論文筆記:ShuffleNet v1
阿新 • • 發佈:2019-01-12
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
ShuffleNet v1
1、四個問題
- 要解決什麼問題?
- 為算力有限的嵌入式場景下專門設計一個高效的神經網路架構。
- 用了什麼方法解決?
- 使用了兩個新的操作:pointwise group convolution(組卷積)和channel shuffle。
- 根據這兩個操作構建了ShuffleUnit,整個ShuffleNet都是由ShuffleUnit組成。
- 效果如何?
- 在ImageNet分類和MS COCO目標檢測任務上取得了比其他輕量化模型更高的準確率,如MobileNet v1。
- 在ARM裝置上,ShuffleNet的速度比AlexNet快了13倍。
- 還存在什麼問題?
- 超引數如組卷積的組數以及通道壓縮比率等需要根據實際情況決定,不同任務下需要自行調整。
- 網路實時性並不能單純以浮點計算量來衡量,還存在memory access cost(MAC)等因素的干擾,並不能僅僅根據計算量就認為ShuffleNet是最快的。
2、論文概述
2.1、簡介
- 作者發現,一些state-of-the-art的模型架構,如Xception、ResNeXt等,使用在小型網路模型中效率都比較低。這是因為使用大量的 卷積會消耗大量計算資源。為此,提出了pointwise group convolution來減少計算複雜度。
- 使用組卷積也會帶來一些副作用,因為組卷積切斷了組內通道與組外通道之間的聯絡,僅僅能從組內通道提取特徵資訊。為此,論文中又提出了 channel shuffle,來幫助資訊在各通道之間流通。
2.2、相關工作
- 高效模型設計:
- GoogLeNet
- SqueezeNet
- ResNet
- SENet
- NASNet
- 組卷積(group convolution):
- 最初由AlexNet提出,應用在2塊GPU上並行處理。
- Xception中提出了深度可分離卷積(depthwise separable convolution)。
- MobileNet中也使用到了深度可分離卷積。
- Channel Shuffle
- 此前的文獻中較少提及channel shuffle操作。
- 模型加速
- 目標是再保證模型準確率的前提下儘可能加速前向推理過程。
- 常見方法:
- 網路剪枝。
- 量化和分解。
- 知識蒸餾。
2.3、Channel Shuffle for Group Convolutions
- 在小型網路中,逐點卷積(pointwise convolution)不僅會佔用較多計算資源並且還會讓通道之間具有過多複雜的約束,這會顯著地降低網路效能。在較大的模型中使用pointwise convolution也許相對好一些,然而小模型並不需要過多複雜的約束,否則容易導致模型難以收斂,並且容易陷入過擬合。
- 一個解決辦法是:通道間稀疏連線(channel sparse connections)。使用組卷積可以一定程度上解決這個問題。
- 但是,使用組卷積也會帶來副作用:資訊只會在組內流通,組間不會有資訊互動。為此,還需要使用channel shuffle來解決資訊不流通的問題。
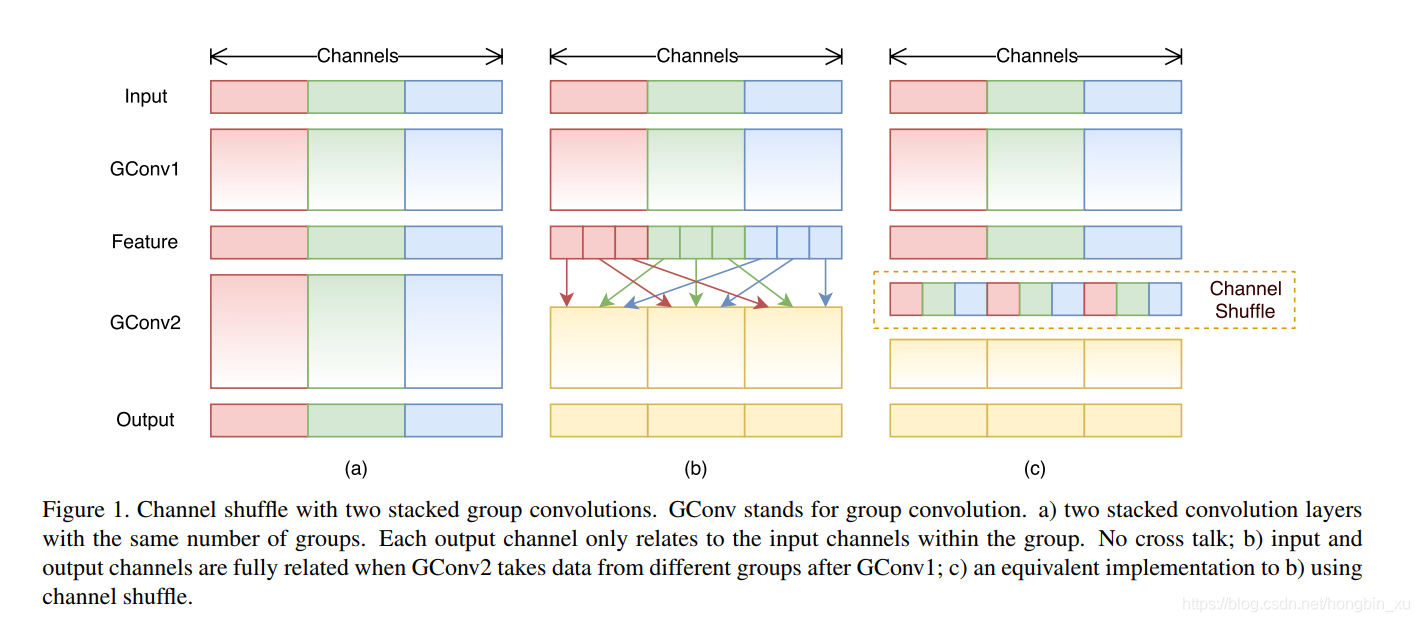
- channel shuffle操作:
- 假設一個卷積層上有 組,每組有 個通道,最後輸出就有 個通道。
- reshape成 。
- 轉置成 。
- 展開(flatten),再分成 組,作為下一層的輸入。
2.4、Shuffle Unit
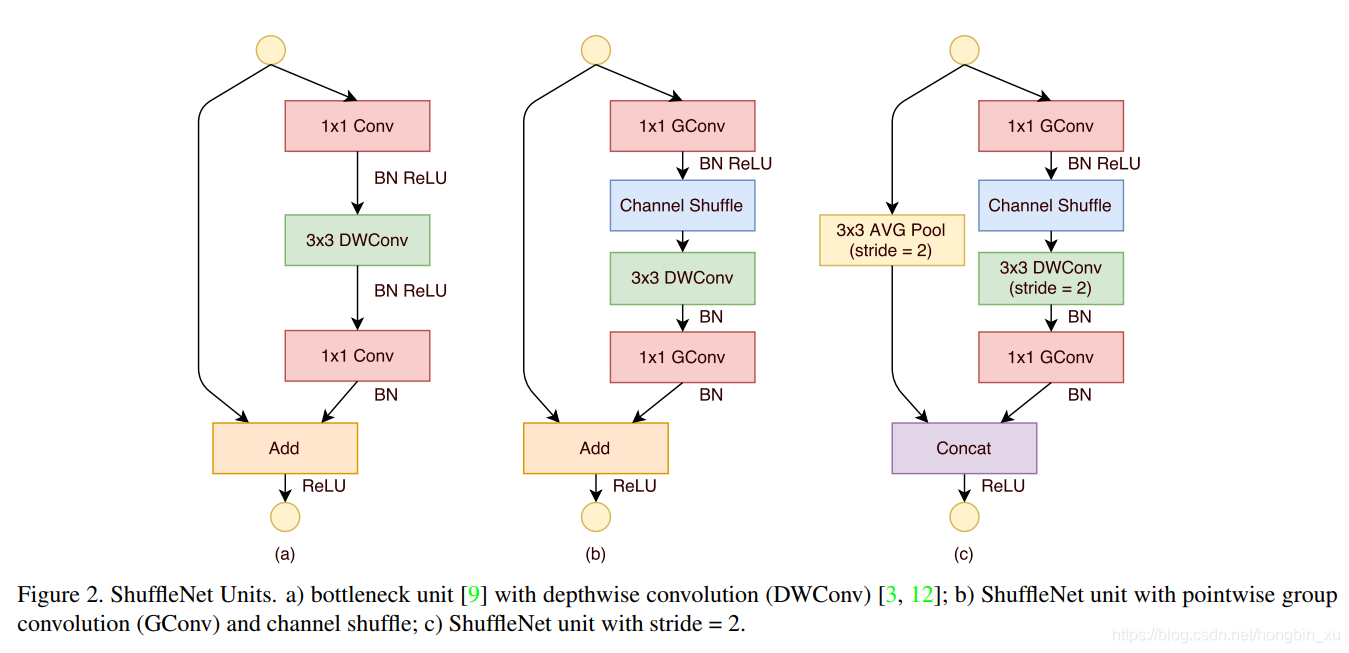
- 圖(a)是殘差卷積模組,標準 卷積轉換為深度可分離卷積與 卷積的組合。中間加上BN和ReLU,構成基本單元。
- 圖(b)是Shuffle Unit,將圖(a)中的第一個 卷積替換成 組卷積(GConv)和channel shuffle組成的單元。
- 圖©是用於降取樣的Shuffle Unit,深度可分離卷積的步長改為2,為了適配主分支的feature map,在shortcut上加上了步長也為2的平均池化(AVG Pool )。
- 雖然深度可分離卷積可以減少計算量和引數量,但在低功耗裝置上,與密集的操作相比,計算/儲存訪問的效率更差。故在ShuffleNet上只在bottleneck上有使用深度可分離卷積,儘可能的減少開銷。
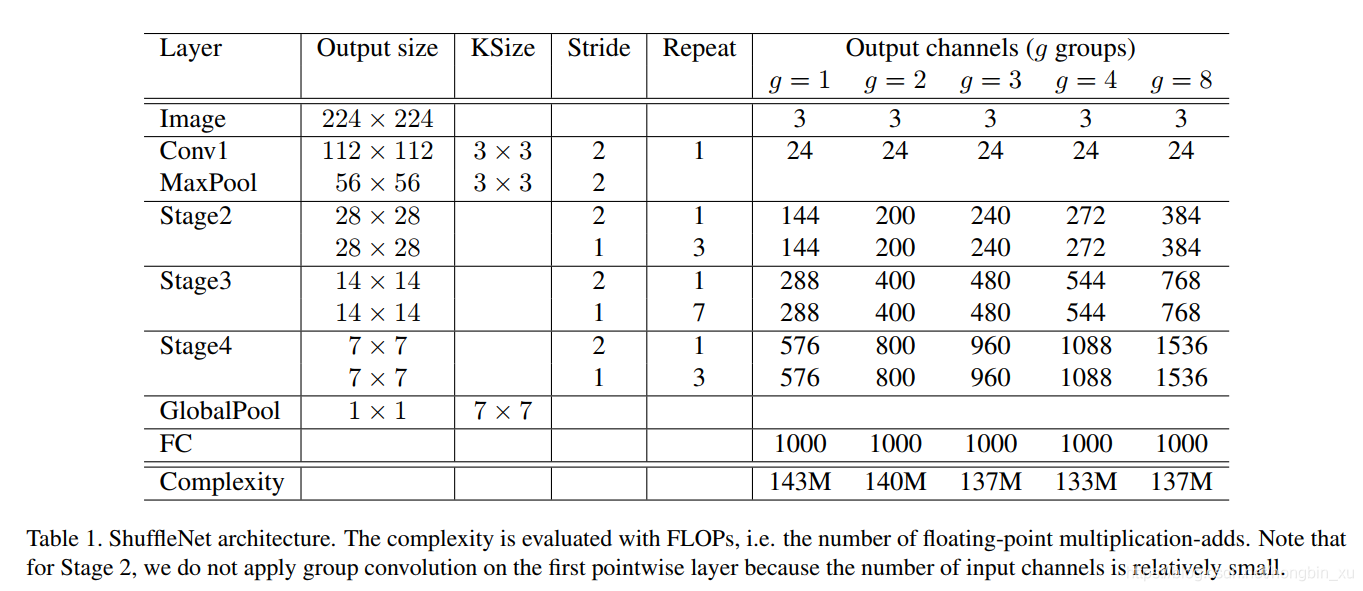
2.5、網路架構
2.6、實驗
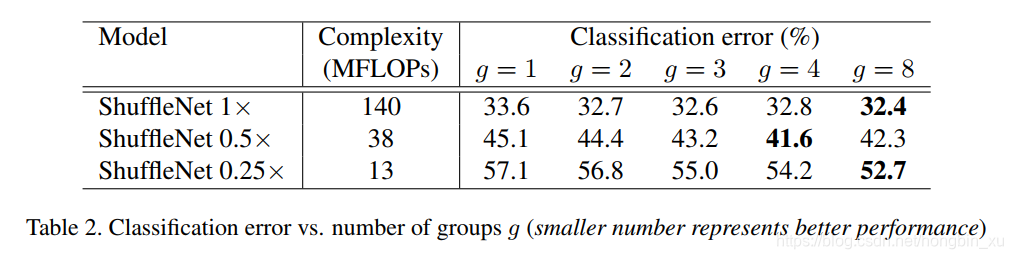
- Pointwise Group Convolutions
- 從結果來看,有組卷積的一致比沒有組卷積(g=1)的效果要好。注意組卷積可獲得更多通道間的資訊,我們假設效能提高受益於更多的feature map通道數,這也有助於我們對更多資訊進行編碼。並且,較小的模型的feature map通道也更少,這意味著能更多地從增加feature map上獲益。
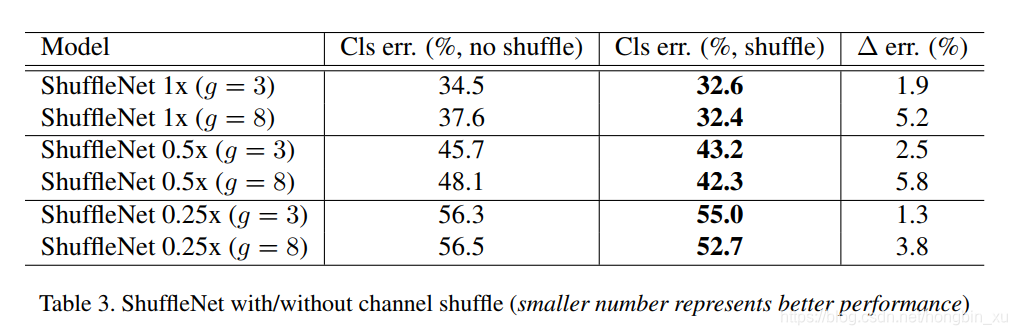
- Channel Shuffle vs. No Shuffle
- Comparison with Other Structure Units

- Comparison with MobileNets and Other Frameworks
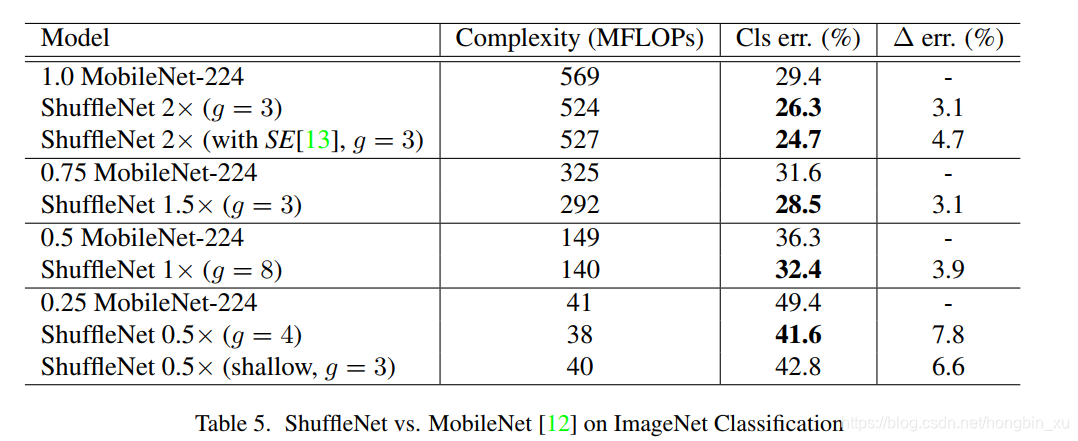
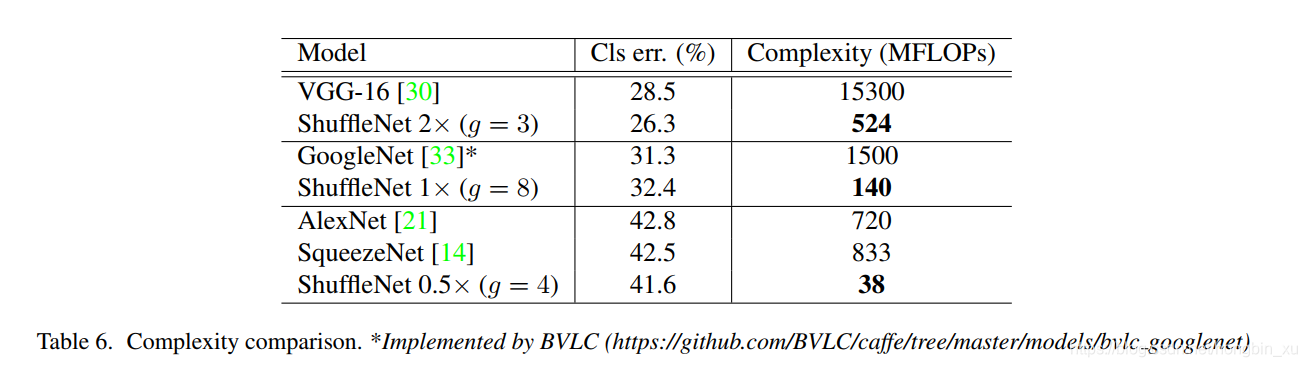
- Generalization Ability
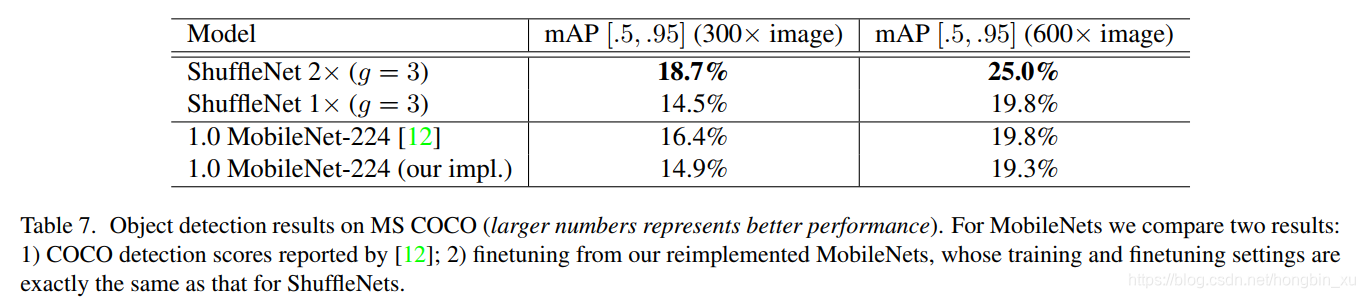
- 在MS COCO目標檢測任務上測試ShuffleNet的泛化和遷移學習能力,以Faster RCNN為例:
- Actual Speedup Evaluation