
Python爬取qq音樂的過程例項
一、前言
qq music上的音樂還是不少的,有些時候想要下載好聽的音樂,但有每次在網頁下載都是煩人的登入什麼的。於是,來了個qqmusic的爬蟲。至少我覺得for迴圈爬蟲,最核心的應該就是找到待爬元素所在url吧。
二、Python爬取QQ音樂單曲


爬蟲步驟
1.確定目標
首先我們要明確目標,本次爬取的是QQ音樂歌手劉德華的單曲。
(百度百科)->分析目標(策略:url格式(範圍)、資料格式、網頁編碼)->編寫程式碼->執行爬蟲
2.分析目標
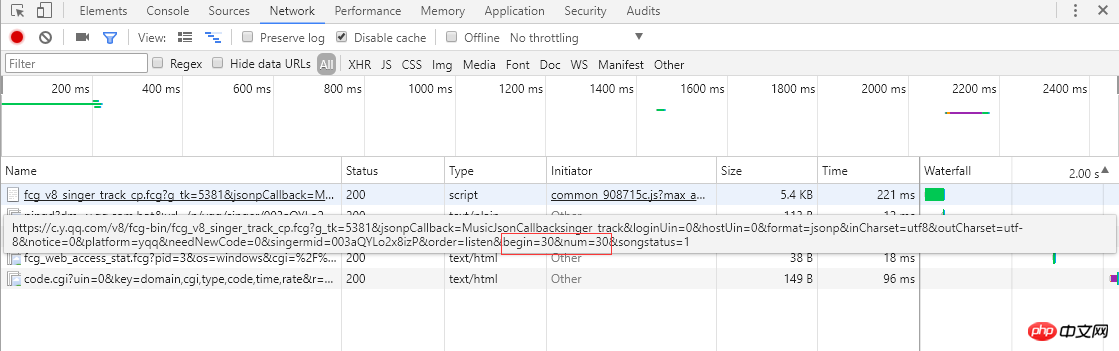
歌曲連結:
從左邊的截圖可以知道單曲採用分頁的方式排列歌曲資訊,每頁顯示30條,總共30頁。點選頁碼或者最右邊的">"會跳轉到下一頁,瀏覽器會向伺服器傳送ajax非同步請求,從連結可以看到begin和num引數,分別代表起始歌曲下標(截圖是第2頁,起始下標是30)和一頁返回30條,伺服器響應返回json格式的歌曲資訊(MusicJsonCallbacksinger_track({"code":0,"data":{"list":[{"Flisten_count1":......]})),如果只是單獨想獲取歌曲資訊,可以直接拼接連結請求和解析返回的json格式的資料。這裡不採用直接解析資料格式的方法,我採用的是Python Selenium方式,每獲取和解析完一頁的單曲資訊,點選 ">" 跳轉到下一頁繼續解析,直至解析並記錄所有的單曲資訊。最後請求每個單曲的連結,獲取詳細的單曲資訊。
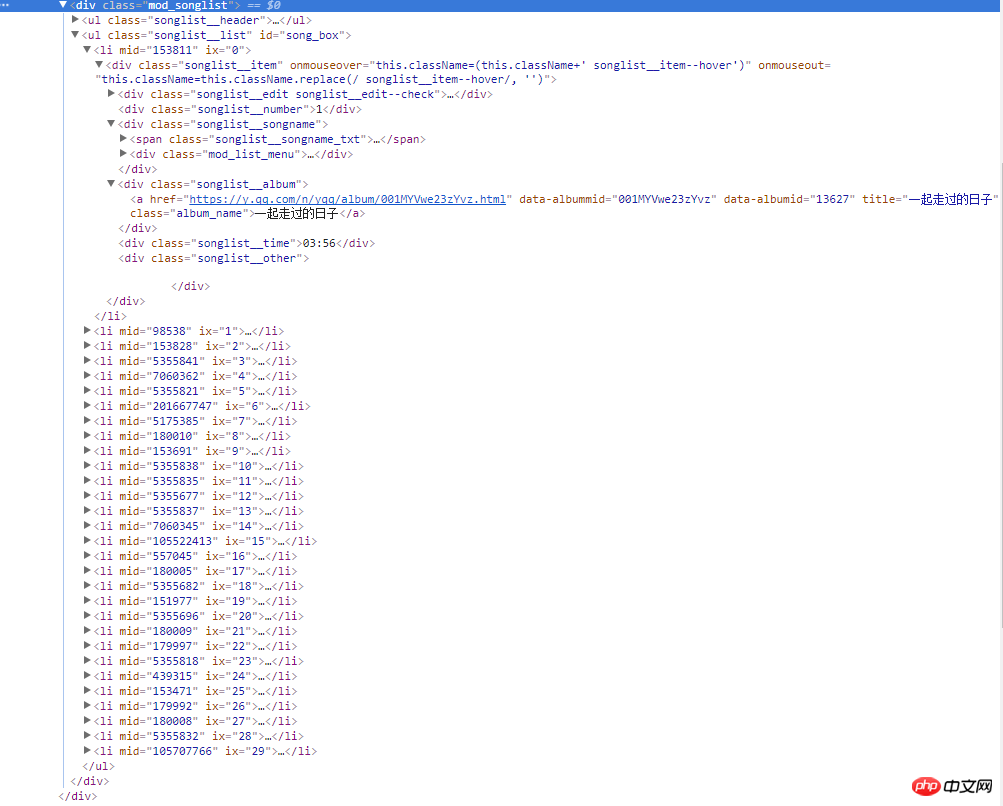
右邊的截圖是網頁的原始碼,所有歌曲資訊都在類名為mod_songlist的div浮層裡面,類名為songlist_list的無序列表ul下,每個子元素li展示一個單曲,類名為songlist__album下的a標籤,包含單曲的連結,名稱和時長等。
3.編寫程式碼
1)下載網頁內容,這裡使用Python 的Urllib標準庫,自己封裝了一個download方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
'wswp', num_retries=2):
}
|
2)解析網頁內容,這裡使用第三方外掛BeautifulSoup,具體可以參考BeautifulSoup API 。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
4.執行爬蟲
| 1 |
|
| 1 |
|
三、Python爬取QQ音樂單曲總結
1.單曲採用的是分頁方式,切換下一頁是通過非同步ajax請求從伺服器獲取json格式的資料並渲染到頁面,瀏覽器位址列連結是不變的,不能通過拼接連結來請求。一開始想過都通過Python Urllib庫來模擬ajax請求,後來想想還是用Selenium。Selenium能夠很好地模擬瀏覽器真實的操作,頁面元素定位也很方便,模擬單擊下一頁,不斷地切換單曲分頁,再通過BeautifulSoup解析網頁原始碼,獲取單曲資訊。
2.url連結管理器,採用集合資料結構來儲存單曲連結,為什麼要使用集合?因為多個單曲可能來自同一專輯(專輯網址一樣),這樣可以減少請求次數。
| 1 |
|
| 1 |
|
3.通過Python第三方外掛openpyxl讀寫Excel十分方便,把單曲資訊通過Excel檔案可以很好地儲存起來。
| 1 |
|
四、後語
最後還是要慶祝下,畢竟成功把QQ音樂的單曲資訊爬取下來了。本次能夠成功爬取單曲,Selenium功不可沒,這次只是用到了selenium一些簡單的功能,後續會更加深入學習Selenium,不僅在爬蟲方面還有UI自動化。
後續還需要優化的點:
1.下載的連結比較多,一個一個下載起來比較慢,後面打算用多執行緒併發下載。
2.下載速度過快,為了避免伺服器禁用IP,後面還要對於同一域名訪問過於頻繁的問題,有個等待機制,每個請求之間有個等待間隔。
3. 解析網頁是一個重要的過程,可以採用正則表示式,BeautifulSoup和lxml,目前採用的是BeautifulSoup庫, 在效率方面,BeautifulSoup沒lxml效率高,後面會嘗試採用lxml。