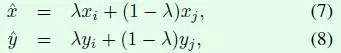復現實驗難以達到論文中精度?你需要考慮網路的優化問題
復現論文實驗一直是一大難題,或者說復現實驗達到論文中精度是一大難題。絕大部分時候我們很難復現到媲美原文的精度,這很大原因是神經網路的引數眾多,優化技巧眾多,引數初始化等一些列問題,一般論文中對不會對小細節的處理進行描述或者他們有著一些不為人知的“trick”,所以我們很多時候我們達不到他們的實驗效果。
之前我曾嘗試復現幾篇論文的實驗,花了很大力氣總算搞出來的,但是結果實驗結果與原文中精度總有2-3%左右的差距。由於原文沒開原始碼,按照他論文來所描述的來寫程式碼,難以發現自己哪裡出問題了,後來就放棄了。
最近看到一篇有關網路優化的文章,感覺挺有用的,對復現實驗程式碼比較有用,所以寫下來了。
一、加快模型訓練
主要有兩塊內容:一塊是選用更大的batch size,另一塊是採用16位浮點型進行訓練。
選用更大的batch size能夠在整體上加快模型的訓練,但是一般而言如果只增大batch size,效果不會太理想,這部分目前有比較多的研究論文,比如Facebook的這篇:Accurate, Large Minibatch SGD:Training ImageNet in 1 Hour,作者也總結了主要的幾個解決方案。
- 增大學習率,因為更大的batch size意味著基於每個batch資料計算得到的梯度更加貼近整個資料集(數學上來講就是方差更小),因此當更新方向更加準確後,邁的步子也可以更大了,一般而言將batch size修改為原來的幾倍,那麼初始學習率也需要修改為原來的幾倍。
- 用一個小的學習率先訓幾個epoch(warmup) 。因為網路的引數是隨機初始化的,假如一開始就採用較大的學習率容易出現數值不穩定,這是使用warmup的原因。等到訓練過程基本穩定了就可以使用原先設定的初始學習率進行訓練了。作者在實現warmup的過程中採用線性增加的策略,舉例而言,假設warmup階段的初始學習率是0,warmup階段共需要訓練m個batch的資料(實現中m個batch共5個epoch),假設訓練階段的初始學習率是L,那麼在batch i的學習率就設定為i*L/m。
- 每個殘差塊的最後一個BN層的γ引數初始化為0,我們知道BN層的γ、β引數是用來對標準化後的輸入做線性變換的,也就是γx^+β,一般γ引數都會初始化為1,作者認為初始化為0更有利於模型的訓練。
- 不對bias引數執行weight decay操作,weight decay主要的作用就是通過對網路層的引數(包括weight和bias)做約束(L2正則化會使得網路層的引數更加平滑)達到減少模型過擬合的效果。
採用低精度(16位浮點型)訓練是從數值層面來做加速。一般而言現在大部分的深度學習網路的輸入、網路引數、網路輸出都採用32位浮點型,現在隨著GPU的迭代更新(比如V100支援16為浮點型的模型訓練),如果能使用16位浮點型引數進行訓練,就可以大大加快模型的訓練速度,這是作者加速訓練最主要的措施,不過目前來看應該只有V100才能支援這樣的訓練。
二、優化網路結構部分
這部分的優化是以ResNet為例的,Figure1是ResNet網路的結構示意圖,簡單而言是一個input stem結構、4個stage和1個output部分,input stem和每個stage的內容在第二列展示,每個residual block的結構在第三列展示,整體而言這個圖畫得非常清晰了。

關於residual block的改進可以參考Figure2,主要有3點。
- ResNet-B,改進部分就是將stage中做downsample的residual block的downsample操作從第一個11卷積層換成第二個33卷積層,如果downsample操作放在stride為2的11卷積層,那麼就會丟失較多特徵資訊(預設是縮減為1/4),可以理解為有3/4的特徵點都沒有參與計算,而將downsample操作放在33卷積層則能夠減少這種損失,因為即便stride設定為2,但是卷積核尺寸夠大,因此可以覆蓋特徵圖上幾乎所有的位置。
- ResNet-C,改進部分就是將Figure1中input stem部分的77卷積層用3個33卷積層替換。這部分借鑑了Inception v2的思想,主要的考慮是計算量,畢竟大尺寸卷積核帶來的計算量要比小尺寸卷積核多不少,不過讀者如果仔細計算下會發現ResNet-C中3個33卷積層的計算量並不比原來的少,這也是Table5中ResNet-C的FLOPs反而增加的原因。
- ResNet-D,改進部分是將stage部分做downsample的residual block的支路從stride為2的11卷積層換成stride為1的卷積層,並在前面新增一個池化層用來做downsample。這部分我個人理解是雖然池化層也會丟失資訊,但至少是經過選擇(比如這裡是均值操作)後再丟失冗餘資訊,相比stride設定為2的1*1卷積層要好一些。

三、模型訓練調優部分
主要4個調優技巧:
- 學習率衰減策略採用cosine函式,這部分的實驗結果對比可以參考Figure3,其中(a)是cosine decay和step decay的示意圖,step decay是目前比較常用的學習率衰減方式,表示訓練到指定epoch時才衰減學習率。(b)是2種學習率衰減策略在效果上的對比。

- 採用label smoothing,網路中softmax的輸出可以直接理解成概率,而one-hot向量只有0與1。所以這部分是將原來常用的one-hot型別標籤做軟化,這樣在計算損失值時能夠在一定程度上減少過擬合,可以增強模型的泛化能力。從交叉熵損失函式可以看出,只有真實標籤對應的類別概率才會對損失值計算有所幫助,全概率和零概率將鼓勵所屬類別和非所屬類別之間的差距儘可能拉大,而由於以上可知梯度有界,因此很難adapt。
因此label smoothing相當於減少真實標籤的類別概率在計算損失值時的權重,同時增加其他類別的預測概率在最終損失函式中的權重。這樣真實類別概率和其他類別的概率均值之間的gap(倍數)就會下降一些,會造成模型過於相信預測的類別。
label smoothing的具體: 為了使得模型less confident,提出將label真實標籤從 變成 ,其中
對於以Dirac函式分佈的真實標籤,我們將它變成分為兩部分獲得(替換)
1.第一部分:將原本Dirac分佈的標籤變數替換為 (1 - ϵ)的Dirac函式;
2.第二部分:以概率 ϵ ,在u(k)u(k) 中份分佈的隨機變數。(在文章中,作者採用先驗概率也就是均布概率,而K取值為num_class = 1000)
從而交叉熵被替換為: 可以認為:Loss 函式為分別對【預測label與真實label】【預測label與先驗分佈】進行懲罰。 - **知識蒸餾(knowledge distillation)**這部分其實是模型加速壓縮領域的一個重要分支,表示用一個效果更好的teacher model訓練student model,使得student model在模型結構不改變的情況下提升效果。作者採用ResNet-152作為teacher model,用ResNet-50作為student model,程式碼上通過在ResNet網路後新增一個蒸餾損失函式實現,這個損失函式用來評價teacher model輸出和student model輸出的差異,因此整體的損失函式原損失函式和蒸餾損失函式的結合:
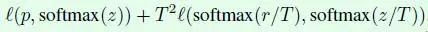
其中p表示真實標籤,z表示student model的全連線層輸出,r表示teacher model的全連線層輸出,T是超引數,用來平滑softmax函式的輸出 - 引入mixup,mixup其實也是一種資料增強方式,假如採用mixup訓練方式,那麼每次讀取2張輸入影象,假設用(xi,yi)和(xj,yj)表示,那麼通過下面這兩個式子就可以合成得到一張新的影象(x,y),然後用這張新影象進行訓練,需要注意的是採用這種方式訓練模型時要訓更多epoch。式子中的λ是一個超引數,用來調節合成的比重,取值範圍是[0,1]。