
帶你深入AI(1) - 深度學習模型訓練痛點及解決方法
系列文章,請多關注
Tensorflow原始碼解析1 – 核心架構和原始碼結構
自然語言處理1 – 分詞
帶你深入AI(1) - 深度學習模型訓練痛點及解決方法
帶你深入AI(2)- 深度學習啟用函式,準確率,優化方法等總結
帶你深入AI(3)- 物體分類領域:AlexNet VGG Inception ResNet mobileNet
帶你深入AI(4)- 目標檢測領域:R-CNN,faster R-CNN,yolo,SSD, yoloV2
帶你深入AI(5)- 自然語言處理領域:RNN LSTM GRU
帶你深入AI(6)- 詳解bazel
帶你深入AI(7)- 深度學習重要Python庫
1 模型訓練基本步驟
進入了AI領域,學習了手寫字識別等幾個demo後,就會發現深度學習模型訓練是十分關鍵和有挑戰性的。選定了網路結構後,深度學習訓練過程基本大同小異,一般分為如下幾個步驟
- 定義演算法公式,也就是神經網路的前向演算法。我們一般使用現成的網路,如inceptionV4,mobilenet等。
- 定義loss,選擇優化器,來讓loss最小
- 對資料進行迭代訓練,使loss到達最小
- 在測試集或者驗證集上對準確率進行評估
下面我們來看深度學習模型訓練中遇到的難點及如何解決
2 模型訓練難點及解決方法
2.1 收斂速度慢,訓練時間長
深度學習其實就是一個反覆調整模型引數的過程,得力於GPU等硬體效能的提升,使得複雜的深度學習訓練成為了可能。收斂速度過慢,訓練時間過長,一方面使得相同總訓練時間內的迭代次數變少,從而影響準確率,另一方面使得訓練次數變少,從而減少了嘗試不同超引數的機會。因此,加快收斂速度是一大痛點。那麼怎麼解決它呢?
2.1.1 設定合理的初始化權重w和偏置b
深度學習通過前向計算和反向傳播,不斷調整引數,來提取最優特徵,以達到預測的目的。其中調整的引數就是weight和bias,簡寫為w和b。根據奧卡姆剃刀法則,模型越簡單越好,我們以線性函式這種最簡單的表示式來提取特徵,也就是
f(x) = w * x + b
深度學習訓練時幾乎所有的工作量都是來求解神經網路中的w和b。模型訓練本質上就是調整w和b的過程,如果將他們初始化為一個合理的值,那麼就能夠加快收斂速度。怎麼初始化w和b呢?
我們一般使用截斷的正態分佈(也叫高斯分佈)來初始化w。如下
# 權重weight,標準差0.1。truncated_normal截斷的正態分佈來初始化weight。權重初始化很有講究的,會決定學習的快慢
def weight_variable(shape, vname):
initial = tf.truncated_normal(shape, stddev=0.1, name=vname)
return tf.Variable(initial)
tf.truncated_normal定義如下
tf.truncated_normal(
shape, # 正態分佈輸出資料結構,1維tensor
mean=0.0, # 平均值,預設為0.我們一般取預設值0
stddev=1.0, # 標準差
dtype=tf.float32, # 輸出資料型別
seed=None, # 隨機分佈都會有一個seed來決定分佈
name=None
)
什麼叫截斷的正態分佈呢,看下圖就明白了
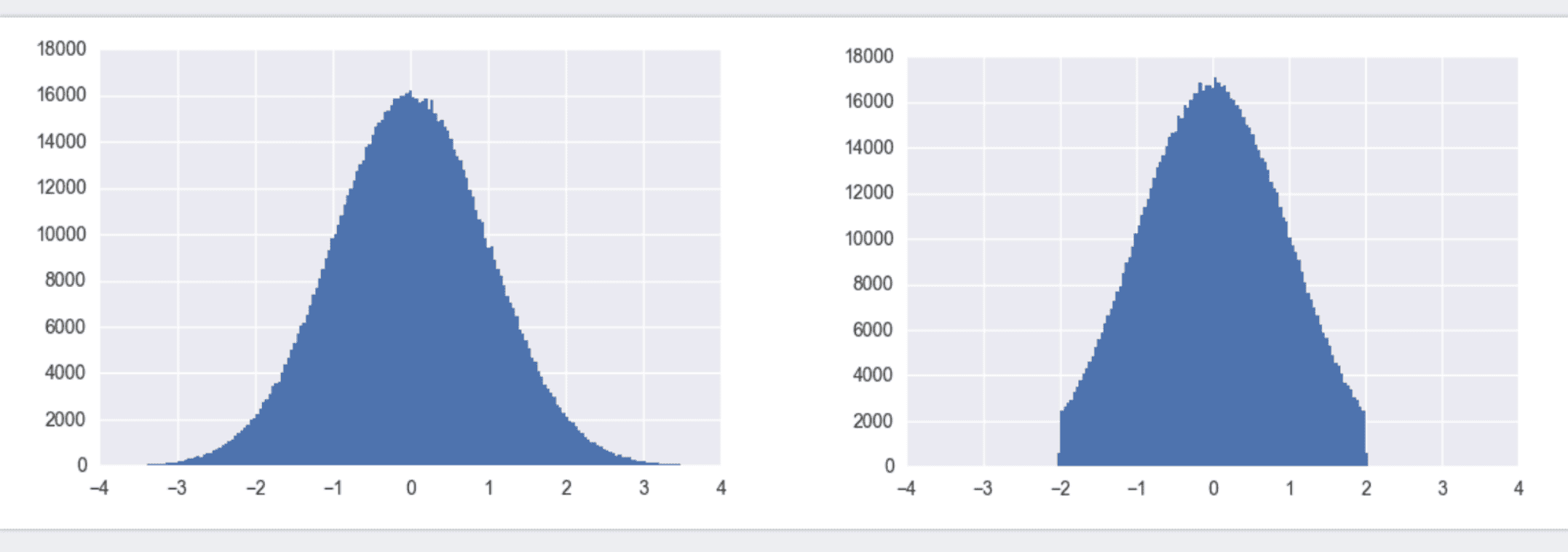
左圖為標準正態分佈,也叫高斯分佈,利用TensorFlow中的tf.random_normal()即可得到x取值範圍負無窮到正無窮內的值。所有的y值加起來概率為1。初始化w時,我們沒必要將w初始化為很大或很小的數。故更傾向於使用截斷正態分佈,如右圖。它和標準正態分佈的區別在於,限制了x取值必須在[-2 x stddev, 2 x stddev]之間。
b由於是加和關係,對收斂速度影響不大。我們一般將它初始化為0,如下。
# 偏置量bias,初始化為0,偏置可直接使用常量初始化
def bias_variable(shape, vname):
initial = tf.constant(0, shape=shape, name=vname)
return tf.Variable(initial)
2.1.2 優化學習率
模型訓練就是不斷嘗試和調整不同的w和b,那麼每次調整的幅度是多少呢,這個就是學習率。w和b是在一定範圍內調整的,那麼增大學習率不就減少了迭代次數,也就加快了訓練速度了嗎?路雖長,步子邁大點不就行了嗎?非也,步子邁大了可是會扯到蛋的!深度學習中也是如此,學習率太小,會增加迭代次數,加大訓練時間。但學習率太大,容易越過區域性最優點,降低準確率。
那有沒有兩全的解決方法呢,有!我們可以一開始學習率大一些,從而加速收斂。訓練後期學習率小一點,從而穩定的落入區域性最優解。使用Adam,Adagrad等自適應優化演算法,就可以實現學習率的自適應調整,從而保證準確率的同時加快收斂速度。
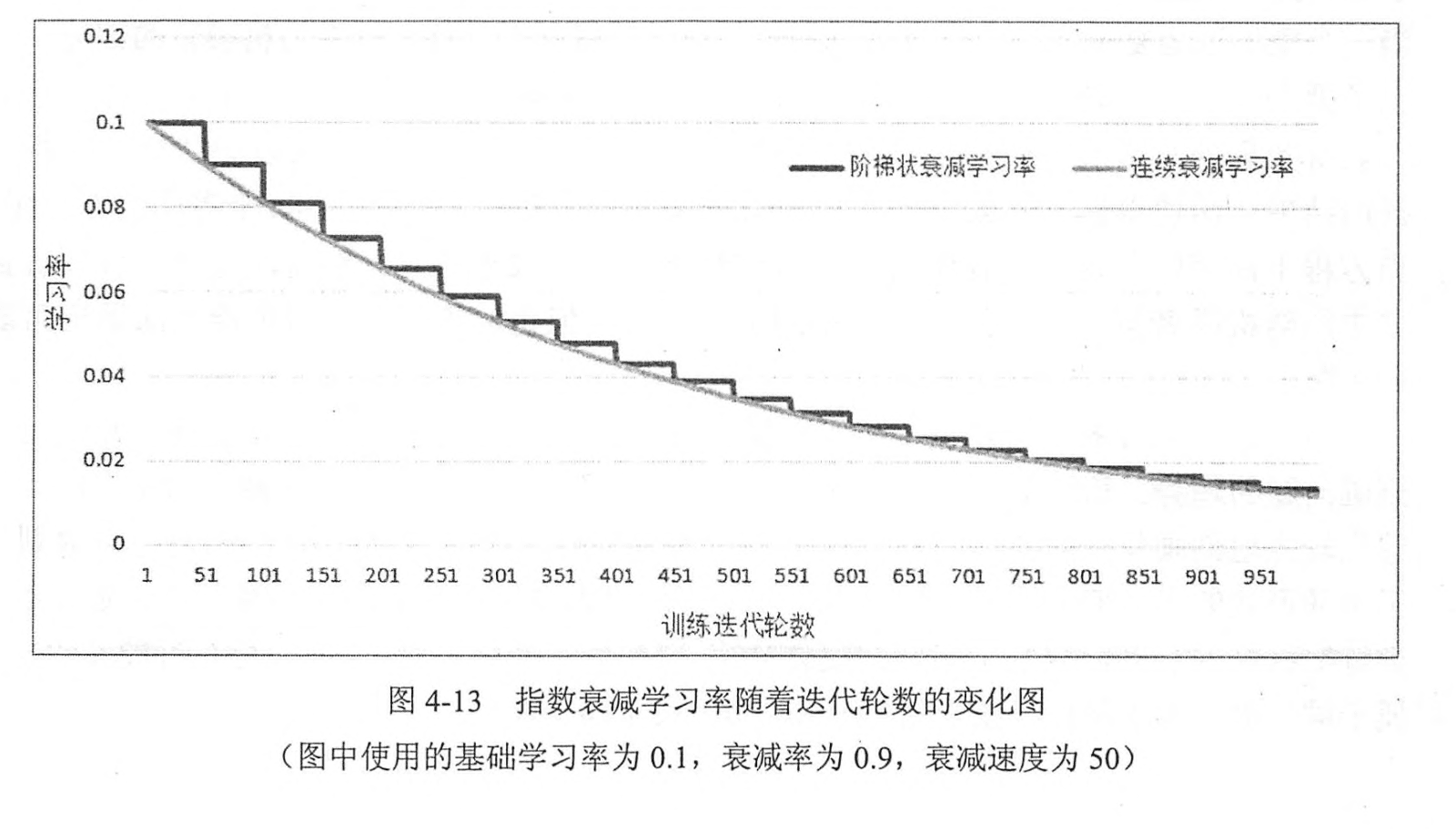
如上圖所示,隨著迭代次數的增加,學習率從0.1逐步衰減為0.02以下。
2.1.3 網路節點輸入值正則化 batch normalization
神經網路訓練時,每一層的輸入分佈都在變化。不論輸入值大還是小,我們的學習率都是相同的,這顯然是很浪費效率的。而且當輸入值很小時,為了保證對它的精細調整,學習率不能設定太大。那有沒有辦法讓輸入值標準化得落到某一個範圍內,比如[0, 1]之間呢,這樣我們就再也不必為太小的輸入值而發愁了。
辦法當然是有的,那就是正則化!由於我們學習的是輸入的特徵分佈,而不是它的絕對值,故可以對每一個mini-batch資料內部進行標準化,使他們規範化到[0, 1]內。這就是Batch Normalization,簡稱BN。由大名鼎鼎的inception V2提出。它在每個卷積層後,使用一個BN層,從而使得學習率可以設定為一個較大的值。使用了BN的inceptionV2,只需要以前的1/14的迭代次數就可以達到之前的準確率,大大加快了收斂速度。
2.1.4 採用更先進的網路結構,減少引數量
訓練速度慢,歸根結底還是網路結構的引數量過多導致的。減少引數量,可以大大加快收斂速度。採用先進的網路結構,可以用更少的引數量達到更高的精度。如inceptionV1引數量僅僅為500萬,是AlexNet的1/12, 但top-5準確率卻提高了一倍多。如何使用較少的引數量達到更高的精度,一直是神經網路結構研究中的難點。目前大致有如下幾種方式
- 使用小卷積核來代替大卷積核。VGGNet全部使用3x3的小卷積核,來代替AlexNet中11x11和5x5等大卷積核。小卷積核雖然引數量較少,但也會帶來特徵面積捕獲過小的問題。inception net認為越往後的卷積層,應該捕獲更多更高階的抽象特徵。因此它在靠後的卷積層中使用的5x5等大面積的卷積核的比率較高,而在前面幾層卷積中,更多使用的是1x1和3x3的卷積核。
- 使用兩個串聯小卷積核來代替一個大卷積核。inceptionV2中創造性的提出了兩個3x3的卷積核代替一個5x5的卷積核。在效果相同的情況下,引數量僅為原先的3x3x2 / 5x5 = 18/25
- 1x1卷積核的使用。1x1的卷積核可以說是價效比最高的卷積了,沒有之一。它在引數量為1的情況下,同樣能夠提供線性變換,relu啟用,輸入輸出channel變換等功能。VGGNet創造性的提出了1x1的卷積核
- 非對稱卷積核的使用。inceptionV3中將一個7x7的卷積拆分成了一個1x7和一個7x1, 卷積效果相同的情況下,大大減少了引數量,同時還提高了卷積的多樣性。
- depthwise卷積的使用。mobileNet中將一個3x3的卷積拆分成了串聯的一個3x3 depthwise卷積和一個1x1正常卷積。對於輸入channel為M,輸出為N的卷積,正常情況下,每個輸出channel均需要M個卷積核對輸入的每個channel進行卷積,併疊加。也就是需要MxN個卷積核。而在depthwise卷積中,輸出channel和輸入相同,每個輸入channel僅需要一個卷積核。而將channel變換的工作交給了1x1的卷積。這個方法在引數量減少到之前1/9的情況下,精度仍然能達到80%。
- 全域性平均池化代替全連線層。這個才是大殺器!AlexNet和VGGNet中,全連線層幾乎佔據了90%的引數量。inceptionV1創造性的使用全域性平均池化來代替最後的全連線層,使得其在網路結構更深的情況下(22層,AlexNet僅8層),引數量只有500萬,僅為AlexNet的1/12
網路結構的推陳出新,先進設計思想的不斷提出,使得減少引數量的同時提高準確度變為了現實。引數量的減少,一方面加快了收斂速度,減少了訓練時間,另一方面減小了模型體積,另外還能加快預測時間,提高實時性。所以一直以來減少引數量都是一個十分重要的議題
2.1.5 使用GPU平行計算
深度學習模型訓練,基本由卷積計算和矩陣乘法構成,他們都很適合平行計算。使用多塊GPU並行加速已經成為了深度學習的主流,可以大大加快收斂速度。要達到相同的精度,50塊GPU需要的時間僅為10塊的1/4左右。當前Google早已開始了TPU這種專門用於深度學習的Asic晶片的研究,國內的寒武紀等公司也在大張旗鼓的研究專用於AI的晶片。AI晶片的前景也是十分廣闊的。
2.2 線性模型的侷限性
根據奧卡姆剃刀法則,我們使用了最簡單的線性模型,也就是wx+b,來表徵了神經網路。線性模型的特點是,任意線性模型的組合仍然是線性模型。不論我們採用如何複雜的神經網路,它仍然是一個線性模型。然而線性模型能夠解決的問題畢竟是有限的,所以必須在神經網路中增加一些非線性元素。
2.2.1 啟用函式的使用
在每個卷積後,加入一個啟用函式,已經是通用的做法,相信大家都知道。啟用函式,如relu,tanh,sigmod都是非線性函式,一方面可以增加模型的非線性元素,另一方面可以降低梯度彌散問題(我們後面詳細講解)。目前使用較多的就是relu函式。他模擬了生物學上的閾值響應機制,利用人腦只對大於某個值的訊號才產生響應的機制,提出了單側抑制的理念。它的表示式很簡單,f(x)=max(0,x)。當x>0時,y=x, x<0時,y=0. 如下圖所示。

相比於tanh和sigmod,relu的優點有:
- 計算速度快,容易收斂。relu就是一個取max的函式,沒有複雜的運算,故計算速度很快。相比於tanh,收斂速度可加快6倍
- 梯度不會大幅縮小。x>0時,relu的梯度為1(梯度還不懂是啥意思的同學最好翻下數學書,梯度簡單理解就是偏導數),故相比sigmod這種x稍微遠離0,梯度就會大幅減小的函式,不會使得梯度縮小,從而引發多層傳播後的梯度彌散問題。
2.2.2 兩個小卷積核的疊加代替一個大卷積核
啟用函式可是一個增加非線性的大法寶,但我們一般只能在卷積完之後再使用它。那怎麼增加它的使用場景呢?增加捲積層不就行了嗎。inception V2創造性的提出了用兩個3x3的卷積核代替一個5x5的卷積核。每次卷積後,都使用一次relu非線性啟用。如下圖。

2.2.3 1x1小卷積核的使用
1x1的卷積核應該是價效比最高的卷積,它在引數量為1的情況下,同樣能夠提供線性變換,relu啟用,輸入輸出channel變換等功能。inceptionV1利用Network in Network的思想,提出了inception module這一結構,它在每個並行分支的最前面,使用了一個1x1的卷積,卷積後緊跟一個relu啟用。從而大大增加了relu的使用率。從而提高了模型的非線性特徵。
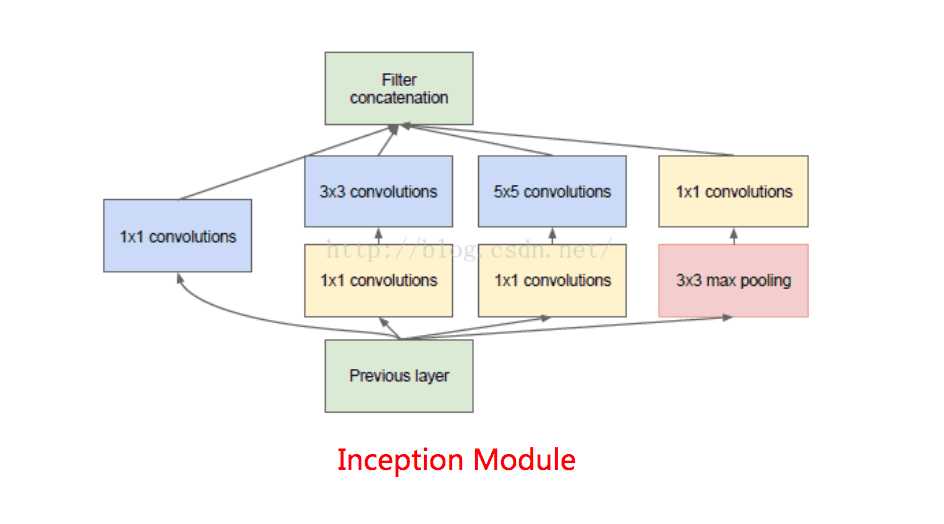
2.3 過擬合問題
過擬合在機器學習中廣泛存在,指的是經過一定次數的迭代後,模型準確度在訓練集上越來越好,但在測試集上卻越來越差。究其原因,就是模型學習了太多無關特徵,將這些特徵認為是目標所應該具備的特徵。如下圖
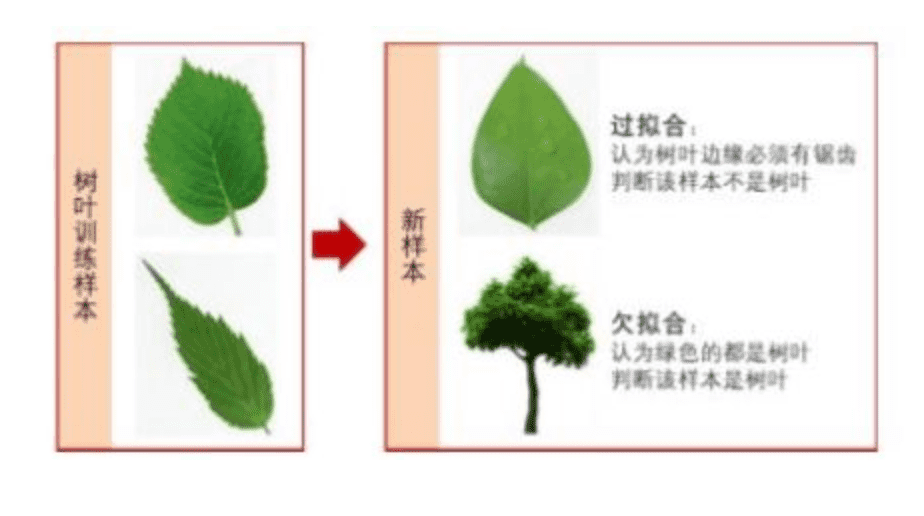
如上圖所示,樹葉訓練樣本中邊緣帶有鋸齒,模型學習了鋸齒這一特徵,認為樹葉必須帶有鋸齒,從而判定右側的不帶鋸齒的樹葉不是樹葉。這就是典型的過擬合問題。神經網路中,因為引數眾多,經常出現引數比輸入樣本資料還多的情況,這就導致很容易出現模型只記住了訓練集特徵的情況。我們有兩個思路來解決這個問題。一是增大樣本量,另外就是減少特徵量。
2.3.1 輸入增強,增大樣本量
收集更多且更全的樣本,能有效降低過擬合。但尋找樣本本來就是一件很費力的事情,我們到哪兒去尋找更多更全的樣本呢。素材整理和資料獲取成為了深度學習的一大瓶頸,否則再牛逼的神經網路結構,也會稱為無米之炊。這也是當前遷移學習變得比較火熱的一大原因(這是後話,就不詳細展開了)。那我們有沒有辦法簡單快捷的增加樣本量呢?
答案是有的,可以使用輸入增強方法。對樣本進行旋轉,裁剪,加入隨機噪聲等方式,可以大大增加樣本數量和泛化性。目前TensorFlow就提供了大量方法進行資料增強,大大方便了我們增加樣本數量。
2.3.2 dropout,減少特徵量
使用dropout,將神經網路某一層的輸出節點資料隨機丟棄,從而減少特徵量。這其實相當於創造了很多新的隨機樣本。我們可以理解為這是對特徵的一次取樣。一般在神經網路的全連線層使用dropout。
2.4 梯度彌散, 無法使用更深的網路
深度學習利用正向傳播來提取特徵,同時利用反向傳播來調整引數。反向傳播中梯度值逐漸減小,神經網路層數較多時,傳播到前面幾層時,梯度接近於0,無法對引數做出指導性調整了,此時基本起不到訓練作用。這就稱為梯度彌散。梯度彌散使得模型網路深度不能太大,但我們都知道網路越深,提取的特徵越高階,泛化性越好。因此優化梯度彌散問題就很重要了
2.4.1 relu代替sigmoid啟用函式
sigmoid函式值在[0,1],ReLU函式值在[0,+無窮]。relu函式,x>0時的導數為1, 而sigmoid函式,當x稍微遠離0,梯度就會大幅減小,幾乎接近於0,所以在反向傳播中無法指導引數更新。
2.4.2 殘差網路
大名鼎鼎的resNet將一部分輸入值不經過正向傳播網路,而直接作用到輸出中。這樣可以提高原始資訊的完整性了,從而在反向傳播中,可以指導前面幾層的引數的調整了。如下圖所示。
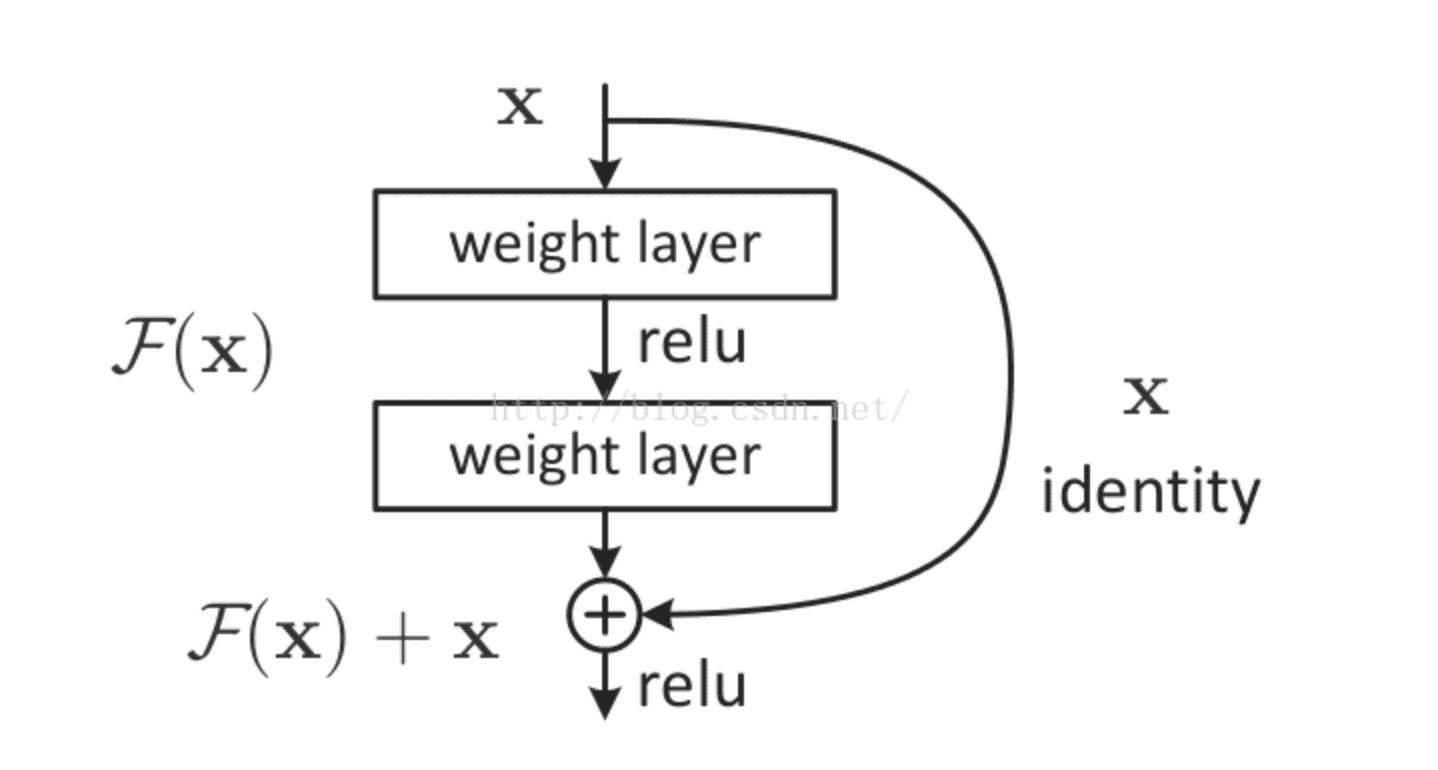
使用了殘差網路的resNet,將網路深度提高到了152層,大大提高了模型的泛化性,從而提高了預測準確率,並一舉問鼎當年的imageNet冠軍!
3 總結
深度學習模型訓練是一個很費時間,但也很有技巧的過程。模型訓練中有梯度彌散,過擬合等各種痛點,正是為了解決這些問題,不斷湧現出了各種設計精巧的網路結構。學習時,我們不僅要學習網路結構的設計方式,還要掌握它們的設計思想,瞭解它們是為了解決哪些問題而產生的,以及準確率和效能為何能夠得到提升。
系列文章,請多關注
Tensorflow原始碼解析1 – 核心架構和原始碼結構
自然語言處理1 – 分詞
帶你深入AI(1) - 深度學習模型訓練痛點及解決方法
帶你深入AI(2)- 深度學習啟用函式,準確率,優化方法等總結
帶你深入AI(3)- 物體分類領域:AlexNet VGG Inception ResNet mobileNet
帶你深入AI(4)- 目標檢測領域:R-CNN,faster R-CNN,yolo,SSD, yoloV2
帶你深入AI(5)- 自然語言處理領域:RNN LSTM GRU
帶你深入AI(6)- 詳解bazel
帶你深入AI(7)- 深度學習重要Python庫