
Pytorch 系列教程之一 使用Pytorch擬合多項式(多項式迴歸)
使用Pytorch來編寫神經網路具有很多優勢,比起Tensorflow,我認為Pytorch更加簡單,結構更加清晰。
希望通過實戰幾個Pytorch的例子,讓大家熟悉Pytorch的使用方法,包括資料集建立,各種網路層結構的定義,以及前向傳播與權重更新方式。
比如這裡給出

很顯然,這裡我們只需要假定
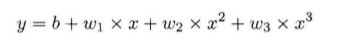
這裡我們只需要設定一個合適尺寸的全連線網路,根據不斷迭代,求出最接近的引數即可。
但是這裡需要思考一個問題,使用全連線網路結構是毫無疑問的,但是我們的輸入與輸出格式是什麼樣的呢?
只將一個x作為輸入合理嗎?顯然是不合理的,因為每一個神經元其實模擬的是wx+b的計算過程,無法模擬冪運算,所以顯然我們需要將x,x的平方,x的三次方,x的四次方組合成一個向量作為輸入,假設有n個不同的x值,我們就可以將n個組合向量合在一起組成輸入矩陣。
這一步程式碼如下:
def make_features(x):
x = x.unsqueeze(1)
return torch.cat([x ** i for i in range(1,4)] , 1)
我們需要生成一些隨機數作為網路輸入:
def get_batch(batch_size=32): random = torch.randn(batch_size) x = make_features(random) '''Compute the actual results''' y = f(x) if torch.cuda.is_available(): return Variable(x).cuda(), Variable(y).cuda() else: return Variable(x), Variable(y)
其中的f(x)定義如下:
w_target = torch.FloatTensor([0.5,3,2.4]).unsqueeze(1)
b_target = torch.FloatTensor([0.9])
def f(x):
return x.mm(w_target)+b_target[0]接下來定義模型:
class poly_model(nn.Module): def __init__(self): super(poly_model, self).__init__() self.poly = nn.Linear(3,1) def forward(self, x): out = self.poly(x) return out
if torch.cuda.is_available():
model = poly_model().cuda()
else:
model = poly_model()接下來我們定義損失函式和優化器:
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr = 1e-3)網路部件定義完後,開始訓練:
epoch = 0
while True:
batch_x,batch_y = get_batch()
output = model(batch_x)
loss = criterion(output,batch_y)
print_loss = loss.data[0]
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
if print_loss < 1e-3:
break到此我們的所有程式碼就敲完了,接下來我們開始詳細瞭解一下其中的一些程式碼。
在make_features()定義中,torch.cat是將計算出的向量拼接成矩陣。unsqueeze是作一個維度上的變化。
get_batch中,torch.randn是產生指定維度的隨機數,如果你的機器支援GPU加速,可以將Variable放在GPU上進行運算,類似語句含義相通。
x.mm是作矩陣乘法。
模型定義是重中之重,其實當你掌握Pytorch之後,你會發現模型定義是十分簡單的,各種基本的層結構都已經為你封裝好了。所有的層結構和損失函式都來自torch.nn,所有的模型構建都是從這個基類 nn.Module繼承的。模型定義中,__init__與forward是有模板的,大家可以自己體會。
nn.Linear是做一個線性的運算,引數的含義代表了輸入層與輸出層的結構,即3*1;在訓練階段,有幾行是Pytorch不同於別的框架的,首先loss是一個Variable,通過loss.data可以取出一個Tensor,再通過data[0]可以得到一個int或者float型別的值,我們才可以進行基本運算或者顯示。每次計算梯度之前,都需要將梯度歸零,否則梯度會疊加。個人覺得別的語句還是比較好懂的,如果有疑問可以在下方評論。
下面是我們的擬合結果
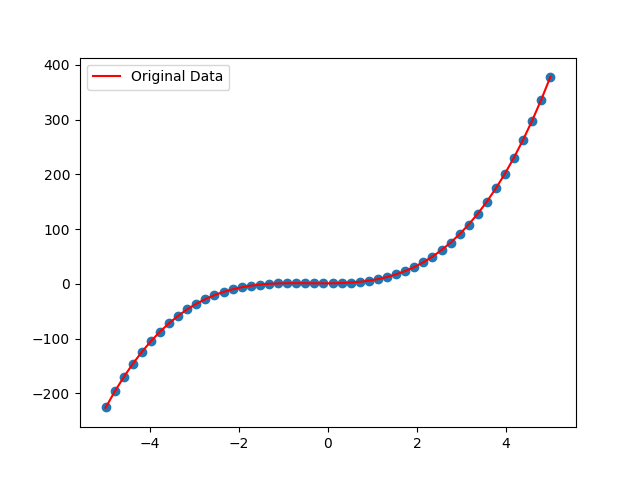
其實效果肯定會很好,因為只是一個非常簡單的全連線網路,希望大家通過這個小例子可以學到Pytorch的一些基本操作。往後我們會繼續更新,完整程式碼請戳,https://github.com/ZhichaoDuan/PytorchCourse
相關推薦
Pytorch 系列教程之一 使用Pytorch擬合多項式(多項式迴歸)
使用Pytorch來編寫神經網路具有很多優勢,比起Tensorflow,我認為Pytorch更加簡單,結構更加清晰。希望通過實戰幾個Pytorch的例子,讓大家熟悉Pytorch的使用方法,包括資料集建立,各種網路層結構的定義,以及前向傳播與權重更新方式。比如這裡給出
用Python開始機器學習(3:資料擬合與廣義線性迴歸)
機器學習中的預測問題通常分為2類:迴歸與分類。簡單的說迴歸就是預測數值,而分類是給資料打上標籤歸類。本文講述如何用Python進行基本的資料擬合,以及如何對擬合結果的誤差進行分析。本例中使用一個2次函式加上隨機的擾動來生成500個點,然後嘗試用1、2、100次方的多項式對該資
RabbitMQ系列教程之三:釋出\/訂閱(Publish\/Subscribe)
在前一個教程中,我們建立了一個工作佇列。工作佇列背後的假設是每個任務會被交付給一個【工人】。在這一部分我們將做一些完全不同的事情--我們將向多個【消費者】傳遞資訊。這種模式被稱為“釋出/訂閱”。 為了說明這種模式,我們將構建一個簡單的日誌系統。它將包括兩個程式,第一個將發
教你簡單解決過擬合問題(附公式)
作者:Ahmed Gad翻譯:韓海疇校對:丁楠雅本文約2000字,建議閱讀5分鐘。本文帶大家認識
RabbitMQ系列教程之二:工作隊列(Work Queues)
我們 one 排隊 設置 gem 異步 actor 獲得 targe 原文:RabbitMQ系列教程之二:工作隊列(Work Queues) 今天開始RabbitMQ教程的第二講,廢話不多說,直接進入話題。 (使用.NET 客戶端 進行事例演示)
[PyTorch小試牛刀]實戰一·使用PyTorch擬合曲線(對比PyTorch與TensorFlow實現的區別)
[PyTorch小試牛刀]實戰一·使用PyTorch擬合曲線 在深度學習入門的部落格中,我們用TensorFlow進行了擬合曲線,到達了不錯的效果。 我們現在使用PyTorch進行相同的曲線擬合,進而來比較一下TensorFlow與PyTorch的異同。 搭建神經網路進行訓練的步驟基本相
從頭學pytorch(七):dropout防止過擬合
上一篇講了防止過擬合的一種方式,權重衰減,也即在loss上加上一部分\(\frac{\lambda}{2n} \|\boldsymbol{w}\|^2\),從而使得w不至於過大,即不過分偏向某個特徵. 這一篇介紹另一種防止過擬合的方法,dropout,即丟棄某些神經元的輸出.由於每次訓練的過程裡,丟棄掉哪些神
RabbitMQ系列教程之一:我們從最簡單的事情開始!Hello World
model 系列教程 退出 utf 忽略 是你 必須 using chan 一、簡介 RabbitMQ是一個消息的代理器,用於接收和發送消息,你可以這樣想,他就是一個郵局,當您把需要寄送的郵件投遞到郵筒之時,你可以確定的是郵遞員先生肯定會把郵件發送到需要接收郵件的
intellij系列教程之一【激活intellij】
.com intel col title blog get img intellij com http://idea.lanyus.com/ 點擊以上鏈接進行激活! 如何在工具輸入大家自行摸索吧! intellij系列教程之一【激活intellij】
【REACT NATIVE 系列教程之一】觸控事件的兩種形式與四種TOUCHABLE元件詳解
本文是RN(React Native)系列教程第一篇,當然也要給自己的群做個廣告: React Native @Himi :126100395 剛建立的群,歡迎一起學習、討論、進步。本文主要講解兩點:1. PanResponder:觸控事件,用以獲取使用者手指所在螢幕的座標(x,y)或觸發、或滑動、或
VMware vSphere系列教程-安裝Windows Server 2012 R2(四)
vmware vsphere 安裝Windows2012 安裝Windows 2012 R2 操作系統 選擇windows 2012的iSO鏡像安裝步驟忽略。 安裝VMware Tools工具 更新系統補丁 更新系統補丁,修復漏洞,此步驟忽略VMware vSphere系列教程-安裝Windows
[TensorFlowJS只如初見]實戰四·使用TensorFlowJS擬合曲線(類似TensorFlow原生實現方法)
[TensorFlowJS只如初見]實戰四·使用TensorFlowJS擬合曲線(類似TensorFlow原生實現方法) 問題描述 擬合y= x*x -2x +3 + 0.1(-1到1的隨機值) 曲線 給定x範圍(0,3) 問題分析 在直線擬合部落格中,我們使用最簡單
隨機樣本一致性:一種用於影象分析和自動製圖的模型擬合模型(5)--(P4P的解析解)
(一)P4P問題的解析解 條件:已知物平面和像平面中的四對同名像點;透視中心到像平面的距離(即攝影系統的焦距);像平面中主光點的位置(位置,也就是像平面中的座標,該點是主光軸在像平面上的焦點); 求解:透視中心相對於物方座標系統下的3維位置。 符號說明: (1)像
R語言曲線擬合函式(繪圖)
曲線擬合:(線性迴歸方法:lm) 1、x排序 2、求線性迴歸方程並賦予一個新變數 z=lm(y~x+I(x^2)+...) 3、plot(x,y) #做y對x的散點圖 4、lines(x,fitted(z)) #新增擬合值對x的散點圖並連線曲線擬合:(nls) lm是將曲線直線化再做迴歸,
最詳細的基於R語言的Logistic Regression(Logistic迴歸)原始碼,包括擬合優度,Recall,Precision的計算
這篇日誌也確實是有感而發,我對R不熟悉,但實驗需要,所以簡單學了一下。發現無論是網上無數的教程,還是書本上的示例,在講Logistic Regression的時候就是給一個簡單的函式及輸出結果說明。從來都沒有講清楚幾件事情: 1. 怎樣用訓練資料訓練模型,然後在測試資料
tensorflow 邏輯迴歸之解決欠擬合問題(一)
本篇主要總結1.二分類邏輯迴歸簡單介紹 , 2.演算法的實現 3.對欠擬合問題的解決方法及實現(第二部分) 1.邏輯迴歸 邏輯迴歸主要用於非線性分類問題。具體思路是首先對特徵向量進行權重分配之後用 sigmoid 函式啟用。如下公式(1)(2) : h > 0.5時,分
tensorflow 邏輯回歸之解決欠擬合問題(一)
init eps 簡單 ack 進行 dict 測試 vmax legend 本篇主要總結1.二分類邏輯回歸簡單介紹 , 2.算法的實現 3.對欠擬合問題的解決方法及實現(第二部分) 1.邏輯回歸 邏輯回歸主要用於非線性分類問題。具體思路是首先對特征向量進行權重分配之後
過度擬合與正規化線性迴歸
過度擬合(over fitting):在擬合數據時,如果要包含每條訓練記錄資料,則很容易產生過度擬合,換句話說,過度擬合現象在特徵變數很多很多時容易產生。(如下圖2所示)
python應用系列教程——python操作office辦公軟體(excel)
全棧工程師開發手冊 (作者:欒鵬) 然後就可以使用python程式設計操作excel軟體了,excel軟體的啟動可能會比較慢,所以有可能要等待幾秒才能啟動成功。 python2.7下程式碼 #coding:utf-8 #py
線上視訊解析下載教程合集(值得收藏)
一、工具篇 二、教程篇 適用於手機上操作的教程 適用於電腦上操作的教程 手機和電腦上都適用的教程 三、常見疑問 1. 該用什麼瀏覽器呢? 蘋果手機上用Documents App的內建瀏覽器;其他手機用Chrome、UC、360、QQ等主流瀏覽器即可;電腦上用Chrom