
Python科學計算基礎模組Numpy及其應用

-
Numpy(Numeric Python)是應用Python進行科學計算時的基礎模組。它是一個提供多維陣列物件的Python庫,除此之外,還包含了多種衍生的物件(比如掩碼式陣列(masked arrays)或矩陣)以及一系列的為快速計算陣列而生的例程,包括數學運算,邏輯運算,形狀操作,排序,選擇,I/O,離散傅立葉變換,基本線性代數,基本統計運算,隨機模擬等等。
-
Numpy庫中最核心的部分是ndarray 物件。它封裝了同構資料型別的n維陣列,它的功能將通過演示程式碼的形式呈現。 NumPy陣列和標準Python序列之間有幾個重要區別:
(1)Numpy陣列在建立時就會有一個固定的尺寸,這一點和Python中的list資料型別(可以動態生長)是不同的。當Numpy陣列的尺寸發生改變時其實會刪除之前的而建立一個新的陣列。
(2)在一個Numpy陣列中的所有元素陣列型別要一致,並在記憶體中佔有相同的大小。這裡有一點例外:可以在Python的陣列中包含Numpy的物件,這樣的話就可以實現不同型別的元素。
(3)在資料量巨大時,使用Numpy進行高階資料運算和其他型別的操作是更為方便的。 通常情況下,這樣的操作比使用Python的內建序列更有效,執行程式碼更少。
(4)越來越多的用於數學和科學計算Python庫使用了Numpy,雖然這些第三方庫也留了Python內建序列的輸入介面,但是實際上在處理這些輸入前還是要轉成Numpy陣列,平切這些庫的輸出一般是Numpy陣列。換句話說,為了更好的使用當今大多數(甚至是絕大多數)用於數學/科學的Python庫,僅僅知道Python本身是遠遠不夠的。
在科學計算中序列的大小和速度是尤其重要的點。舉個簡單的例子:如果要將一個一維的序列a中的每一個數與另一個序列b(長度與a相同)。資料存放在python的list結構中,通過遍歷列表可以得到:
NumPy 是 MatLab 的替代之一:
NumPy - Ndarray 物件
NumPy 中定義的最重要的物件是稱為 ndarray 的 N 維陣列型別。 它描述相同型別的元素集合。 可以使用基於零的索引訪問集合中的專案。
ndarray中的每個元素在記憶體中使用相同大小的塊。 ndarray中的每個元素是資料型別物件的物件(稱為 dtype)。
從ndarray物件提取的任何元素(通過切片)由一個數組標量型別的 Python 物件表示。 下圖顯示了ndarray
dtype)和陣列標量型別之間的關係。
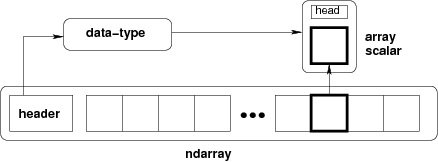
Ndarray
ndarray類的例項可以通過本教程後面描述的不同的陣列建立例程來構造。 基本的ndarray是使用 NumPy 中的陣列函式建立的,如下所示:
numpy.array
它從任何暴露陣列介面的物件,或從返回陣列的任何方法建立一個ndarray。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
上面的構造器接受以下引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | object 任何暴露陣列介面方法的物件都會返回一個數組或任何(巢狀)序列。 |
| 2. | dtype 陣列的所需資料型別,可選。 |
| 3. | copy 可選,預設為true,物件是否被複制。 |
| 4. | order C(按行)、F(按列)或A(任意,預設)。 |
| 5. | subok 預設情況下,返回的陣列被強制為基類陣列。 如果為true,則返回子類。 |
| 6. | ndimin 指定返回陣列的最小維數。 |
看看下面的例子來更好地理解。
示例 1
import numpy as np
a = np.array([1,2,3])
print a
輸出如下:
[1, 2, 3]
示例 2
# 多於一個維度
import numpy as np
a = np.array([[1, 2], [3, 4]])
print a
輸出如下:
[[1, 2]
[3, 4]]
示例 3
# 最小維度
import numpy as np
a = np.array([1, 2, 3,4,5], ndmin = 2)
print a
輸出如下:
[[1, 2, 3, 4, 5]]
示例 4
# dtype 引數
import numpy as np
a = np.array([1, 2, 3], dtype = complex)
print a
輸出如下:
[ 1.+0.j, 2.+0.j, 3.+0.j]
**ndarray ** 物件由計算機記憶體中的一維連續區域組成,帶有將每個元素對映到記憶體塊中某個位置的索引方案。 記憶體塊以按行(C 風格)或按列(FORTRAN 或 MatLab 風格)的方式儲存元素。
NumPy - 資料型別
NumPy 支援比 Python 更多種類的數值型別。 下表顯示了 NumPy 中定義的不同標量資料型別。
| 序號 | 資料型別及描述 |
|---|---|
| 1. | bool_ 儲存為一個位元組的布林值(真或假) |
| 2. | int_ 預設整數,相當於 C 的long,通常為int32或int64 |
| 3. | intc 相當於 C 的int,通常為int32或int64 |
| 4. | intp 用於索引的整數,相當於 C 的size_t,通常為int32或int64 |
| 5. | int8 位元組(-128 ~ 127) |
| 6. | int16 16 位整數(-32768 ~ 32767) |
| 7. | int32 32 位整數(-2147483648 ~ 2147483647) |
| 8. | int64 64 位整數(-9223372036854775808 ~ 9223372036854775807) |
| 9. | uint8 8 位無符號整數(0 ~ 255) |
| 10. | uint16 16 位無符號整數(0 ~ 65535) |
| 11. | uint32 32 位無符號整數(0 ~ 4294967295) |
| 12. | uint64 64 位無符號整數(0 ~ 18446744073709551615) |
| 13. | float_ float64的簡寫 |
| 14. | float16 半精度浮點:符號位,5 位指數,10 位尾數 |
| 15. | float32 單精度浮點:符號位,8 位指數,23 位尾數 |
| 16. | float64 雙精度浮點:符號位,11 位指數,52 位尾數 |
| 17. | complex_ complex128的簡寫 |
| 18. | complex64 複數,由兩個 32 位浮點表示(實部和虛部) |
| 19. | complex128 複數,由兩個 64 位浮點表示(實部和虛部) |
NumPy 數字型別是dtype(資料型別)物件的例項,每個物件具有唯一的特徵。 這些型別可以是np.bool_,np.float32等。
資料型別物件 (dtype)
資料型別物件描述了對應於陣列的固定記憶體塊的解釋,取決於以下方面:
-
資料型別(整數、浮點或者 Python 物件)
-
資料大小
-
位元組序(小端或大端)
-
在結構化型別的情況下,欄位的名稱,每個欄位的資料型別,和每個欄位佔用的記憶體塊部分。
-
如果資料型別是子序列,它的形狀和資料型別。
位元組順序取決於資料型別的字首<或>。 <意味著編碼是小端(最小有效位元組儲存在最小地址中)。 >意味著編碼是大端(最大有效位元組儲存在最小地址中)。
dtype可由一下語法構造:
numpy.dtype(object, align, copy)
引數為:
-
Object:被轉換為資料型別的物件。 -
Align:如果為true,則向欄位新增間隔,使其類似 C 的結構體。 -
Copy? 生成dtype物件的新副本,如果為flase,結果是內建資料型別物件的引用。
示例 1
# 使用陣列標量型別
import numpy as np
dt = np.dtype(np.int32)
print dt
輸出如下:
int32
示例 2
#int8,int16,int32,int64 可替換為等價的字串 'i1','i2','i4',以及其他。
import numpy as np
dt = np.dtype('i4')
print dt
輸出如下:
int32
示例 3
# 使用端記號
import numpy as np
dt = np.dtype('>i4')
print dt
輸出如下:
>i4
下面的例子展示了結構化資料型別的使用。 這裡聲明瞭欄位名稱和相應的標量資料型別。
示例 4
# 首先建立結構化資料型別。
import numpy as np
dt = np.dtype([('age',np.int8)])
print dt
輸出如下:
[('age', 'i1')]
示例 5
# 現在將其應用於 ndarray 物件
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print a
輸出如下:
[(10,) (20,) (30,)]
示例 6
# 檔名稱可用於訪問 age 列的內容
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print a['age']
輸出如下:
[10 20 30]
示例 7
以下示例定義名為 student 的結構化資料型別,其中包含字串欄位name,整數字段age和浮點欄位marks。 此dtype應用於ndarray物件。
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
print student
輸出如下:
[('name', 'S20'), ('age', 'i1'), ('marks', '<f4')])
示例 8
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print a
輸出如下:
[('abc', 21, 50.0), ('xyz', 18, 75.0)]
每個內建型別都有一個唯一定義它的字元程式碼:
-
'b':布林值 -
'i':符號整數 -
'u':無符號整數 -
'f':浮點 -
'c':複數浮點 -
'm':時間間隔 -
'M':日期時間 -
'O':Python 物件 -
'S', 'a':位元組串 -
'U':Unicode -
'V':原始資料(void)
NumPy - 陣列屬性
這一章中,我們會討論 NumPy 的多種陣列屬性。
ndarray.shape
這一陣列屬性返回一個包含陣列維度的元組,它也可以用於調整陣列大小。
示例 1
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
print a.shape
輸出如下:
(2, 3)
示例 2
# 這會調整陣列大小
import numpy as np
a = np.array([[1,2,3],[4,5,6]]) a.shape = (3,2)
print a
輸出如下:
[[1, 2]
[3, 4]
[5, 6]]
示例 3
NumPy 也提供了reshape函式來調整陣列大小。
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = a.reshape(3,2)
print b
輸出如下:
[[1, 2]
[3, 4]
[5, 6]]
ndarray.ndim
這一陣列屬性返回陣列的維數。
示例 1
# 等間隔數字的陣列
import numpy as np
a = np.arange(24) print a
輸出如下:
[0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
示例 2
# 一維陣列
import numpy as np
a = np.arange(24) a.ndim
# 現在調整其大小
b = a.reshape(2,4,3)
print b
# b 現在擁有三個維度
輸出如下:
[[[ 0, 1, 2]
[ 3, 4, 5]
[ 6, 7, 8]
[ 9, 10, 11]]
[[12, 13, 14]
[15, 16, 17]
[18, 19, 20]
[21, 22, 23]]]
numpy.itemsize
這一陣列屬性返回陣列中每個元素的位元組單位長度。
示例 1
# 陣列的 dtype 為 int8(一個位元組)
import numpy as np
x = np.array([1,2,3,4,5], dtype = np.int8)
print x.itemsize
輸出如下:
1
示例 2
# 陣列的 dtype 現在為 float32(四個位元組)
import numpy as np
x = np.array([1,2,3,4,5], dtype = np.float32)
print x.itemsize
輸出如下:
4
numpy.flags
ndarray物件擁有以下屬性。這個函式返回了它們的當前值。
| 序號 | 屬性及描述 |
|---|---|
| 1. | C_CONTIGUOUS (C) 陣列位於單一的、C 風格的連續區段內 |
| 2. | F_CONTIGUOUS (F) 陣列位於單一的、Fortran 風格的連續區段內 |
| 3. | OWNDATA (O) 陣列的記憶體從其它物件處借用 |
| 4. | WRITEABLE (W) 資料區域可寫入。 將它設定為flase會鎖定資料,使其只讀 |
| 5. | ALIGNED (A) 資料和任何元素會為硬體適當對齊 |
| 6. | UPDATEIFCOPY (U) 這個陣列是另一陣列的副本。當這個陣列釋放時,源陣列會由這個陣列中的元素更新 |
示例
下面的例子展示當前的標誌。
import numpy as np
x = np.array([1,2,3,4,5])
print x.flags
輸出如下:
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
UPDATEIFCOPY : False
NumPy - 陣列建立例程
新的ndarray物件可以通過任何下列陣列建立例程或使用低階ndarray建構函式構造。
numpy.empty
它建立指定形狀和dtype的未初始化陣列。 它使用以下建構函式:
numpy.empty(shape, dtype = float, order = 'C')
構造器接受下列引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | Shape 空陣列的形狀,整數或整數元組 |
| 2. | Dtype 所需的輸出陣列型別,可選 |
| 3. | Order 'C'為按行的 C 風格陣列,'F'為按列的 Fortran 風格陣列 |
示例
下面的程式碼展示空陣列的例子:
import numpy as np
x = np.empty([3,2], dtype = int)
print x
輸出如下:
[[22649312 1701344351]
[1818321759 1885959276]
[16779776 156368896]]
注意:陣列元素為隨機值,因為它們未初始化。
numpy.zeros
返回特定大小,以 0 填充的新陣列。
numpy.zeros(shape, dtype = float, order = 'C')
構造器接受下列引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | Shape 空陣列的形狀,整數或整數元組 |
| 2. | Dtype 所需的輸出陣列型別,可選 |
| 3. | Order 'C'為按行的 C 風格陣列,'F'為按列的 Fortran 風格陣列 |
示例 1
# 含有 5 個 0 的陣列,預設型別為 float
import numpy as np
x = np.zeros(5)
print x
輸出如下:
[ 0. 0. 0. 0. 0.]
示例 2
import numpy as np
x = np.zeros((5,), dtype = np.int)
print x
輸出如下:
[0 0 0 0 0]
示例 3
# 自定義型別
import numpy as np
x = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')])
print x
輸出如下:
[[(0,0)(0,0)]
[(0,0)(0,0)]]
numpy.ones
返回特定大小,以 1 填充的新陣列。
numpy.ones(shape, dtype = None, order = 'C')
構造器接受下列引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | Shape 空陣列的形狀,整數或整數元組 |
| 2. | Dtype 所需的輸出陣列型別,可選 |
| 3. | Order 'C'為按行的 C 風格陣列,'F'為按列的 Fortran 風格陣列 |
示例 1
# 含有 5 個 1 的陣列,預設型別為 float
import numpy as np
x = np.ones(5) print x
輸出如下:
[ 1. 1. 1. 1. 1.]
示例 2
import numpy as np
x = np.ones([2,2], dtype = int)
print x
輸出如下:
[[1 1]
[1 1]]
NumPy - 來自現有資料的陣列
這一章中,我們會討論如何從現有資料建立陣列。
numpy.asarray
此函式類似於numpy.array,除了它有較少的引數。 這個例程對於將 Python 序列轉換為ndarray非常有用。
numpy.asarray(a, dtype = None, order = None)
構造器接受下列引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | a 任意形式的輸入引數,比如列表、列表的元組、元組、元組的元組、元組的列表 |
| 2. | dtype 通常,輸入資料的型別會應用到返回的ndarray |
| 3. | order 'C'為按行的 C 風格陣列,'F'為按列的 Fortran 風格陣列 |
下面的例子展示瞭如何使用asarray函式:
示例 1
# 將列表轉換為 ndarray
import numpy as np
x = [1,2,3]
a = np.asarray(x)
print a
輸出如下:
[1 2 3]
示例 2
# 設定了 dtype
import numpy as np
x = [1,2,3]
a = np.asarray(x, dtype = float)
print a
輸出如下:
[ 1. 2. 3.]
示例 3
# 來自元組的 ndarray
import numpy as np
x = (1,2,3)
a = np.asarray(x)
print a
輸出如下:
[1 2 3]
示例 4
# 來自元組列表的 ndarray
import numpy as np
x = [(1,2,3),(4,5)]
a = np.asarray(x)
print a
輸出如下:
[(1, 2, 3) (4, 5)]
numpy.frombuffer
此函式將緩衝區解釋為一維陣列。 暴露緩衝區介面的任何物件都用作引數來返回ndarray。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
構造器接受下列引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | buffer 任何暴露緩衝區藉口的物件 |
| 2. | dtype 返回陣列的資料型別,預設為float |
| 3. | count 需要讀取的資料數量,預設為-1,讀取所有資料 |
| 4. | offset 需要讀取的起始位置,預設為0 |
示例
下面的例子展示了frombuffer函式的用法。
import numpy as np
s = 'Hello World'
a = np.frombuffer(s, dtype = 'S1')
print a
輸出如下:
['H' 'e' 'l' 'l' 'o' ' ' 'W' 'o' 'r' 'l' 'd']
numpy.fromiter
此函式從任何可迭代物件構建一個ndarray物件,返回一個新的一維陣列。
numpy.fromiter(iterable, dtype, count = -1)
構造器接受下列引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | iterable 任何可迭代物件 |
| 2. | dtype 返回陣列的資料型別 |
| 3. | count 需要讀取的資料數量,預設為-1,讀取所有資料 |
以下示例展示瞭如何使用內建的range()函式返回列表物件。 此列表的迭代器用於形成ndarray物件。
示例 1
# 使用 range 函式建立列表物件
import numpy as np
list = range(5)
print list
輸出如下:
[0, 1, 2, 3, 4]
示例 2
# 從列表中獲得迭代器
import numpy as np
list = range(5)
it = iter(list)
# 使用迭代器建立 ndarray
x = np.fromiter(it, dtype = float)
print x
輸出如下:
[0. 1. 2. 3. 4.]
NumPy - 來自數值範圍的陣列
這一章中,我們會學到如何從數值範圍建立陣列。
numpy.arange
這個函式返回ndarray物件,包含給定範圍內的等間隔值。
numpy.arange(start, stop, step, dtype)
構造器接受下列引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | start 範圍的起始值,預設為0 |
| 2. | stop 範圍的終止值(不包含) |
| 3. | step 兩個值的間隔,預設為1 |
| 4. | dtype 返回ndarray的資料型別,如果沒有提供,則會使用輸入資料的型別。 |
下面的例子展示瞭如何使用該函式:
示例 1
import numpy as np
x = np.arange(5)
print x
輸出如下:
[0 1 2 3 4]
示例 2
import numpy as np
# 設定了 dtype
x = np.arange(5, dtype = float)
print x
輸出如下:
[0. 1. 2. 3. 4.]
示例 3
# 設定了起始值和終止值引數
import numpy as np
x = np.arange(10,20,2)
print x
輸出如下:
[10 12 14 16 18]
numpy.linspace
此函式類似於arange()函式。 在此函式中,指定了範圍之間的均勻間隔數量,而不是步長。 此函式的用法如下。
numpy.linspace(start, stop, num, endpoint, retstep, dtype)
構造器接受下列引數:
| 序號 | 引數及描述 |
|---|---|
| 1. | start 序列的起始值 |
| 2. | stop 序列的終止值,如果endpoint為true,該值包含於序列中 |
| 3. | num 要生成的等間隔樣例數量,預設為50 |
| 4. | endpoint 序列中是否包含stop值,預設為ture |
| 5. | retstep 如果為true,返回樣例,以及連續數字之間的步長 |
| 6. | dtype 輸出ndarray的資料型別 |
下面的例子展示了linspace函式的用法。
示例 1
import numpy as np
x = np.linspace(10,20,5)
print x
輸出如下:
[10. 12.5 15. 17.5 20.]
示例 2
# 將 endpoint 設為 false
import numpy as np
x = np.linspace(10,20, 5, endpoint = False)
print x
輸出如下:
[10. 12. 14. 16. 18.]
示例 3
# 輸出 retstep 值
import numpy as np
x = np.linspace(1,2,5, retstep = True)
print x
# 這裡的 retstep 為 0.25
輸出如下:
(array([ 1. , 1.25, 1.5 , 1.75, 2. ]), 0.25)
numpy.logspace
此函式返回一個ndarray物件,其中包含在對數刻度上均勻分佈的數字。 刻度的開始和結束端點是某個底數的冪,通常為 10。
numpy.logscale(start, stop, num, endpoint, base, dtype)
logspace函式的輸出由以下引數決定:
| 序號 | 引數及描述 |
|---|---|
| 1. | start 起始值是base ** start |
| 2. | stop 終止值是base ** stop |
| 3. | num 範圍內的數值數量,預設為50 |
| 4. | endpoint 如果為true,終止值包含在輸出陣列當中 |
| 5. | base 對數空間的底數,預設為10 |
| 6. | dtype 輸出陣列的資料型別,如果沒有提供,則取決於其它引數 |
下面的例子展示了logspace函式的用法。
示例 1
import numpy as np
# 預設底數是 10
a = np.logspace(1.0, 2.0, num = 10)
print a
輸出如下:
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402
35.93813664 46.41588834 59.94842503 77.42636827 100. ]
示例 2
# 將對數空間的底數設定為 2
import numpy as np
a = np.logspace(1,10,num = 10, base = 2)
print a
輸出如下:
[ 2. 4. 8. 16. 32. 64. 128. 256. 512. 1024.]
NumPy - 切片和索引
ndarray物件的內容可以通過索引或切片來訪問和修改,就像 Python 的內建容器物件一樣。
如前所述,ndarray物件中的元素遵循基於零的索引。 有三種可用的索引方法型別: 欄位訪問,基本切片和高階索引。
基本切片是 Python 中基本切片概念到 n 維的擴充套件。 通過將start,stop和step引數提供給內建的slice函式來構造一個 Python slice物件。 此slice物件被傳遞給陣列來提取陣列的一部分。
示例 1
import numpy as np
a = np.arange(10)
s = slice(2,7,2)
print a[s]
輸出如下:
[2 4 6]
在上面的例子中,ndarray物件由arange()函式建立。 然後,分別用起始,終止和步長值2,7和2定義切片物件。 當這個切片物件傳遞給ndarray時,會對它的一部分進行切片,從索引2到7,步長為2。
通過將由冒號分隔的切片引數(start:stop:step)直接提供給ndarray物件,也可以獲得相同的結果。
示例 2
import numpy as np
a = np.arange(10)
b = a[2:7:2]
print b
輸出如下:
[2 4 6]
如果只輸入一個引數,則將返回與索引對應的單個專案。 如果使用a:,則從該索引向後的所有專案將被提取。 如果使用兩個引數(以:分隔),則對兩個索引(不包括停止索引)之間的元素以預設步驟進行切片。
示例 3
# 對單個元素進行切片
import numpy as np
a = np.arange(10)
b = a[5]
print b
輸出如下:
5
示例 4
# 對始於索引的元素進行切片
import numpy as np
a = np.arange(10)
print a[2:]
輸出如下:
[2 3 4 5 6 7 8 9]
示例 5
# 對索引之間的元素進行切片
import numpy as np
a = np.arange(10)
print a[2:5]
輸出如下:
[2 3 4]
上面的描述也可用於多維ndarray。
示例 6
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print a
# 對始於索引的元素進行切片
print '現在我們從索引 a[1:] 開始對陣列切片'
print a[1:]
輸出如下:
[[1 2 3]
[3 4 5]
[4 5 6]]
現在我們從索引 a[1:] 開始對陣列切片
[[3 4 5]
[4 5 6]]
切片還可以包括省略號(...),來使選擇元組的長度與陣列的維度相同。 如果在行位置使用省略號,它將返回包含行中元素的ndarray。
示例 7
# 最開始的陣列
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print '我們的陣列是:'
print a
print '\n'
# 這會返回第二列元素的陣列:
print '第二列的元素是:'
print a[...,1]
print '\n'
# 現在我們從第二行切片所有元素:
print '第二行的元素是:'
print a[1,...]
print '\n'
# 現在我們從第二列向後切片所有元素:
print '第二列及其剩餘元素是:'
print a[...,1:]
輸出如下:
我們的陣列是:
[[1 2 3]
[3 4 5]
[4 5 6]]
第二列的元素是:
[2 4 5]
第二行的元素是:
[3 4 5]
第二列及其剩餘元素是:
[[2 3]
[4 5]
[5 6]]
NumPy - 高階索引
如果一個ndarray是非元組序列,資料型別為整數或布林值的ndarray,或者至少一個元素為序列物件的元組,我們就能夠用它來索引ndarray。高階索引始終返回資料的副本。 與此相反,切片只提供了一個檢視。
有兩種型別的高階索引:整數和布林值。
整數索引
這種機制有助於基於 N 維索引來獲取陣列中任意元素。 每個整數陣列表示該維度的下標值。 當索引的元素個數就是目標ndarray的維度時,會變得相當直接。
以下示例獲取了ndarray物件中每一行指定列的一個元素。 因此,行索引包含所有行號,列索引指定要選擇的元素。
示例 1
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
print y
輸出如下:
[1 4 5]
該結果包括陣列中(0,0),(1,1)和(2,0)位置處的元素。
下面的示例獲取了 4X3 陣列中的每個角處的元素。 行索引是[0,0]和[3,3],而列索引是[0,2]和[0,2]。
示例 2
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print '我們的陣列是:'
print x
print '\n'
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print '這個陣列的每個角處的元素是:'
print y
輸出如下:
我們的陣列是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
這個陣列的每個角處的元素是:
[[ 0 2]
[ 9 11]]
返回的結果是包含每個角元素的ndarray物件。
高階和基本索引可以通過使用切片:或省略號...與索引陣列組合。 以下示例使用slice作為列索引和高階索引。 當切片用於兩者時,結果是相同的。 但高階索引會導致複製,並且可能有不同的記憶體佈局。
示例 3
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print '我們的陣列是:'
print x
print '\n'
# 切片
z = x[1:4,1:3]
print '切片之後,我們的陣列變為:'
print z
print '\n'
# 對列使用高階索引
y = x[1:4,[1,2]]
print '對列使用高階索引來切片:'
print y
輸出如下:
我們的陣列是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
切片之後,我們的陣列變為:
[[ 4 5]
[ 7 8]
[10 11]]
對列使用高階索引來切片:
[[ 4 5]
[ 7 8]
[10 11]]
布林索引
當結果物件是布林運算(例如比較運算子)的結果時,將使用此型別的高階索引。
示例 1
這個例子中,大於 5 的元素會作為布林索引的結果返回。
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print '我們的陣列是:'
print x
print '\n'
# 現在我們會打印出大於 5 的元素
print '大於 5 的元素是:'
print x[x > 5]
輸出如下:
我們的陣列是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
大於 5 的元素是:
[ 6 7 8 9 10 11]
示例 2
這個例子使用了~(取補運算子)來過濾NaN。
import numpy as np
a = np.array([np.nan, 1,2,np.nan,3,4,5])
print a[~np.isnan(a)]
輸出如下:
[ 1. 2. 3. 4. 5.]
示例 3
以下示例顯示如何從陣列中過濾掉非複數元素。
import numpy as np
a = np.array([1, 2+6j, 5, 3.5+5j])
print a[np.iscomplex(a)]
輸出如下:
[2.0+6.j 3.5+5.j]
NumPy - 廣播
術語廣播是指 NumPy 在算術運算期間處理不同形狀的陣列的能力。 對陣列的算術運算通常在相應的元素上進行。 如果兩個陣列具有完全相同的形狀,則這些操作被無縫執行。
示例 1
import numpy as np
a = np.array([1,2,3,4])
b = np.array([10,20,30,40])
c = a * b
print c
輸出如下:
[10 40 90 160]
如果兩個陣列的維數不相同,則元素到元素的操作是不可能的。 然而,在 NumPy 中仍然可以對形狀不相似的陣列進行操作,因為它擁有廣播功能。 較小的陣列會廣播到較大陣列的大小,以便使它們的形狀可相容。
如果滿足以下規則,可以進行廣播:
-
ndim較小的陣列會在前面追加一個長度為 1 的維度。 -
輸出陣列的每個維度的大小是輸入陣列該維度大小的最大值。
-
如果輸入在每個維度中的大小與輸出大小匹配,或其值正好為 1,則在計算中可它。
-
如果輸入的某個維度大小為 1,則該維度中的第一個資料元素將用於該維度的所有計算。
如果上述規則產生有效結果,並且滿足以下條件之一,那麼陣列被稱為可廣播的。
-
陣列擁有相同形狀。
-
陣列擁有相同的維數,每個維度擁有相同長度,或者長度為 1。
-
陣列擁有極少的維度,可以在其前面追加長度為 1 的維度,使上述條件成立。
下面的例稱展示了廣播的示例。
示例 2
import numpy as np
a = np.array([[0.0,0.0,0.0],[10.0,10.0,10.0],[20.0,20.0,20.0],[30.0,30.0,30.0]])
b = np.array([1.0,2.0,3.0])
print '第一個陣列:'
print a
print '\n'
print '第二個陣列:'
print b
print '\n'
print '第一個陣列加第二個陣列:'
print a + b
輸出如下:
第一個陣列:
[[ 0. 0. 0.]
[ 10. 10. 10.]
[ 20. 20. 20.]
[ 30. 30. 30.]]
第二個陣列:
[ 1. 2. 3.]
第一個陣列加第二個陣列:
[[ 1. 2. 3.]
[ 11. 12. 13.]
[ 21. 22. 23.]
[ 31. 32. 33.]]
下面的圖片展示了陣列b如何通過廣播來與陣列a相容。
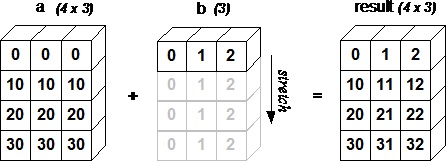
array
NumPy - 陣列上的迭代
NumPy 包包含一個迭代器物件numpy.nditer。 它是一個有效的多維迭代器物件,可以用於在陣列上進行迭代。 陣列的每個元素可使用 Python 的標準Iterator介面來訪問。
讓我們使用arange()函式建立一個 3X4 陣列,並使用nditer對它進行迭代。
示例 1
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始陣列是:'
print a print '\n'
print '修改後的陣列是:'
for x in np.nditer(a):
print x,
輸出如下:
原始陣列是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
修改後的陣列是:
0 5 10 15 20 25 30 35 40 45 50 55
示例 2
迭代的順序匹配陣列的內容佈局,而不考慮特定的排序。 這可以通過迭代上述陣列的轉置來看到。
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始陣列是:'
print a
print '\n'
print '原始陣列的轉置是:'
b = a.T
print b
print '\n'
print '修改後的陣列是:'
for x in np.nditer(b):
print x,
輸出如下:
原始陣列是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
原始陣列的轉置是:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
修改後的陣列是:
0 5 10 15 20 25 30 35 40 45 50 55
迭代順序
如果相同元素使用 F 風格順序儲存,則迭代器選擇以更有效的方式對陣列進行迭代。
示例 1
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始陣列是:'
print a print '\n'
print '原始陣列的轉置是:'
b = a.T
print b
print '\n'
print '以 C 風格順序排序:'
c = b.copy(order='C')
print c for x in np.nditer(c):
print x,
print '\n'
print '以 F 風格順序排序:'
c = b.copy(order='F')
print c
for x in np.nditer(c):
print x,
輸出如下:
原始陣列是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
原始陣列的轉置是:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
以 C 風格順序排序:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
0 20 40 5 25 45 10 30 50 15 35 55
以 F 風格順序排序:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
0 5 10 15 20 25 30 35 40 45 50 55
示例 2
可以通過顯式提醒,來強制nditer物件使用某種順序:
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始陣列是:'
print a
print '\n'
print '以 C 風格順序排序:'
for x in np.nditer(a, order = 'C'):
print x,
print '\n'
print '以 F 風格順序排序:'
for x in np.nditer(a, order = 'F'):
print x,
輸出如下:
原始陣列是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
以 C 風格順序排序:
0 5 10 15 20 25 30 35 40 45 50 55
以 F 風格順序排序:
0 20 40 5 25 45 10 30 50 15 35 55
修改陣列的值
nditer物件有另一個可選引數op_flags。 其預設值為只讀,但可以設定為讀寫或只寫模式。 這將允許使用此迭代器修改陣列元素。
示例
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始陣列是:'
print a
print '\n'
for x in np.nditer(a, op_flags=['readwrite']):
x[...]=2*x
print '修改後的陣列是:'
print a
輸出如下:
原始陣列是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
修改後的陣列是:
[[ 0 10 20 30]
[ 40 50 60 70]
[ 80 90 100 110]]
外部迴圈
nditer類的構造器擁有flags引數,它可以接受下列值:
| 序號 | 引數及描述 |
|---|---|
| 1. | c_index 可以跟蹤 C 順序的索引 |
| 2. | f_index 可以跟蹤 Fortran 順序的索引 |
| 3. | multi-index 每次迭代可以跟蹤一種索引型別 |
| 4. | external_loop 給出的值是具有多個值的一維陣列,而不是零維陣列 |
示例
在下面的示例中,迭代器遍歷對應於每列的一維陣列。
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始陣列是:'
print a
print '\n'
print '修改後的陣列是:'
for x in np.nditer(a, flags = ['external_loop'], order = 'F'):
print x,
輸出如下:
原始陣列是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
修改後的陣列是:
[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]
廣播迭代
如果兩個陣列是可廣播的,nditer組合物件能夠同時迭代它們。 假設陣列a具有維度 3X4,並且存在維度為 1X4 的另一個數組b,則使用以下型別的迭代器(陣列b被廣播到a的大小)。
示例
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '第一個陣列:'
print a
print '\n'
print '第二個陣列:'
b = np.array([1, 2, 3, 4], dtype = int)
print b
print '\n'
print '修改後的陣列是:'
for x,y in np.nditer([a,b]):
print "%d:%d" % (x,y),
輸出如下:
第一個陣列:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
第二個陣列:
[1 2 3 4]
修改後的陣列是:
0:1 5:2 10:3 15:4 20:1 25:2 30:3 35:4 40:1 45:2 50:3 55:4
NumPy - 陣列操作
NumPy包中有幾個例程用於處理ndarray物件中的元素。 它們可以分為以下型別:
修改形狀
| 序號 | 形狀及描述 |
|---|---|
| 1. | reshape 不改變資料的條件下修改形狀 |
| 2. | flat 陣列上的一維迭代器 |
| 3. | flatten 返回摺疊為一維的陣列副本 |
| 4. | ravel 返回連續的展開陣列 |
numpy.reshape
這個函式在不改變資料的條件下修改形狀,它接受如下引數:
numpy.reshape(arr, newshape, order')
其中:
arr:要修改形狀的陣列newshape:整數或者整數陣列,新的形狀應當相容原有形狀order:'C'為 C 風格順序,'F'為 F 風格順序,'A'為保留原順序。
例子
import numpy as np
a = np.arange(8)
print '原始陣列:'
print a
print '\n'
b = a.reshape(4,2)
print '修改後的陣列:'
print b
輸出如下:
原始陣列:
[0 1 2 3 4 5 6 7]
修改後的陣列:
[[0 1]
[2 3]
[4 5]
[6 7]]
numpy.ndarray.flat
該函式返回陣列上的一維迭代器,行為類似 Python 內建的迭代器。
例子
import numpy as np
a = np.arange(8).reshape(2,4)
print '原始陣列:'
print a
print '\n'
print '呼叫 flat 函式之後:'
# 返回展開陣列中的下標的對應元素
print a.flat[5]
輸出如下:
原始陣列:
[[0 1 2 3]
[4 5 6 7]]
呼叫 flat 函式之後:
5
numpy.ndarray.flatten
該函式返回摺疊為一維的陣列副本,函式接受下列引數:
ndarray.flatten(order)
其中:
order:'C'-- 按行,'F'-- 按列,'A'-- 原順序,'k'-- 元素在記憶體中的出現順序。
例子
import numpy as np
a = np.arange(8).reshape(2,4)
print '原陣列:'
print a
print '\n'
# default is column-major
print '展開的陣列:'
print a.flatten()
print '\n'
print '以 F 風格順序展開的陣列:'
print a.flatten(order = 'F')
輸出如下:
原陣列:
[[0 1 2 3]
[4 5 6 7]]
展開的陣列:
[0 1 2 3 4 5 6 7]
以 F 風格順序展開的陣列:
[0 4 1 5 2 6 3 7]
numpy.ravel
這個函式返回展開的一維陣列,並且按需生成副本。返回的陣列和輸入陣列擁有相同資料型別。這個函式接受兩個引數。
numpy.ravel(a, order)
構造器接受下列引數:
order:'C'-- 按行,'F'-- 按列,'A'-- 原順序,'k'-- 元素在記憶體中的出現順序。
例子
import numpy as np
a = np.arange(8).reshape(2,4)
print '原陣列:'
print a
print '\n'
print '呼叫 ravel 函式之後:'
print a.ravel()
print '\n'
print '以 F 風格順序呼叫 ravel 函式之後:'
print a.ravel(order = 'F')
原陣列:
[[0 1 2 3]
[4 5 6 7]]
呼叫 ravel 函式之後:
[0 1 2 3 4 5 6 7]
以 F 風格順序呼叫 ravel 函式之後:
[0 4 1 5 2 6 3 7]
翻轉操作
| 序號 | 操作及描述 |
|---|---|
| 1. | transpose 翻轉陣列的維度 |
| 2. | ndarray.T 和self.transpose()相同 |
| 3. | rollaxis 向後滾動指定的軸 |
| 4. | swapaxes 互換陣列的兩個軸 |
numpy.transpose
這個函式翻轉給定陣列的維度。如果可能的話它會返回一個檢視。函式接受下列引數:
numpy.transpose(arr, axes)
其中:
arr:要轉置的陣列axes:整數的列表,對應維度,通常所有維度都會翻轉。
例子
import numpy as np
a = np.arange(12).reshape(3,4)
print '原陣列:'
print a
print '\n'
print '轉置陣列:'
print np.transpose(a)
輸出如下:
原陣列:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
轉置陣列:
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
numpy.ndarray.T
該函式屬於ndarray類,行為類似於numpy.transpose。
例子
import numpy as np
a = np.arange(12).reshape(3,4)
print '原陣列:'
print a
print '\n'
print '轉置陣列:'
print a.T
輸出如下:
原陣列:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
轉置陣列:
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
numpy.rollaxis
該函式向後滾動特定的軸,直到一個特定位置。這個函式接受三個引數:
numpy.rollaxis(arr, axis, start)
其中:
arr:輸入陣列axis:要向後滾動的軸,其它軸的相對位置不會改變start:預設為零,表示完整的滾動。會滾動到特定位置。
例子
# 建立了三維的 ndarray
import numpy as np
a = np.arange(8).reshape(2,2,2)
print '原陣列:'
print a
print '\n'
# 將軸 2 滾動到軸 0(寬度到深度)
print '呼叫 rollaxis 函式:'
print np.rollaxis(a,2)
# 將軸 0 滾動到軸 1:(寬度到高度)
print '\n'
print '呼叫 rollaxis 函式:'
print np.rollaxis(a,2,1)
輸出如下:
原陣列:
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
呼叫 rollaxis 函式:
[[[0 2]
[4 6]]
[[1 3]
[5 7]]]
呼叫 rollaxis 函式:
[[[0 2]
[1 3]]
[[4 6]
[5 7]]]
numpy.swapaxes
該函式交換陣列的兩個軸。對於 1.10 之前的 NumPy 版本,會返回交換後陣列的試圖。這個函式接受下列引數:
numpy.swapaxes(arr, axis1, axis2)
arr:要交換其軸的輸入陣列axis1:對應第一個軸的整數axis2:對應第二個軸的整數
# 建立了三維的 ndarray
import numpy as np
a = np.arange(8).reshape(2,2,2)
print '原陣列:'
print a
print '\n'
# 現在交換軸 0(深度方向)到軸 2(寬度方向)
print '呼叫 swapaxes 函式後的陣列:'
print np.swapaxes(a, 2, 0)
輸出如下:
原陣列:
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
呼叫 swapaxes 函式後的陣列:
[[[0 4]
[2 6]]
[[1 5]
[3 7]]]
修改維度
| 序號 | 維度和描述 |
|---|---|
| 1. | broadcast 產生模仿廣播的物件 |
| 2. | broadcast_to 將陣列廣播到新形狀 |
| 3. | expand_dims 擴充套件陣列的形狀 |
| 4. | squeeze 從陣列的形狀中刪除單維條目 |
broadcast
如前所述,NumPy 已經內建了對廣播的支援。 此功能模仿廣播機制。 它返回一個物件,該物件封裝了將一個數組廣播到另一個數組的結果。
該函式使用兩個陣列作為輸入引數。 下面的例子說明了它的用法。
import numpy as np
x = np.array([[1], [2], [3]])
y = np.array([4, 5, 6])
# 對 y 廣播 x
b = np.broadcast(x,y)
# 它擁有 iterator 屬性,基於自身元件的迭代器元組
print '對 y 廣播 x:'
r,c = b.iters
print r.next(), c.next()
print r.next(), c.next()
print '\n'
# shape 屬性返回廣播物件的形狀
print '廣播物件的形狀:'
print b.shape
print '\n'
# 手動使用 broadcast 將 x 與 y 相加
b = np.broadcast(x,y)
c = np.empty(b.shape)
print '手動使用 broadcast 將 x 與 y 相加:'
print c.shape
print '\n'
c.flat = [u + v for (u,v) in b]
print '呼叫 flat 函式:'
print c
print '\n'
# 獲得了和 NumPy 內建的廣播支援相同的結果
print 'x 與 y 的和:'
print x + y
輸出如下:
對 y 廣播 x:
1 4
1 5
廣播物件的形狀:
(3, 3)
手動使用 broadcast 將 x 與 y 相加:
(3, 3)
呼叫 flat 函式:
[[ 5. 6. 7.]
[ 6. 7. 8.]
[ 7. 8. 9.]]
x 與 y 的和:
[[5 6 7]
[6 7 8]
[7 8 9]]
numpy.broadcast_to
此函式將陣列廣播到新形狀。 它在原始陣列上返回只讀檢視。 它通常不連續。 如果新形狀不符合 NumPy 的廣播規則,該函式可能會丟擲ValueError。
注意 - 此功能可用於 1.10.0 及以後的版本。
該函式接受以下引數。
numpy.broadcast_to(array, shape, subok)
例子
import numpy as np
a = np.arange(4).reshape(1,4)
print '原陣列:'
print a
print '\n'
print '呼叫 broadcast_to 函式之後:'
print np.broadcast_to(a,(4,4))
輸出如下:
[[0 1 2 3]
[0 1 2 3]
[0 1 2 3]
[0 1 2 3]]
numpy.expand_dims
函式通過在指定位置插入新的軸來擴充套件陣列形狀。該函式需要兩個引數:
numpy.expand_dims(arr, axis)
其中:
arr:輸入陣列axis:新軸插入的位置
例子
import numpy as np
x = np.array(([1,2],[3,4]))
print '陣列 x:'
print x
print '\n'
y = np.expand_dims(x, axis = 0)
print '陣列 y:'
print y
print '\n'
print '陣列 x 和 y 的形狀:'
print x.shape, y.shape
print '\n'
# 在位置 1 插入軸
y = np.expand_dims(x, axis = 1)
print '在位置 1 插入軸之後的陣列 y:'
print y
print '\n'
print 'x.ndim 和 y.ndim:'
print x.ndim,y.ndim
print '\n'
print 'x.shape 和 y.shape:'
print x.shape, y.shape
輸出如下:
陣列 x:
[[1 2]
[3 4]]
陣列 y:
[[[1 2]
[3 4]]]
陣列 x 和 y 的形狀:
(2, 2) (1, 2, 2)
在位置 1 插入軸之後的陣列 y:
[[[1 2]]
[[3 4]]]
x.shape 和 y.shape:
2 3
x.shape and y.shape:
(2, 2) (2, 1, 2)
numpy.squeeze
函式從給定陣列的形狀中刪除一維條目。 此函式需要兩個引數。
numpy.squeeze(arr, axis)
其中:
arr:輸入陣列axis:整數或整數元組,用於選擇形狀中單一維度條目的子集
例子
import numpy as np
x = np.arange(9).reshape(1,3,3)
print '陣列 x:'
print x
print '\n'
y = np.squeeze(x)
print '陣列 y:'
print y
print '\n'
print '陣列 x 和 y 的形狀:'
print x.shape, y.shape
輸出如下:
陣列 x:
[[[0 1 2]
[3 4 5]
[6 7 8]]]
陣列 y:
[[0 1 2]
[3 4 5]
[6 7 8]]
陣列 x 和 y 的形狀:
(1, 3, 3) (3, 3)
陣列的連線
| 序號 | 陣列及描述 |
|---|---|
| 1. | concatenate 沿著現存的軸連線資料序列 |
| 2. | stack 沿著新軸連線陣列序列 |
| 3. | hstack 水平堆疊序列中的陣列(列方向) |
| 4. | vstack 豎直堆疊序列中的陣列(行方向) |
numpy.concatenate
陣列的連線是指連線。 此函式用於沿指定軸連線相同形狀的兩個或多個數組。 該函式接受以下引數。
numpy.concatenate((a1, a2, ...), axis)
其中:
a1, a2, ...:相同型別的陣列序列axis:沿著它連線陣列的軸,預設為 0
例子
import numpy as np
a = np.array([[1,2],[3,4]])
print '第一個陣列:'
print a
print '\n'
b = np.array([[5,6],[7,8]])
print '第二個陣列:'
print b
print '\n'
# 兩個陣列的維度相同
print '沿軸 0 連線兩個陣列:'
print np.concatenate((a,b))
print '\n'
print '沿軸 1 連線兩個陣列:'
print np.concatenate((a,b),axis = 1)
輸出如下:
第一個陣列:
[[1 2]
[3 4]]
第二個陣列:
[[5 6]
[7 8]]
沿軸 0 連線兩個陣列:
[[1 2]
[3 4]
[5 6]
[7 8]]
沿軸 1 連線兩個陣列:
[[1 2 5 6]
[3 4 7 8]]
numpy.stack
此函式沿新軸連線陣列序列。 此功能新增自 NumPy 版本 1.10.0。 需要提供以下引數。
numpy.stack(ar