
利用python爬取豆瓣音樂TOP250
最近無所事事,在逼乎看到別人爬取了豆瓣電影,發現挺適合我這菜雞練練手
所以我來爬音樂。。
#對不起豆瓣,又是爬你。。
目標網站:https://music.douban.com/top250?start=0
首先正常瀏覽分析網頁
開啟網址,點選下一頁,發現網站URL變成 https://music.douban.com/top250?start=25,所以可以判斷接下來每一頁的URL為 star=25*i。
所以先確定總URL
urls = ['https://music.douban.com/top250?start={}'.format(str(i)) for i in range(0, 250, 25)]檢視網頁原始碼,部分如下
<p class="ul first"></p> <table width="100%%"> <tr class="item"> <td width="100" valign="top"> <a class="nbg" href="https://music.douban.com/subject/2995812/" onclick="moreurl(this,{i:'0',query:'',subject_id:'2995812',from:'music_subject_search'})" title="Jason Mraz - We Sing. We Dance. We Steal Things." > <img src="https://img3.doubanio.com/spic/s2967252.jpg" alt="Jason Mraz - We Sing. We Dance. We Steal Things."/></a> </td> <td valign="top"> <div class="pl2"> <a href="https://music.douban.com/subject/2995812/" onclick="moreurl(this,{i:'0',query:'',subject_id:'2995812',from:'music_subject_search'})" > We Sing. We Dance. We Steal Things. </a> <p class="pl">Jason Mraz / 2008-05-13 / Import / Audio CD / 民謠</p> <div class="star clearfix"><span class="allstar45"></span><span class="rating_nums">9.1</span> <span class="pl"> ( 100208人評價 ) </span></div> </div> </td> </tr> </table><div id="collect_form_2995812"></div>
發現在每個名字為a,屬性為nbg的標籤下有對應的歌曲資訊,而且該標籤的href是一個URL,出於
所以,為了得到每首歌詳細頁面的URL,我們需要查詢所有所有符合條件的a標籤,程式碼如下
得到每首歌曲詳細資訊頁面的網站後,就爬取該頁面r = requests.get(url,headers = headers) #得到respons物件 soup = BeautifulSoup(r.text,'lxml') #得到soup物件,沒安裝lxml模組的可以改成html.parser music_hrefs = soup.select('a.nbg') #查詢每個符合條件的a標籤,返回一個列表
同樣先檢視網頁原始碼
先找歌曲名
<h1>
<span>We Sing. We Dance. We Steal Things.</span>
<div class="clear"></div>
</h1>name = soup.select('h1 > span')接下來提取其他資訊
發現其他資訊集中在一起,網頁程式碼如下
<div id="info" class="ckd-collect">
<span>
<span class="pl">
表演者:
<a href="/search?q=Jason%20Mraz&sid=2995812">Jason Mraz</a>
</span>
</span>
<br/>
<span class="pl">流派:</span> 民謠
<br />
<span class="pl">專輯型別:</span> Import
<br />
<span class="pl">介質:</span> Audio CD
<br />
<span class="pl">發行時間:</span> 2008-05-13
<br />
找作者:
author = soup.find_all(href = re.compile('/search?')) #不想苦苦分析關係,直接找符合關係的標籤,re就是好找風格:
musictype = re.findall(r'<span class="pl">流派:</span> (.*?)<br />',r.text,re.S)其他類似
需要注意的是,無論是select還是find_all,返回的都是列表,select返回的列表中的元素為Tag,需要用get_text()得到字元部分,而find_all用下標即可
接下來貼出完整程式碼
import requests
import lxml
from bs4 import BeautifulSoup
import time
import re
import csv
import os
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
def geturl(url,writer):
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,'lxml')
music_hrefs = soup.select('a.nbg')
for music_href in music_hrefs:
getmusic(music_href['href'],writer)
def getmusic(url,writer):
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,'lxml')
name = soup.select('h1 > span')
if len(name) == 0:
name = '未知'
else:
name = name[0].get_text()
author = soup.find_all(href = re.compile('/search?'))
if len(author) == 0:
author = '佚名'
else:
author = author[0].get_text()
musictype = re.findall(r'<span class="pl">流派:</span> (.*?)<br />',r.text,re.S)#[0].split('\n')[0]
if len(musictype) == 0:
musictype = '未知'
else:
musictype = musictype[0].split('\n')[0] #為了使資料更好看。。
musictime = re.findall(r'<span class="pl">發行時間:</span> (.*?)<br />',r.text,re.S)#[0].split('\n')[0]
if len(musictime) == 0:
musictime = '未知'
else:
musictime = musictime[0].split('\n')[0] #為了使資料更好看。。
'''info = {
'name': name,
'author': author,
'style': musictype,
'time': musictime,
}'''
writer.writerow((name,author,musictype,musictime))
def main():
os.chdir(r'C:\Users\zhu\Desktop')
f = open('csv.csv','w',encoding='utf-8',newline='') #編碼設定為utf-8,不然爬取下來有些會亂碼
writer = csv.writer(f)
writer.writerow(('歌名','作者','風格','時間')) #寫入csv檔案
urls = ['https://music.douban.com/top250?start={}'.format(str(i)) for i in range(0, 250, 25)]
for url in urls:
geturl(url,writer)
print("papapa") #為了告訴你程式是在執行的。。。
f.close()
print("爬取完成")
main()爬取效果:
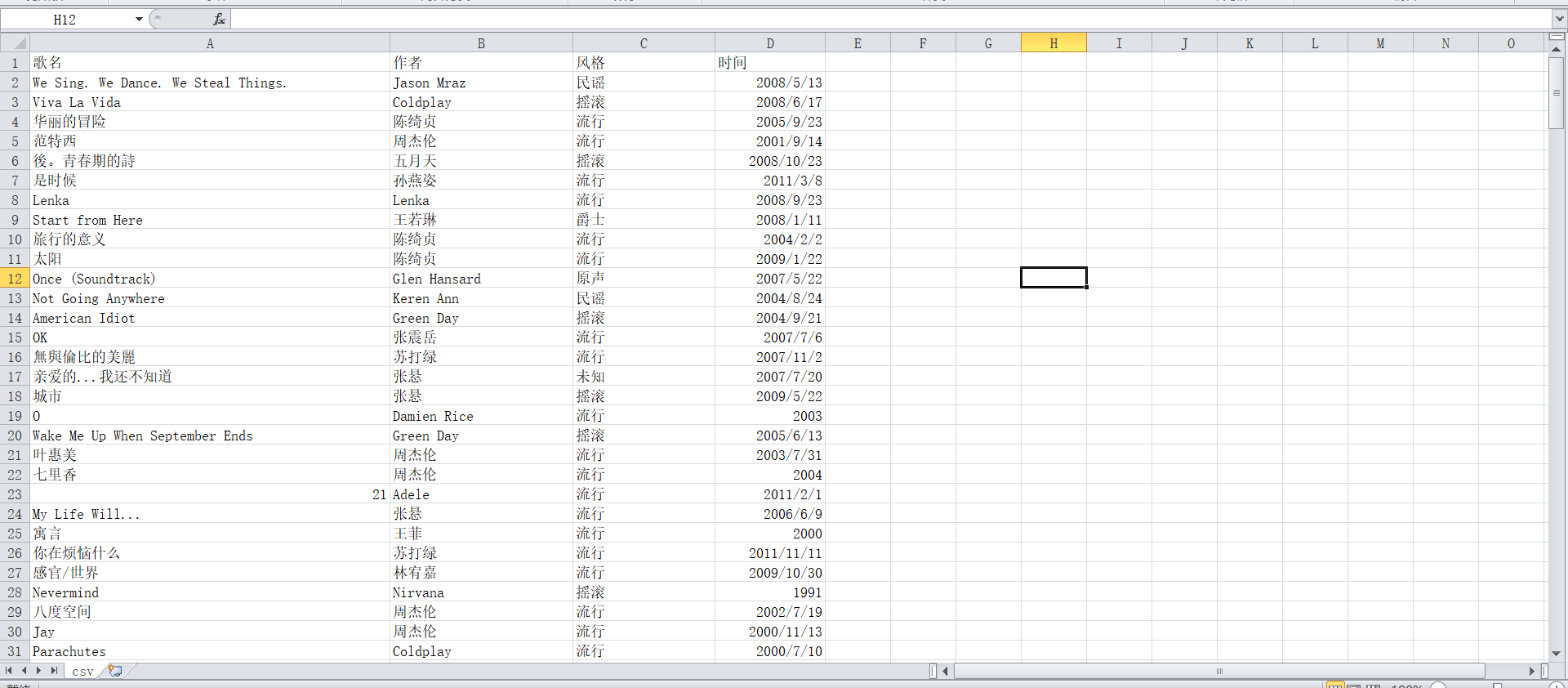
第一次記錄自己學習的東西
要是哪裡寫的不對
你來打我啊
(歡迎大佬指正。。)
為了讓爬取資料更直觀,接下來我們要可以進行資料分析,生成什麼餅圖,直方圖什麼的
好吧,其實接下來我就不會了
END
相關推薦
利用python爬取豆瓣音樂TOP250
最近無所事事,在逼乎看到別人爬取了豆瓣電影,發現挺適合我這菜雞練練手 所以我來爬音樂。。 #對不起豆瓣,又是爬你。。 目標網站:https://music.douban.com/top250?start=0 首先正常瀏覽分析網頁 開啟網址,點選下一頁,發現網站URL變成
Python爬蟲實戰(3)-爬取豆瓣音樂Top250資料(超詳細)
前言 首先我們先來回憶一下上兩篇爬蟲實戰文章: 第一篇:講到了requests和bs4和一些網頁基本操作。 第二篇:用到了正則表示式-re模組 今天我們用lxml庫和xpath語法來爬蟲實戰。 1.安裝lxml庫 window:直接用pip去
[Python/爬蟲]利用xpath爬取豆瓣電影top250
今天學習了一下xpath 感覺功能非常的強大,但是如果不太懂前端的小夥伴們可能比較吃力,建議看一下html的一些語法結構,程式碼如下: #!/usr/bin/env python import r
python爬取豆瓣電影Top250的資訊
python爬取豆瓣電影Top250的資訊 2018年07月25日 20:03:14 呢喃無音 閱讀數:50 python爬取豆瓣電影Top250的資訊。 初學,所以程式碼的不夠美觀和精煉。 如果程式碼有錯,請各位讀者在評論區評論,以免誤導其他同學。 (
教你用Python爬取豆瓣圖書Top250
質量、速度、廉價,選擇其中兩個 這篇文章將會用到上一篇文章所講的內容,如果沒有看過可以去看一下教你用Python寫excel 今天我們要做的就是用Python爬取豆瓣圖書Top250,先開啟網站看一下 今天不談這豆瓣圖書top250垃圾不垃圾的問題,只看看怎麼用p
python爬取豆瓣電影top250
簡要介紹: 爬取豆瓣電影top250上相關電影的資訊,包括影片連結、影片名稱、上映時間、排名、豆瓣評分、導演、劇情簡介。 使用:requests、etree、xpath 1、檢視網頁資訊,確定爬取的內容,建立資料庫: class SpiderData(pe
爬取豆瓣音樂Top250並存入xls
import requests from bs4 import BeautifulSoup import re import xlwt class DoubanMusic: def __ini
爬蟲]利用xpath爬取豆瓣電影top250(轉)
今天學習了一下xpath 感覺功能非常的強大,但是如果不太懂前端的小夥伴們可能比較吃力,建議看一下html的一些語法結構,程式碼如下: #!/usr/bin/env python import re import requests import lxml.html url
Python爬取豆瓣電影Top250資料
初學pyhton,自己找個練手任務。爬取豆瓣電影top250,儲存為一個DataFrame資料格式,留待分析.(程式碼粗糙,留存) from bs4 import BeautifulSoup from urllib.request import url
用python爬取豆瓣電影TOP250獲取電影排名、電影名稱、電影別名、電影連結、導演、主演、年份、地點、型別、評分、評價人數、摘要、海報下載地址。
python小白,第一次爬蟲,如有不對的地方還請多多指出。用BeautifulSoup獲取電影排名、電影名稱、電影別名、電影連結、導演、主演、年份、地點、型別、評分、評價人數、摘要、海報下載地址。cur_url:每一頁的地址,例如:https://movie.douban.c
Python網路爬蟲:利用正則表示式爬取豆瓣電影top250排行前10頁電影資訊
在學習了幾個常用的爬取包方法後,轉入爬取實戰。 爬取豆瓣電影早已是練習爬取的常用方式了,網上各種程式碼也已經很多了,我可能現在還在做這個都太土了,不過沒事,畢竟我也才剛入門…… 這次我還是利用正則表示式進行爬取,怎麼說呢,有人說寫正則表示式很麻煩,很多人都不
Python爬蟲之利用BeautifulSoup爬取豆瓣小說(三)——將小說信息寫入文件
設置 one 行為 blog 應該 += html uil rate 1 #-*-coding:utf-8-*- 2 import urllib2 3 from bs4 import BeautifulSoup 4 5 class dbxs: 6 7
Python爬蟲:現學現用Xpath爬取豆瓣音樂
9.1 tree when href scrapy 發現 pat 直接 where 爬蟲的抓取方式有好幾種,正則表達式,Lxml(xpath)與Beautiful,我在網上查了一下資料,了解到三者之間的使用難度與性能 三種爬蟲方式的對比。 抓取方式 性能 使用難度
案例學python——案例三:豆瓣電影資訊入庫 一起學爬蟲——通過爬取豆瓣電影top250學習requests庫的使用
閒扯皮 昨晚給高中的妹妹微信講題,函式題,小姑娘都十二點了還迷迷糊糊。今天凌晨三點多,被連續的警報聲給驚醒了,以為上海拉了防空警報,難不成地震,空襲?難道是樓下那個車主車子被堵了,長按喇叭?開窗看看,好像都不是。好鬼畜的警報聲,家裡也沒裝報警器啊,莫不成家裡煤氣漏了?起床循聲而查,報警
Python爬取豆瓣TOP250圖書排行榜
# -*- coding: utf-8 -*- import bs4 import requests def open_url(url): # url = 'https://movie.douban.com/top250' hd = {}
利用Requests庫和正則表示式爬取豆瓣影評Top250
說明 最近看了下爬蟲基礎,想寫個部落格來記錄一下,一來是可以方便和我一樣剛入門的小白來參考學習,二來也當做自己的筆記供自己以後查閱。 本文章是利用python3.6和Requests庫(需自行安裝,cmd裡執行pip install r
python實踐2——利用爬蟲抓取豆瓣電影TOP250資料及存入資料到MySQL資料庫
這次以豆瓣電影TOP250網為例編寫一個爬蟲程式,並將爬取到的資料(排名、電影名和電影海報網址)存入MySQL資料庫中。下面是完整程式碼:Ps:在執行程式前,先在MySQL中建立一個數據庫"pachong"。import pymysql import requests imp
(7)Python爬蟲——爬取豆瓣電影Top250
利用python爬取豆瓣電影Top250的相關資訊,包括電影詳情連結,圖片連結,影片中文名,影片外國名,評分,評價數,概況,導演,主演,年份,地區,類別這12項內容,然後將爬取的資訊寫入Excel表中。基本上爬取結果還是挺好的。具體程式碼如下: #!/us
python爬蟲——爬取豆瓣電影top250資訊並載入到MongoDB資料庫中
最近在學習關於爬蟲方面的知識,因為剛開始接觸,還是萌新,所以有什麼錯誤的地方,歡迎大家指出 from multiprocessing import Pool from urllib.request import Request, urlopen import re, pymongo index
python爬蟲(一)爬取豆瓣電影Top250
提示:完整程式碼附在文末 一、需要的庫 requests:獲得網頁請求 BeautifulSoup:處理資料,獲得所需要的資料 二、爬取豆瓣電影Top250 爬取內容為:豆瓣評分前二百五位電影的名字、主演、