
【Python資料探勘課程】一.安裝Python及爬蟲入門介紹
希望該文章對你有所幫助,尤其是對大資料或資料探勘的初學者,很開心和夏博、小民一起分享該課程,上課的感覺真的挺不錯的,挺享受的。我也將認真對待每一個我的學生,真的好想把自己的所學的所有知識都給予你們。同時由於學生來自不同的學院,有的甚至沒有接觸過程式設計,所以這門課程也將採用從零單排的形式講述。
這門課程圍繞下圖所示的內容進行展開及實戰。
課程資源:

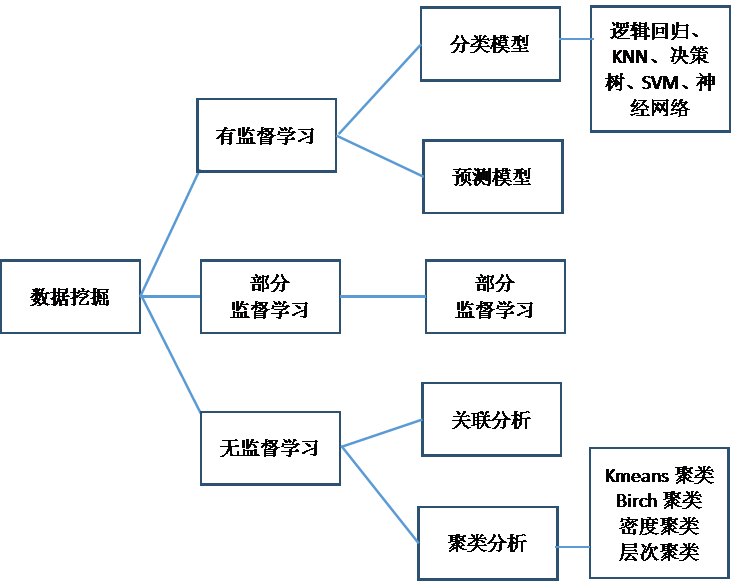
一. 大資料及資料探勘基礎
第一部分主要簡單介紹三個問題(覺得無聊的直接調至第二部分):
1、什麼是大資料?
2、什麼是資料探勘?
3、大資料和資料探勘的區別?
由於前面幾節課老師普及了大資料等一些基礎知識,這裡我並沒有詳細介紹,只是給幾張圖片,讓大家簡單瞭解下大資料和資料探勘相關的基礎概念,我分享更多的是實戰以及程式設計。
<一>.大資料(Big Data)
大資料(big data)指無法在一定時間範圍內用常規軟體工具進行捕捉、管理和處理的資料集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力來適應海量、高增長率和多樣化的資訊資產。
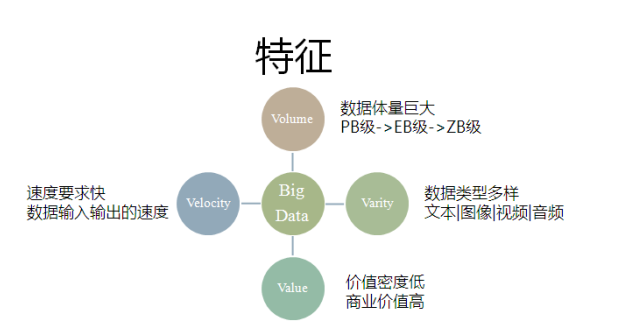
下圖是大資料經典的4V特徵。
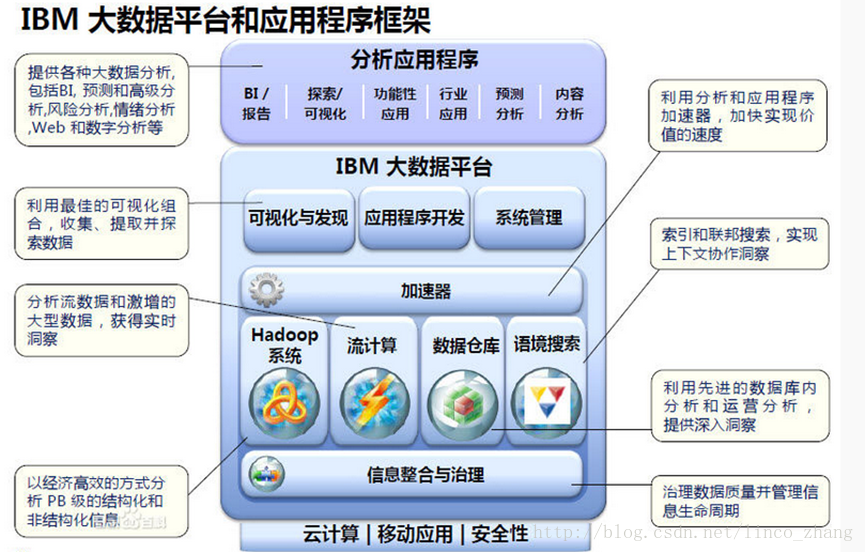
IBM大資料庫框架及視覺化技術,大資料常用:Hadoop、Spark,現在更多的是實時資料分析,包括淘寶、京東、附近美食等。
下圖是大資料的一些應用。

說到大資料,就不得不提Hadoop,而說到Hadoop,又不得不提Map-Reduce。
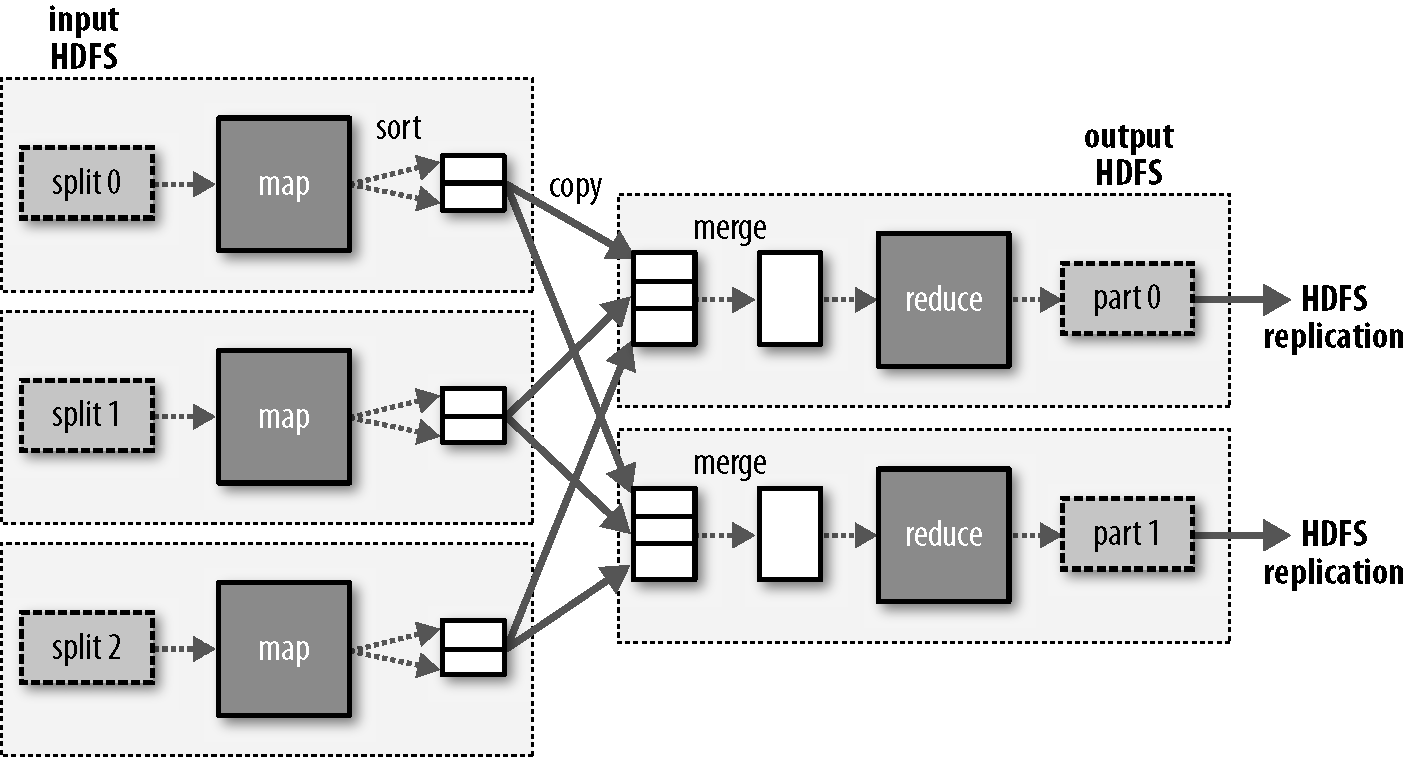
MapReduce是一個軟體框架由上千個商用機器組成的大叢集上,並以一種可靠的,具有容錯能力的方式並行地處理上TB級別的海量資料集。MapReduce的思想是“分而治之”。Mapper負責“分,Reducer負責對map階段的結果進行彙總。
<二>.資料探勘(Data Mining)
資料探勘(Data Mining):資料庫、機器學習、人工智慧、統計學的交叉學科。
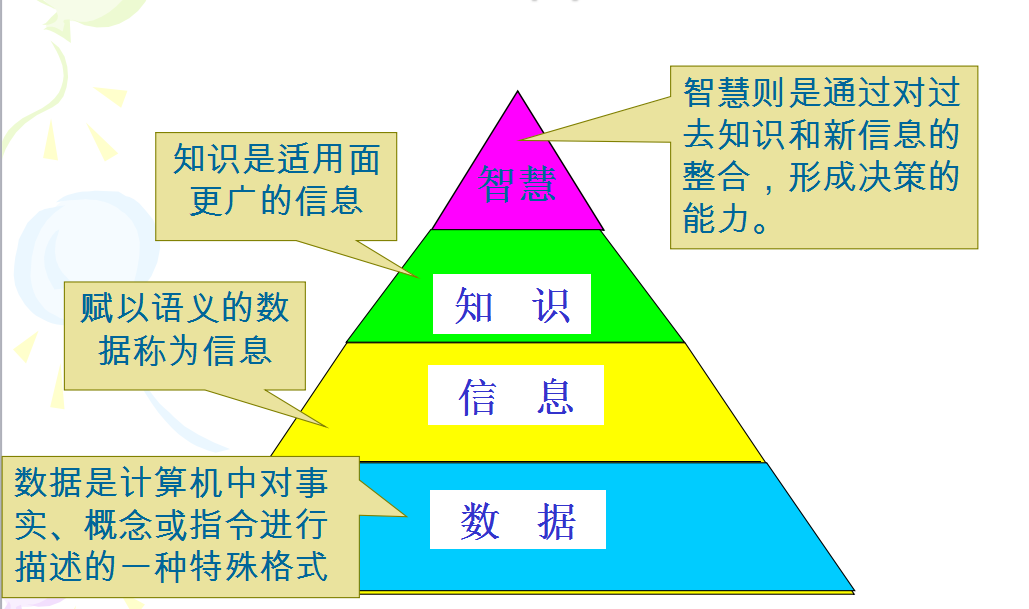
資料探勘需要發現有價值的知識,同時最頂端都是具有智慧的去發現知識及有價值的資訊。
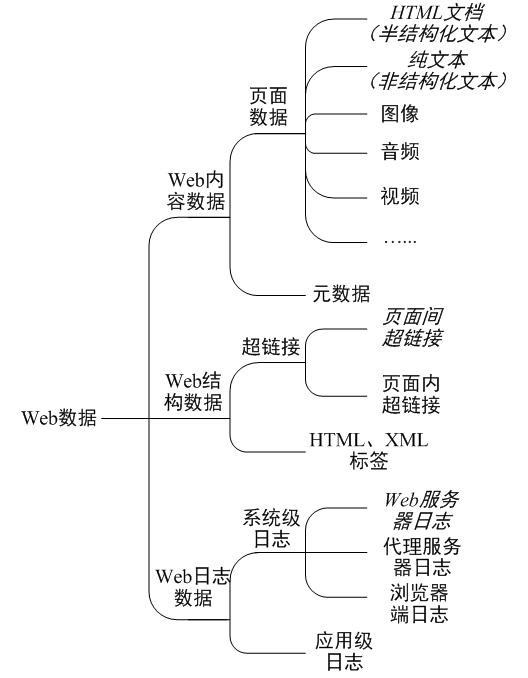
因為這門課程主要是針對網頁資料進行的大資料分析,需要Web Mining分類如下:
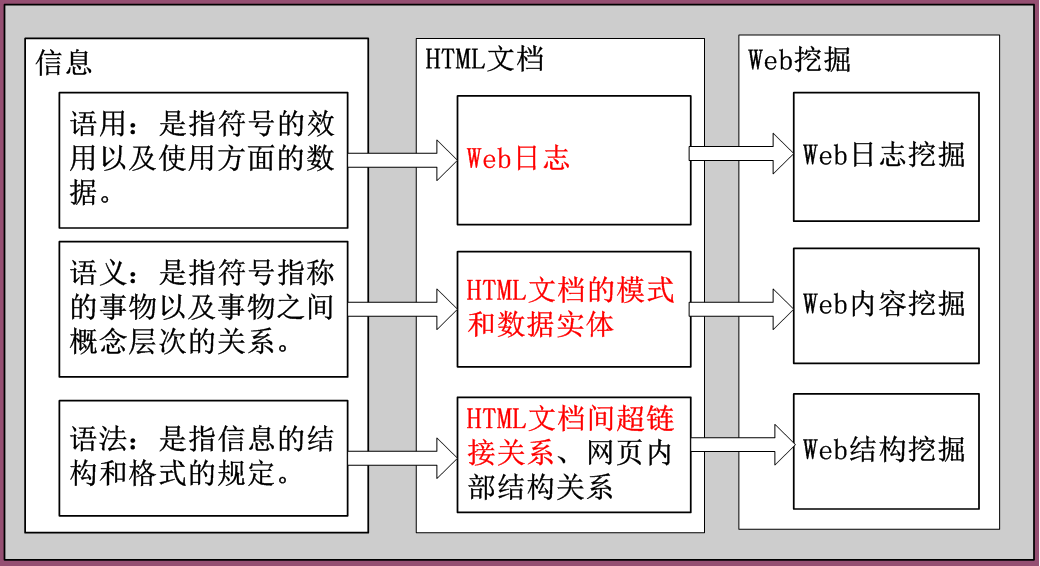
Web挖掘主要分為三類:Web日誌挖掘、Web內容挖掘、Web結構挖掘。
<三>.機器學習
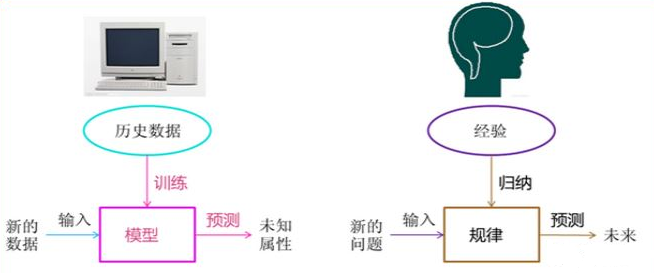
講到機器學習和資料探勘相關的知識,我通常都會補充兩幅圖片,感覺真的很棒。很想象的表示了計算機智慧化與人類傳統知識的類比。

二. 安裝Python及基礎知識
<一>.安裝Python
在開始使用Python程式設計之前,需要介紹Python的安裝過程。python直譯器在Linux中可以內建使用安裝,windows中需要去http://www.python.org官網downloads頁面下載。具體步驟如下:
第一步:開啟Web瀏覽器並訪問http://www.python.org官網;
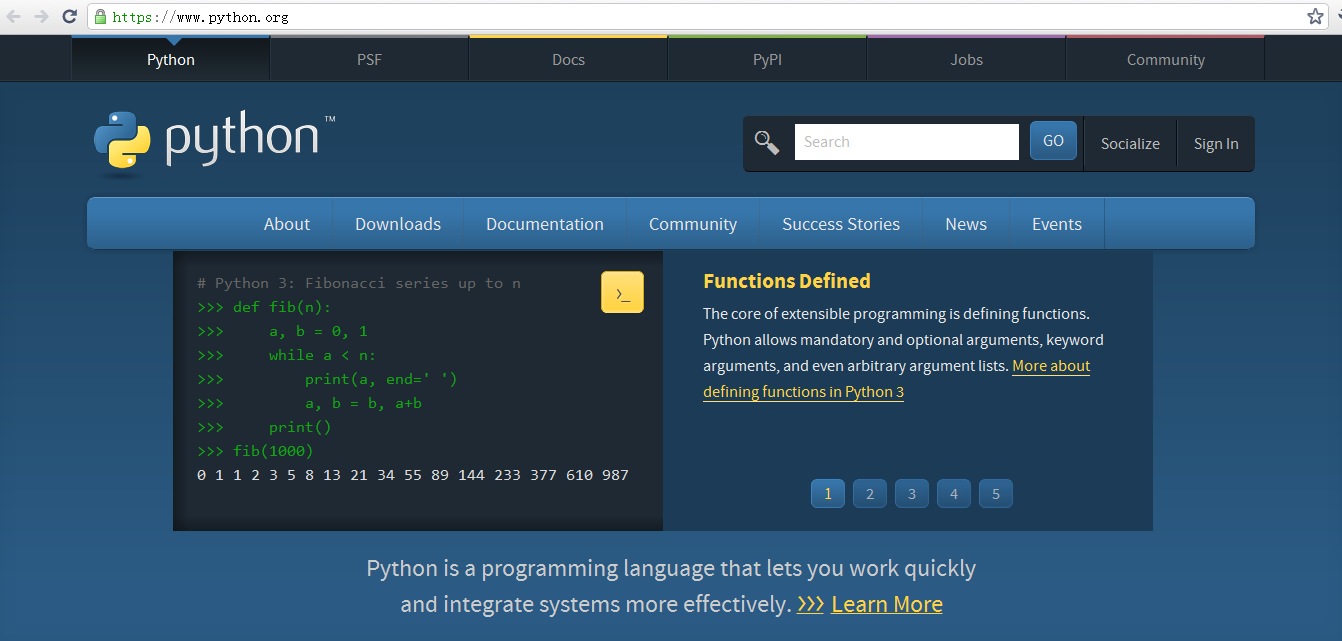
第二步:在官網首頁點選Download連結,進入下載介面,選擇Python軟體的版本,作者選擇下載python 2.7.8,點選“Download”連結。
Python下載地址:
第三步:選擇檔案下載地址,並下載檔案。
第四步:雙擊下載的“python-2.7.8.msi”軟體,並對軟體進行安裝。
 第五步:在Python安裝嚮導中選擇預設設定,點選“Next”,選擇安裝路徑,這裡設定為預設的安裝路徑“C:\Python27”,點選“Next”按鈕,如圖所示。
第五步:在Python安裝嚮導中選擇預設設定,點選“Next”,選擇安裝路徑,這裡設定為預設的安裝路徑“C:\Python27”,點選“Next”按鈕,如圖所示。注意1:建議將Python安裝在C盤下,通常路徑為C:\Python27,不要存在中文路徑。
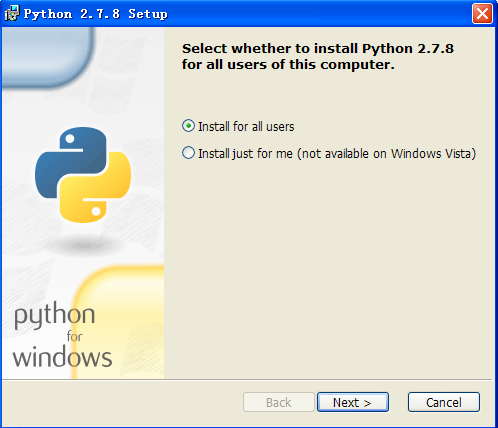
在Python安裝嚮導中選擇預設設定,點選“Next”,選擇安裝路徑,這裡設定為預設的安裝路徑“C:\Python27”,點選“Next”按鈕。
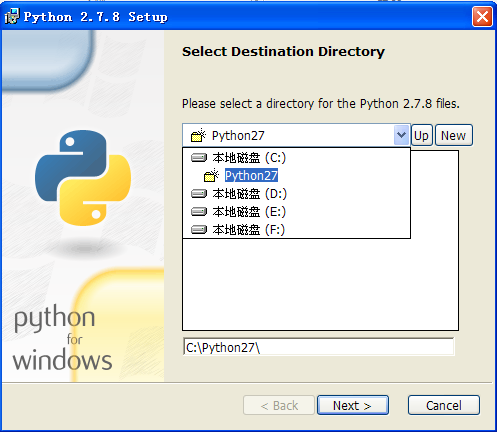
安裝成功後,如下圖所示:
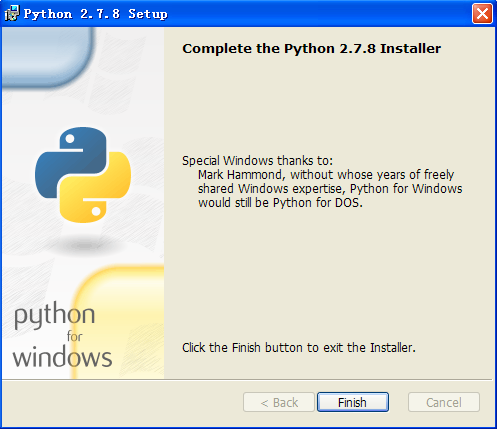
第六步:假設安裝一切正常,點選“開始”,選中“程式”,找到安裝成功的Python軟體,如圖所示:
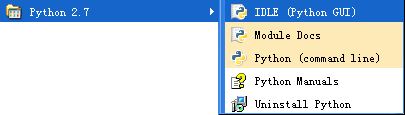
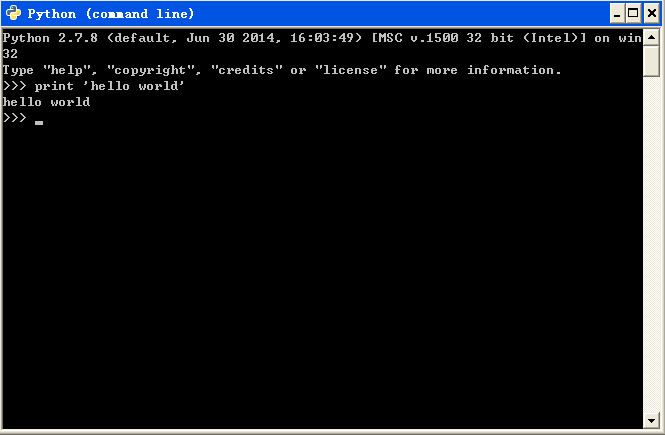
選中上圖中第三個圖示,即點選“Python (command line)命令列模式”,執行程式輸入如下程式碼:
print 'hello world'
則python命令列模式的直譯器會列印輸出“hello world”字串,如下圖所示。
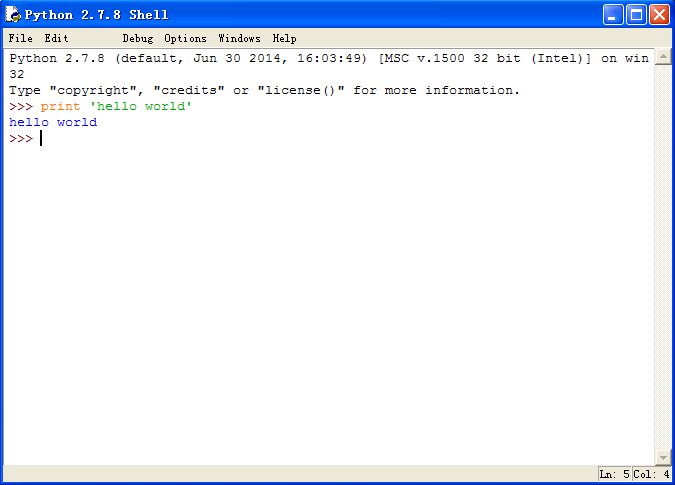
選中圖中的第一個圖片,點選“IDLE (Python GUI)”,即執行Python的整合開發環境(Python Integrated Development Environment,IDLE),執行結果如下圖。
注意2:建議大家使用IDLE寫指令碼,完整的程式碼而不是通過命令列模式。
<二>.Python基礎知識
這裡簡單入門介紹,主要介紹下條件語句、迴圈語句、函式等基礎知識。
1、函式及執行
這裡舉個簡單的例子。開啟IDLE工具->點選欄"File"->New File新建檔案->命名為test.py檔案,在test檔案裡新增程式碼如下:
def fun1():
print 'Hello world'
print 'by eastmount csdn'
print 'output'
fun1()
def fun2(val1,val2):
print val1
print val2
fun2(8,15) 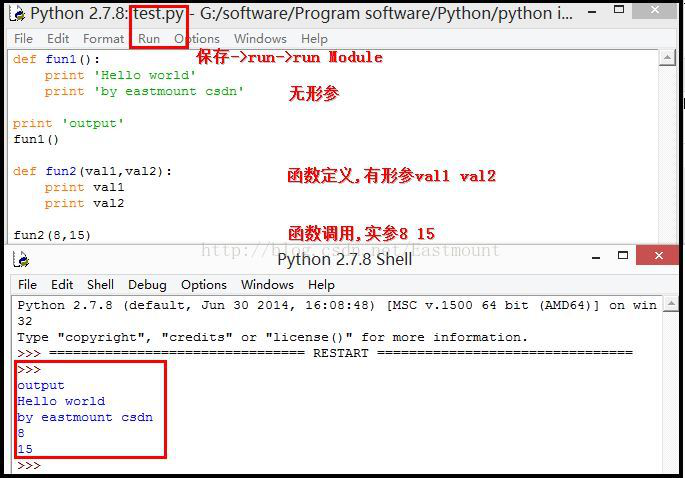
2、條件語句
包括單分支、雙分支和多分支語句,if-elif-else。
(1).單分支語句
它的基本格式是:
if condition:
statement
statement
需要注意的是Ptthon中if條件語句條件無需圓括號(),條件後面需要新增冒號,它沒有花括號{}而是使用TAB實現區分。其中condition條件判斷通常有布林表示式(True|False 0-假|1-真 非0即真)、關係表示式(>=
<= == !=)和邏輯運算表示式(and or not)。
(2).雙分支語句
它的基本格式是:
if condition:
statement
statement
else:
statement
statement
(3).多分支語句
if多分支由if-elif-else組成,其中elif相當於else if,同時它可以使用多個if的巢狀。具體程式碼如下所示:
#雙分支if-else
count = input("please input:")
print 'count=',count
if count>80:
print 'lager than 80'
else:
print 'lower than 80'
print 'End if-else'
#多分支if-elif-else
number = input("please input:")
print 'number=',number
if number>=90:
print 'A'
elif number>=80:
print 'B'
elif number>=70:
print 'C'
elif number>=60:
print 'D'
else:
print 'No pass'
print 'End if-elif-else'
#條件判斷
sex = raw_input("plz input your sex:")
if sex=='male' or sex=='m' or sex=='man':
print 'Man'
else:
print 'Woman'3、while迴圈語句
while迴圈語句的基本格式如下:
while condition:
statement
statement
else:
statement
statement
其中判斷條件語句condition可以為布林表示式、關係表示式和邏輯表示式,else可以省略(此處列出為與C語言等區別)。舉個例子:
#迴圈while計數1+2+..+100
i = 1
s = 0
while i <= 100:
s = s+i
i = i+1
else:
print 'exit while'
print 'sum = ',s
'''
輸出結果為:exit while
sum = 5050
''' 4、for迴圈
該迴圈語句的基礎格式為:
for target in sequences:
statements
target表示變數名,sequences表示序列,常見型別有list(列表)、tuple(元組)、strings(字串)和files(檔案).
Python的for沒有體現出迴圈的次數,不像C語言的for(i=0;i<10;i++)中i迴圈計數,Python的for指每次從序列sequences裡面的資料項取值放到target裡,取完即結束,取多少次迴圈多少次。其中in為成員資格運算子,檢查一個值是否在序列中。同樣可以使用break和continue跳出迴圈。
下面是檔案迴圈遍歷的過程:
#檔案迴圈遍歷三種對比
for n in open('for.py','r').read():
print n,
print 'End'
for n in open('for.py','r').readlines():
print n,
print 'End'
for n in open('for.py','r').readline():
print n,
print 'End' 5、課堂講解程式碼
這是我課堂講解的程式碼,僅供大家參考:
#coding=utf-8
import os
import string
print '貴州財經大學大資料金融學院,大家好!'
def fun1():
print 'Hello world'
print 'Goodbye!'
#計算和
def fun2(n, m):
return n+m
#輸出結果
fun1()
s = fun2(3,8)
print 'sum = ' + str(s)
print 'sum =', s
#判斷語句 u表示unicode字串
if(s>10):
print u'大於10'
else:
print u'小於等於10'
#迴圈語句
i = 1
s = 0
while i<=100:
s = s + i
i = i + 1
else:
print 'end while'
print 'sum =', s
'''
輸出結果為:sum=5050
'''
#for迴圈
num = [2, 4, 6, 8, 10]
for x in num:
print x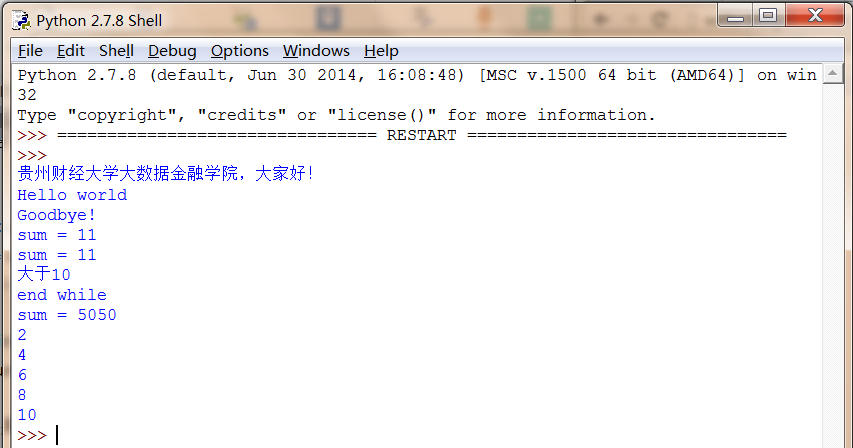
三. 安裝PIP及第三方包
接下來需要詳解介紹爬蟲相關的知識了,這裡主要涉及到下面幾個知識:

爬蟲主要使用Python(字串|urllib)+Selenium+PhantomJS+BeautifulSoup。
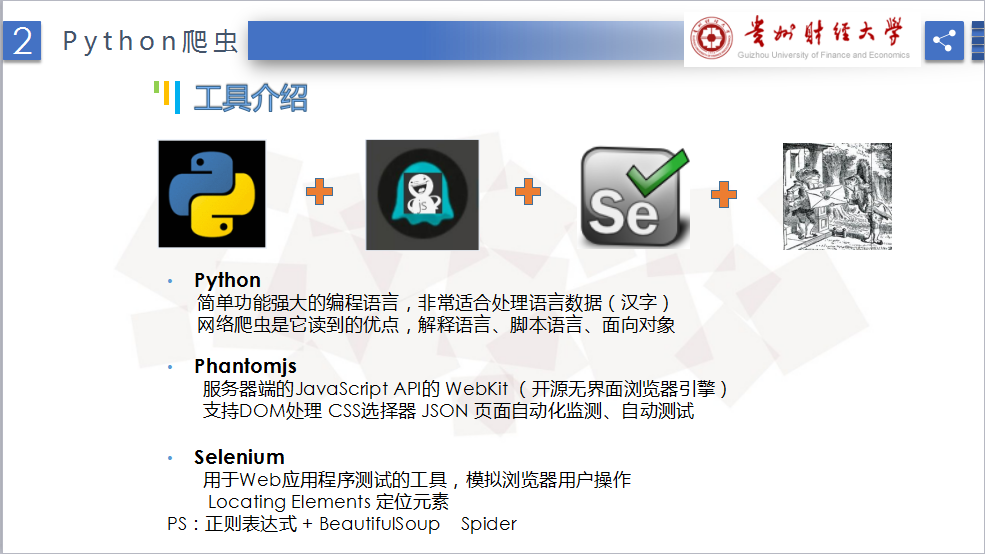
在介紹爬蟲及Urllib下載網頁或圖片之前,先交大家如何使用pip安裝第三方的庫。
PIP
在介紹介紹它們之前,需要安裝PIP軟體。正如xifeijian大神所說:“作為Python愛好者,如果不知道easy_install或者pip中的任何一個的話,那麼......”。
easy_insall的作用和perl中的cpan,ruby中的gem類似,都提供了線上一鍵安裝模組的傻瓜方便方式,而pip是easy_install的改進版,提供更好的提示資訊,刪除package等功能。老版本的python中只有easy_install,沒有pip。常見的具體用法如下:
easy_install的用法:
1) 安裝一個包
$ easy_install <package_name>
$ easy_install "<package_name>==<version>"
2) 升級一個包
$ easy_install -U "<package_name>>=<version>"
pip的用法
1) 安裝一個包
$ pip install <package_name>
$ pip install <package_name>==<version>
2) 升級一個包 (如果不提供version號,升級到最新版本)
$ pip install --upgrade <package_name>>=<version>
3)刪除一個包
$ pip uninstall <package_name> 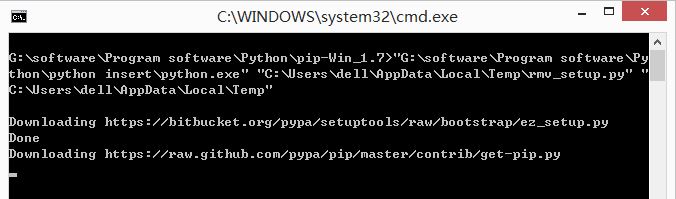
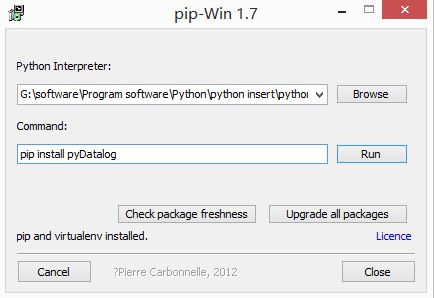
當提示"pip and virtualenv installed"表示安裝成功,那怎麼測試PIP安裝成功呢?
第三步:配置環境變數
此時在cmd中輸入pip指令會提示錯誤“不是內部或外部命令”。
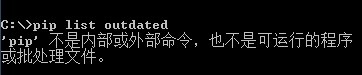 注意:兩種解決方法,一種是通過cd ..去到Srcipts環境進行安裝,pip install...
注意:兩種解決方法,一種是通過cd ..去到Srcipts環境進行安裝,pip install...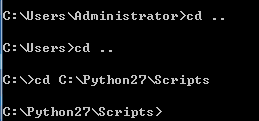 方法二:另一種配置Path路徑。
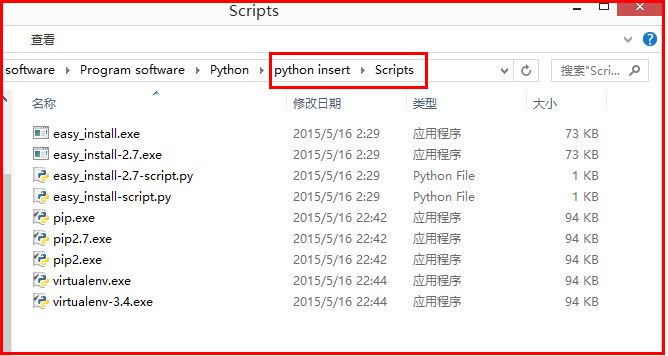
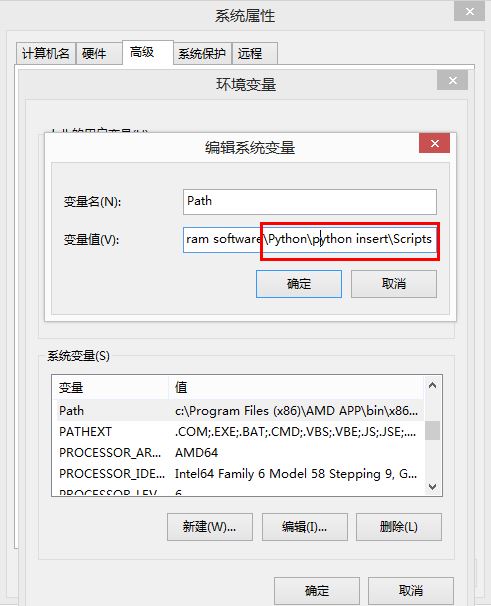
方法二:另一種配置Path路徑。需要新增path環境變數。PIP安裝完成後,會在Python安裝目錄下新增python\Scripts目錄,即在python安裝目錄的Scripts目錄下,將此目錄加入環境變數中即可!過程如下:
第四步:使用PIP命令
下面在CMD中使用PIP命令,“pip list outdate”列舉Python安裝庫的版本資訊。
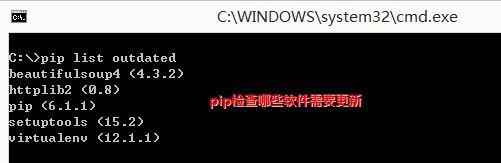
注意:安裝成功後,會在Python環境中增加Scripts資料夾,包括easy_install和pip。
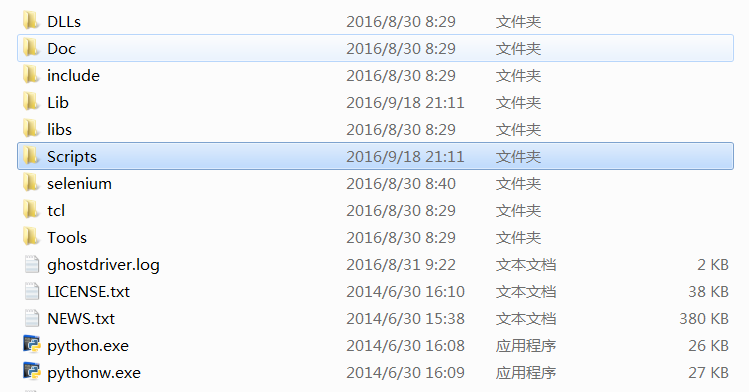
PIP安裝過程中可能出現各種問題,一種解決方法是去到python路徑,通過python set_up.py install安裝;另一種是配置Path環境比例。
課堂重點知識:
第一節課主要想讓大家體會下Python網路爬蟲的過程及示例。需要安裝的第三方庫主要包括三個:
pip install httplib2
pip install urllib
pip install selenium
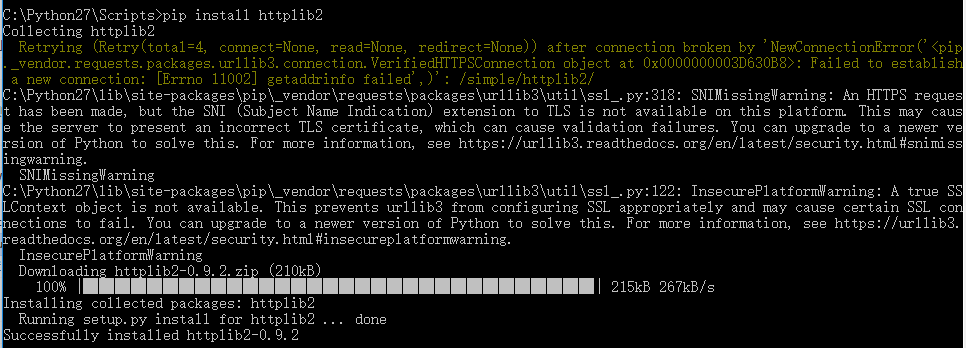 在安裝過程中,如果pip install urllib報錯,是因為httplib2包含了,可直接用。
在安裝過程中,如果pip install urllib報錯,是因為httplib2包含了,可直接用。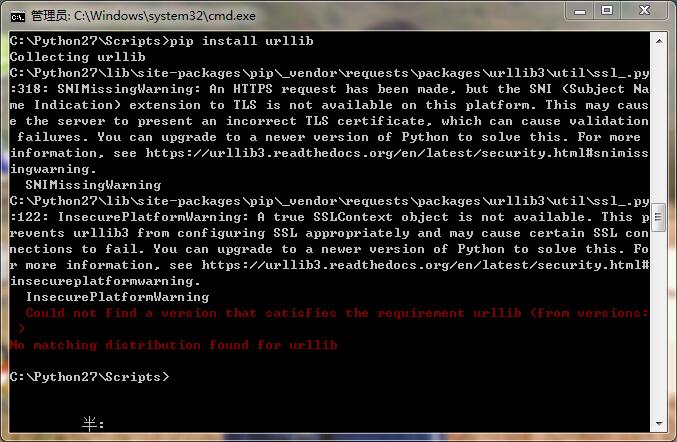 注意:如果pip安裝報錯ascii編碼問題,需要把計算機名稱從中文修改為英文名。
注意:如果pip安裝報錯ascii編碼問題,需要把計算機名稱從中文修改為英文名。四. Urllib下載網頁及圖片
在使用pip install urllib或pip install urllib2後,下面這段程式碼是下載網頁。
#coding=utf-8
import os
import urllib
import httplib2
import webbrowser as web
#爬取線上網站
url = "http://www.baidu.com/"
content = urllib.urlopen(url).read()
open("baidu.html","w").write(content)
#瀏覽求開啟網站
web.open_new_tab("baidu.html")
urlopen(url, data, timeout)第二三個引數是可以不傳送的,data預設為空None,timeout預設為 socket._GLOBAL_DEFAULT_TIMEOUT。
第一個引數URL是必須要傳送的,在這個例子裡面我們傳送了百度的URL,執行urlopen方法之後,返回一個response物件,返回資訊便儲存在這裡面。
response = urllib2.urlopen("http://www.baidu.com")
print response.read()獲取的網頁本地儲存為"baidu.html",通過瀏覽器開啟如下圖所示:
然後是需要下載圖片,這裡需要學會找到圖片的URL,如下圖百度的LOGO,可以通過瀏覽器右鍵"審查元素"或"檢查"來進行定位。
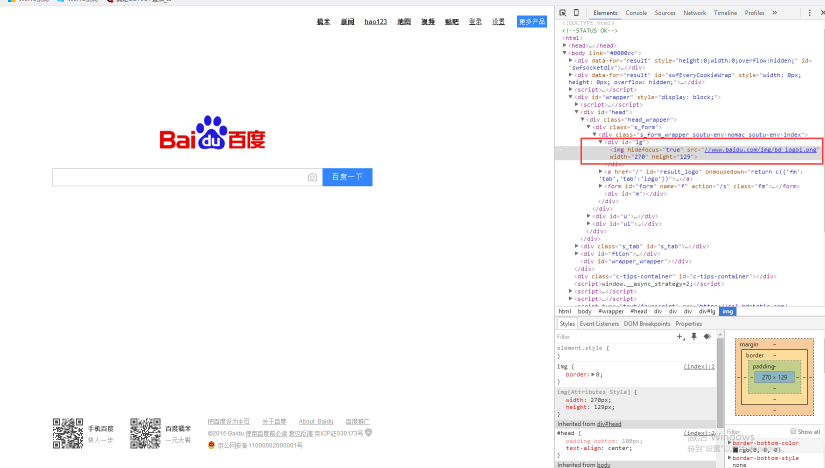
定位URL後,再通過函式urlretrieve()進行下載。
#coding=utf-8
import os
import urllib
import httplib2
import webbrowser as web
#爬取線上網站
url = "http://www.baidu.com/"
content = urllib.urlopen(url).read()
open("baidu.html","w").write(content)
#瀏覽求開啟網站
web.open_new_tab("baidu.html")
#下載圖片 審查元素
pic_url = "https://www.baidu.com/img/bd_logo1.png"
pic_name = os.path.basename(pic_url) #刪除路徑獲取圖片名字
urllib.urlretrieve(pic_url, pic_name)
#本地檔案
content = urllib.urlopen("first.html").read()
print content
#下載圖片 審查元素
pic_url = "imgs/bga1.jpg"
pic_name = os.path.basename(pic_url) #刪除路徑獲取圖片名字
urllib.urlretrieve(pic_url, pic_name)
重點知識:
urllib.urlopen(url[, data[, proxies]]) :建立一個表示遠端url的類檔案物件,然後像本地檔案一樣操作這個類檔案物件來獲取遠端資料。
urlretrieve方法直接將遠端資料下載到本地。
如果需要顯示進度條,則使用下面這段程式碼:
import urllib
def callbackfunc(blocknum, blocksize, totalsize):
'''回撥函式
@blocknum: 已經下載的資料塊
@blocksize: 資料塊的大小
@totalsize: 遠端檔案的大小
'''
percent = 100.0 * blocknum * blocksize / totalsize
if percent > 100:
percent = 100
print "%.2f%%"% percent
url = 'http://www.sina.com.cn'
local = 'd:\\sina.html'
urllib.urlretrieve(url, local, callbackfunc)五. HTML網頁基礎知識及審查元素
HTML DOM是HTML Document Object Model(文件物件模型)的縮寫,HTML DOM則是專門適用於HTML/XHTML的文件物件模型。熟悉軟體開發的人員可以將HTML DOM理解為網頁的API。它將網頁中的各個元素都看作一個個物件,從而使網頁中的元素也可以被計算機語言獲取或者編輯。

DOM是以層次結構組織的節點或資訊片斷的集合。這個層次結構允許開發人員在樹中導航尋找特定資訊。分析該結構通常需要載入整個文件和構造層次結構,然後才能做任何工作。由於它是基於資訊層次的,因而 DOM 被認為是基於樹或基於物件的。
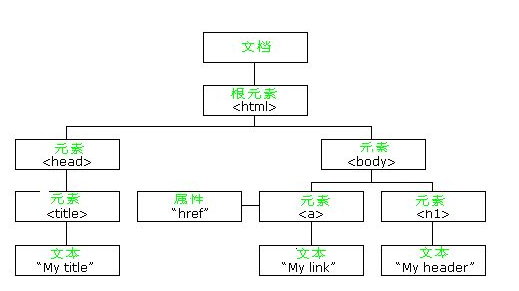
HTML DOM 定義了訪問和操作HTML文件的標準方法。 HTML DOM 把 HTML 文件呈現為帶有元素、屬性和文字的樹結構(節點樹)。它們都是一個節點(Node),就像公司的組織結構圖一樣。 我們現在從另一個角度來審視原始碼,first.html的原始碼如下:
<html>
<head>
<title>Python挖掘開發</title>
</head>
<body>
歡迎大家學習《基於Python的Web大資料爬取實戰指南》! <br>
</body>
</html>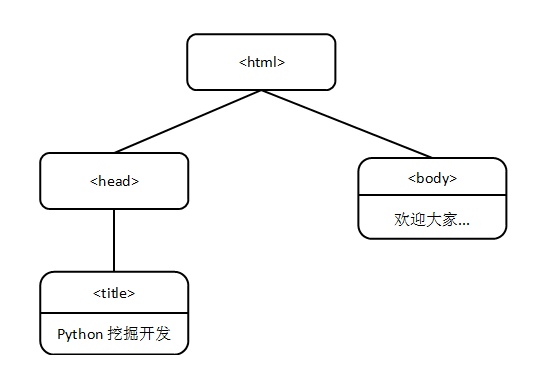
重點:
在網路爬蟲中,通常需要結合瀏覽器來定位元素,瀏覽器右鍵通常包括兩個重要的功能:檢視原始碼和審查或檢查元素。
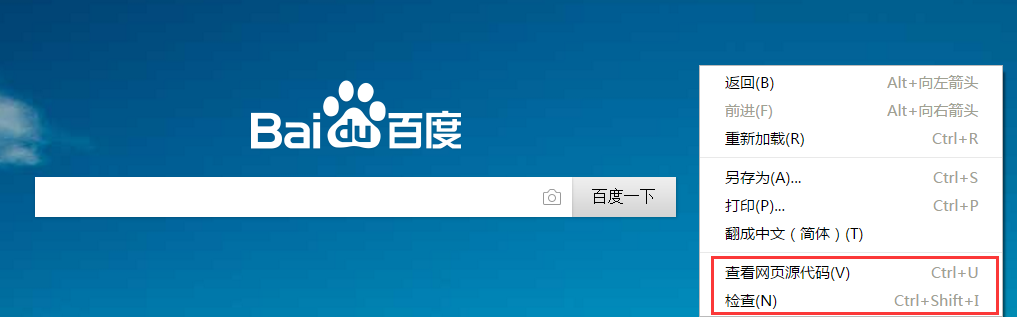
通過審查元素,可以定位到需要爬取圖片或網頁的HTML原始檔,通常是table或div的佈局,這些HTML標籤通常是成對出現的,如<html></html>、<div></div>等;同時會包括一些屬性id、name、class來指定該標籤。如:
<div id="content" name="n1" class="cc">....</div>
六. 安裝Selenium及網頁簡單爬取
Selenium用於Web應用程式測試的工具,模擬瀏覽器使用者操作,通過Locating Elements 定位元素。安裝過程如下圖所示,通過pip install selenium安裝。
注意:需要cd去到Scripts目錄進行安裝。
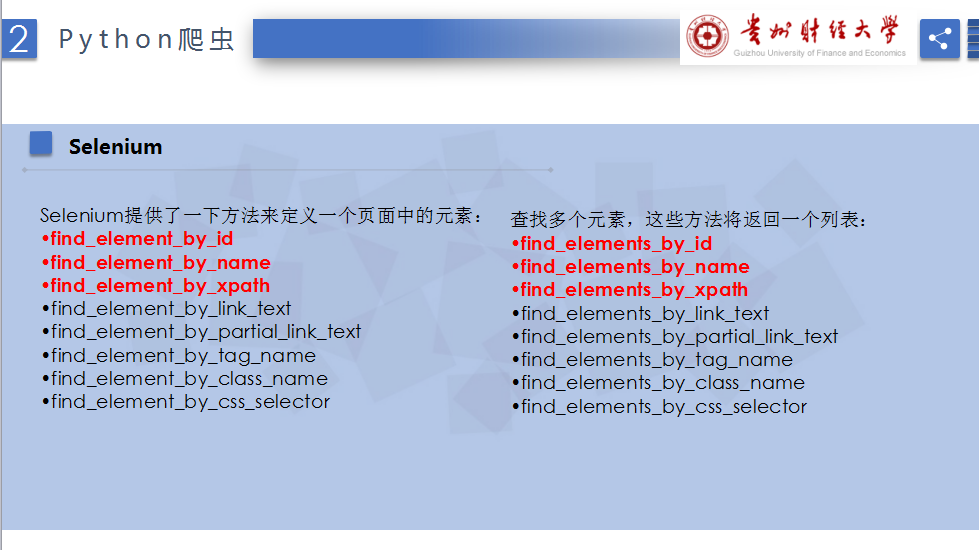
selenium結合瀏覽器定位的基本函式包括:
#coding=utf-8
import os
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#Open PhantomJS
#driver = webdriver.PhantomJS(executable_path="phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
#訪問url
driver.get("https://www.baidu.com/")
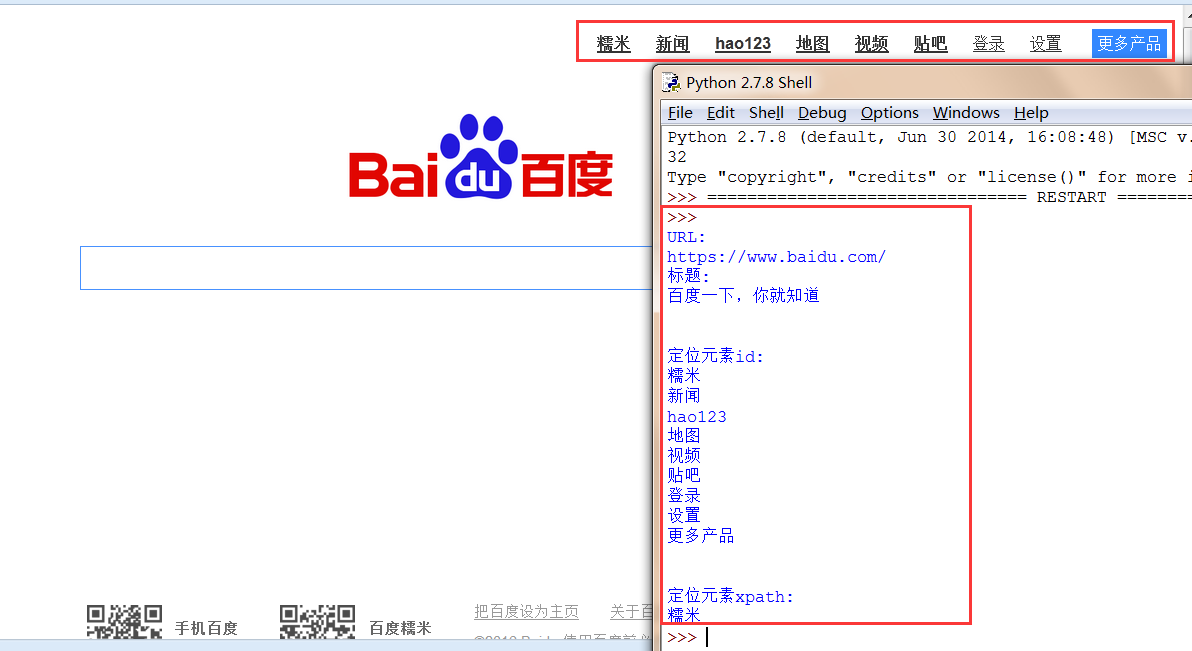
print u'URL:'
print driver.current_url
#當前連結: https://www.baidu.com/
print u'標題:'
print driver.title
#標題: 百度一下, 你就知道
#print driver.page_source
#原始碼
#定位元素,注意u1(數字1)和ul(字母L)區別
print u'\n\n定位元素id:'
info1 = driver.find_element_by_id("u1").text
print info1
#定位元素
print u'\n\n定位元素xpath:'
info3 = driver.find_element_by_xpath("//div[@id='u1']/a")
print info3.text
希望這篇文章對你有所幫助,主要是介紹基本的安裝過程及體會下Python爬蟲知識,後面會陸續詳細介紹相關內容。非常想上好這門課,因為是我的專業方向,另外學生們真的好棒,好認真,用手機錄影、問問題、配環境等等,只要有用心的學生,我定不負你!同時,自己授課思路有些亂,還需加強,但還是挺享受的,畢竟9800,哈哈哈!
(By:Eastmount 2016-09-19 晚上10點http://blog.csdn.net/eastmount/)
相關推薦
【Python資料探勘課程】一.安裝Python及爬蟲入門介紹
最近因為需要給大資料金融學院的學生講解《Python資料探勘及大資料分析》的課程,所以在這裡,我將結合自己的上課內容,詳細講解每個步驟。作為助教,我更希望這門課程以實戰為主,同時按小組劃分學生,每個小組最後都提交一個基於Python的資料探勘及大資料分析相關
【python資料探勘課程】十一.Pandas、Matplotlib結合SQL語句視覺化分析
這是非常好的一篇文章,可以認為是我做資料分析的轉折點,為什麼呢?因為這是我做資料分析第一次引入SQL語句,然後愛不釋手;結合SQL語句返回結果進行資料分析的效果真的很好,很多大神看到可能會笑話晚輩,但是如果你是資料分析的新人,那我強烈推薦,尤其是結合網路爬蟲進行資料分析的。希
【python資料探勘課程】二十一.樸素貝葉斯分類器詳解及中文文字輿情分析
這是《Python資料探勘課程》系列文章,也是我上課內容及書籍中的一個案例。本文主要講述樸素貝葉斯分類演算法並實現中文資料集的輿情分析案例,希望這篇文章對大家有所幫助,提供些思路。內容包括:1.樸素貝葉斯數學原理知識 2.naive_bayes用法及簡單案例 3.
【Python資料探勘課程】四.決策樹DTC資料分析及鳶尾資料集分析
希望這篇文章對你有所幫助,尤其是剛剛接觸資料探勘以及大資料的同學,同時準備嘗試以案例為主的方式進行講解。如果文章中存在不足或錯誤的地方,還請海涵~一. 分類及決策樹介紹1.分類 分類其實是從特定的資料中挖掘模式,作出判斷的過程。比如Gmail郵箱
【Python資料探勘課程】五.線性迴歸知識及預測糖尿病例項
希望這篇文章對你有所幫助,尤其是剛剛接觸資料探勘以及大資料的同學,同時準備嘗試以案例為主的方式進行講解。如果文章中存在不足或錯誤的地方,還請海涵~ 同時這篇文章是我上課的內容,所以參考了一些知識,強烈推薦大家學習斯坦福的機器學習Ng教授課程和Sc
【python資料探勘課程】十九.鳶尾花資料集視覺化、線性迴歸、決策樹花樣分析
這是《Python資料探勘課程》系列文章,也是我這學期上課的部分內容。本文主要講述鳶尾花資料集的各種分析,包括視覺化分析、線性迴歸分析、決策樹分析等,通常一個數據集是可以用於多種分析的,希望這篇文章對大
【python資料探勘課程】十.Pandas、Matplotlib、PCA繪圖實用程式碼補充
這篇文章主要是最近整理《資料探勘與分析》課程中的作品及課件過程中,收集了幾段比較好的程式碼供大家學習。同時,做資料分析到後面,除非是研究演算法創新的,否則越來越覺得資料非常重要,才是有價值的東西。後面的課程會慢慢講解Python應用在Hadoop和Spark中,以及netwo
【python資料探勘課程】十五.Matplotlib呼叫imshow()函式繪製熱圖
前面系列文章講過資料探勘的各種知識,最近在研究人類時空動力學分析和冪率定律,發現在人類興趣轉移模型中,可以通過熱圖(斑圖)來進行描述的興趣轉移,如下圖所示。下一篇文章將簡單普及人類動力學相關知識研究。這
【python資料探勘課程】十二.Pandas、Matplotlib結合SQL語句對比圖分析
一. 直方圖四圖對比 資料庫如下所示,包括URL、作者、標題、摘要、日期、閱讀量和評論數等。 執行結果如下所示,其中繪製多個圖的核心程式碼為: p1 = plt.subplot(221) plt.bar(ind, num
【python資料探勘課程】十八.線性迴歸及多項式迴歸分析四個案例分享
這是《Python資料探勘課程》系列文章,也是我這學期大資料金融學院上課的部分內容。本文主要講述和分享線性迴歸作業中,學生們做得比較好的四個案例,經過我修改後供大家學習,內容包括: 1.線性迴歸預測Pizza價格案例 2.線性迴歸分析波士頓房價案例 3.隨機
【python資料探勘課程】十六.邏輯迴歸LogisticRegression分析鳶尾花資料
今天是教師節,容我先感嘆下。祝天下所有老師教師節快樂,這是自己的第二個教師節,這一年來,無限感慨,有給一個人的指導,有給十幾個人講畢設,有幾十人的實驗,有上百人的課堂,也有給上千人的Python網路直播
【python資料探勘課程】十四.Scipy呼叫curve_fit實現曲線擬合
前面系列文章講過各種知識,包括繪製曲線、散點圖、冪分佈等,而如何在在散點圖一堆點中擬合一條直線,也變得非常重要。這篇文章主要講述呼叫Scipy擴充套件包的curve_fit函式實現曲線擬
【Python資料探勘課程】六.Numpy、Pandas和Matplotlib包基礎知識
前面幾篇文章採用的案例的方法進行介紹的,這篇文章主要介紹Python常用的擴充套件包,同時結合資料探勘相關知識介紹該包具體的用法,主要介紹Numpy、Pandas和Matplotlib三
【Python資料探勘課程】七.PCA降維操作及subplot子圖繪製
這篇文章主要介紹四個知識點,也是我那節課講課的內容。 1.PCA降維操作; 2.Python中Sklearn的PCA擴充套件包; 3.Matplotlib的subplot函式繪製子圖; 4.通過Kmean
【Python資料探勘課程】八.關聯規則挖掘及Apriori實現購物推薦
這篇文章主要介紹三個知識點,也是我《資料探勘與分析》課程講課的內容。 1.關聯規則挖掘概念及實現過程; 2.Apriori演算法挖掘頻繁項集; 3.Python實現關聯規則挖掘及置信度、支援度計算。一. 關聯規則挖掘概
【python資料探勘課程】邏輯迴歸LogisticRegression分析鳶尾花資料
plt.scatter(X[:50,0], X[:50,1], color='red',marker='o', label='setosa') 呼叫scatter()繪製散點圖,第一個引數為第一列資料(長度),第二個引數為第二列資料(寬度),第三、四個引數為設定點的顏色為紅色,款式為圓圈,最後標
【Python資料探勘課程】三.Kmeans聚類程式碼實現、作業及優化
這篇文章直接給出上次關於Kmeans聚類的籃球遠動員資料分析案例,同時介紹這次作業同學們完成的圖例,最後介紹Matplotlib包繪圖的優化知識。 希望這篇文章對你有所幫助,尤其是剛剛接觸資料探勘以及大資料的同學,同時準備嘗試以案例為主的方式進行
【python資料探勘課程】十七.社交網路Networkx庫分析人物關係(初識篇)
這是《Python資料探勘課程》系列文章,也是我大資料金融學院上課的部分內容。本章主要講述複雜網路或社交網路基礎知識,通過Networkx擴充套件包繪製人物關係,並分析了班級學生的關係學院資訊。本篇文章為初始篇,基礎文章希望對你有所幫助,如果文章中存在錯誤或不足支援,還請海涵
【python資料探勘課程】二十.KNN最近鄰分類演算法分析詳解及平衡秤TXT資料集讀取
這是《Python資料探勘課程》系列文章,也是我這學期上課的部分內容及書籍的一個案例。本文主要講述KNN最近鄰分類演算法、簡單實現分析平衡秤資料集,希望這篇文章對大家有所幫助,同時提供些思路。內容包括:
Python資料探勘課程 五.線性迴歸知識及預測糖尿病例項
希望這篇文章對你有所幫助,尤其是剛剛接觸資料探勘以及大資料的同學,同時準備嘗試以案例為主的方式進行講解。如果文章中存在不足或錯誤的地方,還請海涵~ 同時這篇文章是我上課的內容,所以參考了一些知識,強烈推薦大家學習斯坦福的機器學習Ng教