的混搭編程的方法你可以在 xcode 裏同時使用 Swift 和 Objective-C(以下簡稱OC)來寫代碼,混搭編程的好處很多,比如允許大量代碼的復用,在性能和開發效率之間找到平衡
Webpack 4.X webpack.config.js 檔案配置(一)
通過上一篇文章,我們明白了webpack的兩個配置引數入口與出口,webpack會找到入口檔案的地址,進去後一頓蹂躪,再通過你給的輸出地址就把編譯後的檔案給你了。這篇文章接著去豐富webpack.config.js的內容,說一個引數叫plugins plugins plugins裡面放的是外掛,在webp
R語言︱機器學習模型評價指標+(轉)模型出錯的四大原因及如何糾錯
筆者寄語:機器學習中交叉驗證的方式是主要的模型評價方法,交叉驗證中用到了哪些指標呢?交叉驗證將資料分為訓練資料集、測試資料集,然後通過訓練資料集進行訓練,通過測試資料集進行測試,驗證集進行驗證。模型預測
顯著性目標檢測模型評價指標(二)——PR曲線
顯著性目標檢測模型評價指標 之 PR曲線原理與實現程式碼 目錄 一、PR曲線原理 在顯著目標提取中(關於視覺顯著性的簡要介紹點此處連結),PR曲線是用來評估模型效能的重要指標之一,PR曲線中的P(Precision)和R(Recall)分
Android4.4 CTS測試Fail項修改總結(一)
1、測試android.webkit.cts.GeolocationTest Fail 提示: cts-tf > run cts --class android.webkit.cts.GeolocationTest 12-13 16:55:23 I/TestInvo
藍芽4.0/BLE協議棧學習筆記(一)
需要的軟體工具: 1、BLE協議棧(BLE-CC254x-1.4.0) 2、IAR開發軟體(IAR Embedded Workbench8.20.2) 注:1.4.0協議棧使用8.2
《阿裏巴巴Java開發手冊1.4.0》閱讀總結與心得(一)
更新 java開發手冊 new 開發者 由於 阿裏巴巴 itl 一個bug 項目庫 前言 下面是阿裏對《阿裏巴巴 Java 開發手冊》(下稱《手冊》)的介紹: 凝聚了阿裏集團很多同學的知識智慧和經驗,這些經驗甚至是用血淋淋的故障換來的,希望前車之鑒,後車之師,能
編程題#2:奇偶排序(一)
ios -- cout 如果 cin art 數組 n) bool 描述 輸入十個整數,將十個整數按升序排列輸出,並且奇數在前,偶數在後。 輸入 輸入十個整數 輸出 按照奇偶排序好的十個整數 #include <iostream> using name
python 基礎 2.1 if 流程控制(一)
字符串 ace 冒號 rip inpu root 類型 真的 use 一.if else 1.if 語句 if expression: //註意if後有冒號,必須有 statement(s) //相對於if縮進4個空格 註:python
深度探索C++對象模型讀書筆記(一)
復雜 理解 image play 基礎上 isp 靜態 布局 bject 《深度探索C++對象模型》這本書也算是學習C++面向對象編程的必備書了,打算花上幾天先簡單的看一遍,這種書看上好幾遍也不一定能理解太多,慢慢積累一點一滴吃透就好。下面把我看書過程中覺得比較有意義的摘錄
zigbee 之ZStack-2.5.1a原始碼分析(一)
先看main, 在檔案Zmain.c裡面 main osal_init_system(); osalInitTasks(); ... ... SampleApp_Init( taskID ); // 使用者定義的任務
第2章 RFID基礎知識(一)
1.RFID即射頻識別。(常稱為電子標籤)RFID射頻識別是一種非接觸式的自動識別技術,識別高速運動物體並可同時識別多個標籤,識別距離可達幾十米。 2.RFID的組成:一套完整的RFID系統必須由標籤、閱讀器和天線組成。 3.電子標籤的分類:標籤類、注塑類、卡片類。 4.閱讀器與電子標籤之間的射頻訊
C++ 智慧指標(一)
記憶體安全 在C++中,動態記憶體的管理是通過一對運算子來完成的:new,在動態記憶體中為物件分配空間並返回一個指向該物件的指標,我們可以選擇對物件來進行初始化;delete,接收一個動態物件的指標,銷燬該物件,並釋放與之關聯的記憶體。 動態記憶體的使用很容易出問題,因為確保
caffe模型訓練全過程(一)指令碼、資料準備與製作
1.首先建立工程資料夾 資料夾結構如下 |——project ├── create_imagenet.sh #生成lmdb檔案的指令碼 |——train_lmdb ├── data.mdb └── lock.mdb
聊聊高併發(三十三)Java記憶體模型那些事(一)從一致性(Consistency)的角度理解Java記憶體模型
可以說併發系統要解決的最核心問題之一就是一致性的問題,關於一致性的研究已經有幾十年了,有大量的理論,演算法支援。這篇說說一致性這個主題一些經常提到的概念,理清Java記憶體模型在其中的位置。 一致性問題更準確的說是一致性需求,看系統需要什麼樣的一致性保證。比如分散式領域
Vue.js 2.0 教程精華梳理(一) 基礎
Vue.js 第一部分 Vue.js 介紹 Vue.js(讀音 /vjuː/, 類似於 view) 是一套構建使用者介面的 漸進式框架。與其他重量級框架不同的是,Vue 採用自底向上增量開發的設計。Vue 的核心庫只關注檢視層,並且非常容易學習,非常容易與其